







直接上代码和运行结果
#by suwenhao
#QQ 2487872782
import urllib
import urllib2
import re
page = 1
url = 'http://www.qiushibaike.com/hot/page/' + str(page)
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = { 'User-Agent' : user_agent }
request = urllib2.Request(url,headers = headers)
response = urllib2.urlopen(request)
content = response.read().decode('utf-8')
pattern = re.compile('<div class="content">(.*?)</div>',re.S)
items = re.findall(pattern,content)
for item in items:
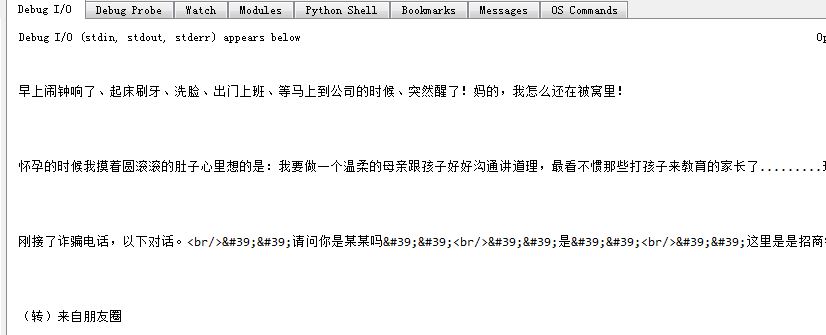
print item运行结果如下图所示:
















 112
112

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









