







TCP的超时与重传
引言
TCP提供可靠的运输层。它使用的方法之一就是确认从另一端收到的数据。但数据和确认都有可能会丢失。TCP通过在发送时设置一个定时器来解决这种问题。如果当定时器溢出时还没有收到确认,它就重传该数据。对于任何实现而言,关键之处就在于超时和重传的策略,即怎么决定超时时间和如何确定重传的频率
对每个连接,TCP管理4个不同的定时器.
- 重传定时器使用于当希望收到另一端的确认。本章详细介绍这个定时器以及避免拥塞
- 坚持(persist)定时器使窗口大小信息不断流动,即使另一端关闭了其接;收窗口,第22章将讨论这个问题
- 保活(keepalive)定时器可以检测到一个空闲连接的另一端合适崩溃或重启。第23章将描述这个定时器
- 2MSL定时器测量一个连接处于TIME_WAIT状态的时间。
本章介绍TCP怎么测量往返时间以及TCP如何使用这些测量结果来为下一个将要传输的报文段建立重传超时时间。
还有TCP的拥塞避免、分组丢失时TCP所采取的动作。还将介绍快速重传和快速恢复算法,TCP检测分组丢失比等待时钟超时更快。
超时与重传的简单例子
观察TCP使用的重传机制。
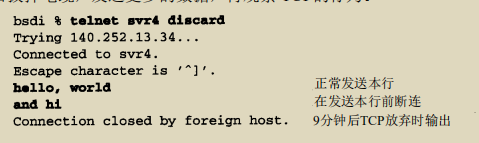

- 第1、2和3行是正常的TCP连接建立的过程。第4行是“hello,world”的传输过程,第5行是其确认。第6行表示“and hi”将被发送。第7~18行是这个报文段的12次重传过程,而第19行则是发送方的TCP最终放弃并发送一个复位信号的过程。
- 检查连续重传之间不同的时间差,它们去整后分别为1、3、6、12、24、48和多个64秒。我们将在第一次发送后设置的超时时间实际上为1.5秒(但是第一个500ms是不精确的)
- 这个倍乘关系称为“指数退避(exponential backoff)”
- 首次分组传输与复位信号传输之间的时间差约为9分钟,该时间在目前的TCP实现中是不可变的。
往返时间测量
TCP超时与重传中最重要的部分就是对一个给定连接的往返时间(RTT)的测量。由于路由器和网络流量均会变化,因此我们认为这个时间可能经常会发送变化,TCP跟踪这些变化并相应地改变其超时时间。
M标志所测量到的RTT。
最初的TCP规范使TCP使用低通过滤器来更新一个被平滑的RTT估计器(记为O)。 R<-aR+(1-a)M
这里的a是一个推荐值为0.9的平滑因子。每次进行新测量的时候,这个被平滑的RTT将得到更新。每个新估计的90%来自前一个估计,而10%则取自新的测量。
该算法在给定这个随RTT的变化而变化的平滑因子的条件下,RFC推荐的重传超时时间RTO(Retransmission TimeOut)的值应该设置为
RTO=Rb
这里的b是一个推荐值为2的时延离散因子的
[Jacobson 1988]详细分析了在RTT变化范围很大时,使用这个方法无法跟上这种变化,从而引起不必要的重传。推荐使用平滑的RTT估计器和跟踪RTT的方差。在往返时间变化起伏很大时,基于均值和方差来计算RTO,将比作为均值的常数倍数来计算RTO能提供更好的响应。
均值偏差是对标准偏差的一种好的逼近,但却更容易进行计算(标准差是对方差取根号)。
Err=M-A
A<-A+gErr
D<-D+h(|Err|-D)
RTO=A+4D
A是被平滑的RTT,D是被平滑的均值偏差。Err是刚得到的测量结果与当前RTT之差。A和D用于计算下一个重传时间。增量g起平均作用,取1/8。偏差的增益是h,取值为0.25.当RTT变化时,较大的偏差增益将使RTO快速上升
往返时间RTT的例子

使用sock程序,该命令执行32个写1024字节的操作,由于slip和bsdi之间的MTU是296字节,所以会产生128个报文段,每个报文段包含256字节的用户数据。
往返时间RTT的测量

在每次调用 500 ms的T C P的定时器例程时,就增加一个计数器来完成计时。这意味着,
如果一个报文段的确认在它发送 550 ms后到达,则该报文段的往返时间 RT T将是1个滴答(即
500 ms)或是2个滴答(即1000 ms)。
对每个连接而言,除了这个滴答计数器,报文段中数据的起始序号也被记录下来。当收
到一个包含这个序号的确认后,该定时器就被关闭。如果 A C K到达时数据没有被重传,则被
平滑的RT T和被平滑的均值偏差将基于这个新测量进行更新。

给定连接的定时器已经被使用,则该报文段不被计时
假定第1个滴答发生在0.03秒处。也能看出去为啥第2个被测量的RTT标记为1个滴答。

在时间10,14和21处的间隔是由在这些时刻附近发生的重传引起的。Karn算法在另一个报文段被发送和确认之前阻止更新估计器。同样注意到这个实现中,TCP计算的RTO总是500ms的倍数
拥塞举例

- 可以看到报文段45丢失,导致后续报文都ACK了45报文段。但是tcp是在接收到第三个重复的ACK才进行重传。的确源于伯克利的TCP实现对收到的重复ACK进行计数,当收到第三个时,就假定一个报文段已经丢失并重传自那个序号起的一个报文段。这就是jacobson的快速重传算法,该算法通常与他的快速恢复算法一起配合使用。
- 注意到重传后,发送方继续正常的数据传输。TCP不需要等待对方确认重传
- TCP无法告诉对方缺少一个报文段,无法确认失序数据,只能发送下一个序号的ACK
- 当缺少报文段接收到时,会把报文段联通缓存的数据一起发送给应用程序,并返回响应的窗口通告
拥塞避免算法
- 慢启动算法是在一个连接上发起数据流的方法,但有时我们会达到中间路由器的极限,此时分组将被丢弃。
拥塞避免算法是一种处理丢失分组的方法- 该算法假定由于分组受到损坏引起的丢失时非常少的,因此分组丢失就意味着在源主机和目的主机之间的某处网络上发生了拥塞。有两种分组丢失的指示:发生超时和接收到重复的确认(RTT和拥塞举例中看到过)
- 拥塞避免算法和慢启动算法是两个目的不同、独立的算法。但当拥塞发送时,可以调用慢启动来降低分组进入网络的传输速率。
- 拥塞避免算法和慢启动算法需要对每个连接维持两个变量:cwnd和ssthresh
算法的工作过程
- 对一个给定的连接,初始化cwnd(可以理解为窗口大小)为一个报文段,ssthresh为65535个字节
- tcp输出例程的输出不能超过cwnd和接收方通告窗口的大小。拥塞避免是发送方使用的流量控制,而通告窗口则是接收方进行的流量控制。前者是发送方感受到的网络拥塞的估计,后者与接收方在该连接上的缓存有关
- 当拥塞发生时(超时或收到重复确认),ssthresh被设置为当前窗口大小的一半(取这cwnd和接收方通告窗口大小两者中偏小的值,但最少为2个报文段)。此外,如果是超时引起了拥塞,则cwnd被设置为1个报文段(这就是慢启动)
- 当新的数据被对方确认时,就增加cwnd,但增加的方法依赖于我们是否正在进行慢启动或拥塞避免(这俩是一个概念)。如果cwnd小于或等于ssthresh,则正在进行慢启动,正在进行拥塞避免。慢启动一直持续到ssthresh值才停止,然后转为执行拥塞避免
慢启动算法初始设置cwnd为一个报文段,此后每收到一个确认就加1.这有会使窗口按指数方式增长。
拥塞避免算法要求每次收到一个确认时将cwnd增加1/cwnd。这是一种加性增长。

快速重传与快速恢复算法
由于不知道一个重复的ACK是由一个丢失的报文段引起的,还是仅仅出现了几个报文段的重新排序。在TCP的实现中,认为3个以下的重复ACK是失序导致的,不予处理,当收到三个重复的ACK时,认为该报文段丢失。
于是我们就重传丢失的数据报文段,而无需等待超时定时器溢出,这就是快速重传算法。接下来执行的不是慢启动算法而是拥塞避免算法。这就是快速恢复算法
拥塞避免算法通常实现的过程。
- 收到三个重复的ACK时,将ssthresh设置为当前拥塞窗口cwnd的一半。重传丢失的报文段。设置cwnd为ssthresh加上3倍的报文段大小
- 每次收到另一个重复的ACK时,cwnd增加1个报文段大小并发送1个分组(如果新的cwnd允许发送)
- 当下一个确认新数据的ACK到达时,设置cwnd为ssthresh(第一步中设置的值)。这个ACK应该是在进行重传后的一个往返时间内对步骤1中重传的确认。另外,这个ACK也应该是对丢失的分组和收到的第一个重复的ACK之间的所有中间报文段的确认。这一步采用的是拥塞避免,因为当分组丢失时我们将当前的速率减半。















 1481
1481











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









