







 本文介绍了Python网页爬虫中XPath的使用,包括安装lxml库、通过XPath获取网页元素及属性、基本的XPath语法,并给出了通过Chrome获取元素XPath的方法。示例展示了如何利用XPath提取网页列表内容和链接。
本文介绍了Python网页爬虫中XPath的使用,包括安装lxml库、通过XPath获取网页元素及属性、基本的XPath语法,并给出了通过Chrome获取元素XPath的方法。示例展示了如何利用XPath提取网页列表内容和链接。
网页爬虫可以使用Python的正则模块(re), 当然我今天要隆重推荐的是xpath.
xpath需要安装xpath的基础包:lxml
首先看一个例子:(爬取果壳的最新推荐文章列表)
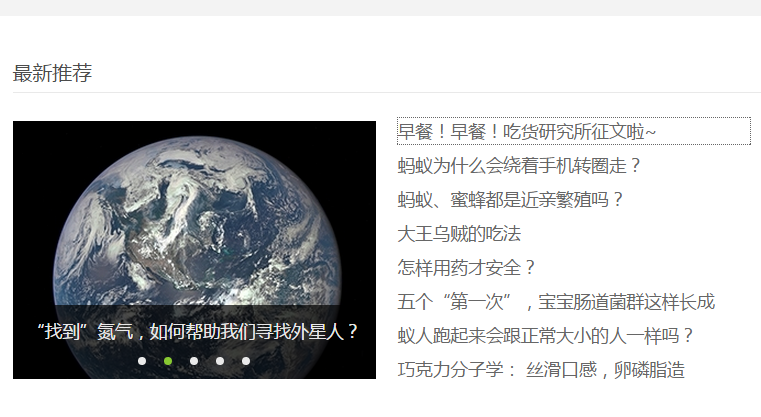
import requests
from lxml import etree
url = 'http://www.guokr.com/'
page = requests.get(url).content
s = etree.HTML(page)
h = s.xpath('/html/body/div[1]/div[2]/div[1]/div[2]/div[2]/ul/li/h2/a/text()')
for i in h:
print i输出结果是:
早餐!早餐!
蚂蚁为什么会绕着手机转圈走?
蚂蚁、蜜蜂都是近亲繁殖吗?
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 974
974

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









