







1、MapReduce概述
MapReduce作为一种分布式运算技术,最先由Google提出的分布式计算软件构架,是云计算的核心技术,也是简化的分布式编程模式。它用于大规模数据集(大于1TB)的并行运算,用来处理大量数据的分布式运算。
2、MapReduce思想
MapReduce思想主要体现在Map(映射)和Reduce(化简),Map就是将一个任务分解成为多个任务,Reduce就是将分解后多任务处理的结果汇总起来,得出最后的分析结果。这不是什么新思想,其实很多技术如多线程也用的这种思想。
3、MapReduce 工作流程
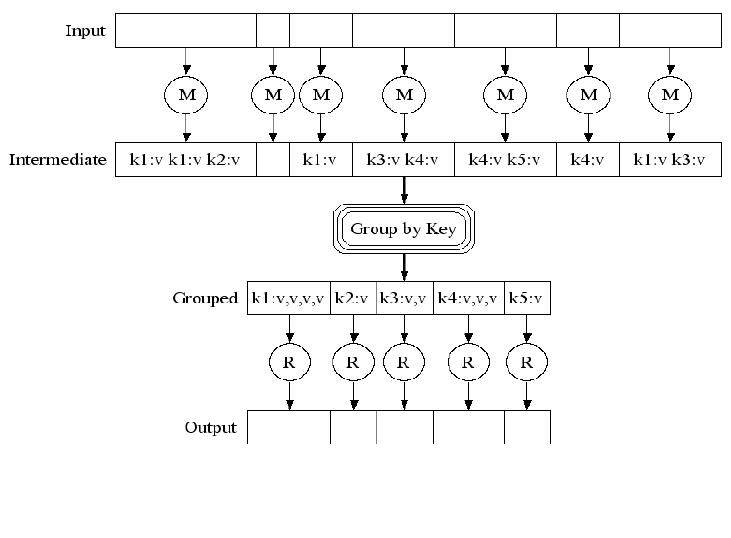
4 、实现示例
WordCount示例,这也是Hadoop自带的一个例子,目标是统计文本文件中单词的个数。
假设有如下的两个文本文件来运行WorkCount程序:
| Hello World Bye World |
| Hello Hadoop GoodBye Hadoop |
1) map数据输入
Hadoop针对文本文件缺省使用LineRecordReader类来实现读取,一行一个key/value对,key取偏移量,value为行内容。
如下是map1的输入数据:
| Key1 | Value1 |
| 0 | Hello World Bye World |
如下是map2的输入数据:
| Key1 | Value1 |
| 0 | Hello Hadoop GoodBye Hadoop |
2) map输出
如下是map1的输出结果
| Key2 | Value2 |
| Hello | 1 |
| World | 1 |
| Bye | 1 |
| World | 1 |
如下是map2的输出结果
| Key2 | Value2 |
| Hello | 1 |
| Hadoop | 1 |
| GoodBye | 1 |
| Hadoop | 1 |
Combiner类实现将相同key的值合并起来,它也是一个Reducer的实现。
如下是combine1的输出
| Key2 | Value2 |
| Hello | 1 |
| World | 2 |
| Bye | 1 |
如下是combine2的输出
| Key2 | Value2 |
| Hello | 1 |
| Hadoop | 2 |
| GoodBye | 1 |
Reducer类实现将相同key的值合并起来。
如下是reduce的输出
| Key2 | Value2 |
| Hello | 2 |
| World | 2 |
| Bye | 1 |
| Hadoop | 2 |
| GoodBye | 1 |
即实现了WordCount的处理。















 1432
1432

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









