







 谷歌的人工智能聊天机器人Meena通过更大规模的训练和进化变压器架构展示了更自然的对话能力,特别是在SSA评估中超越现有聊天机器人。研究团队将继续优化模型性能和特性,如个性和事实性,同时关注模型安全和偏见问题。
谷歌的人工智能聊天机器人Meena通过更大规模的训练和进化变压器架构展示了更自然的对话能力,特别是在SSA评估中超越现有聊天机器人。研究团队将继续优化模型性能和特性,如个性和事实性,同时关注模型安全和偏见问题。
人工智能驱动的聊天机器人已被寻求简化客户服务、提高生产力和增加收入的企业广泛采用。在电子商务平台上,聊天机器人可以将客户引导至推荐的产品,跟踪订单,解释如何打印退货运输标签等。
然而,这样的聊天机器人在脱靶或无关紧要的谈话方面做得并不好——例如,如果被要求评论最新的艺术或时尚趋势。“Meena”,谷歌人工智能的新生成聊天机器人,对此有一两句话要说。
作为新型开放域聊天机器人之一,Meena旨在参与任何主题的对话,其自由和自然的对话能力正在缩小人类表现的差距。
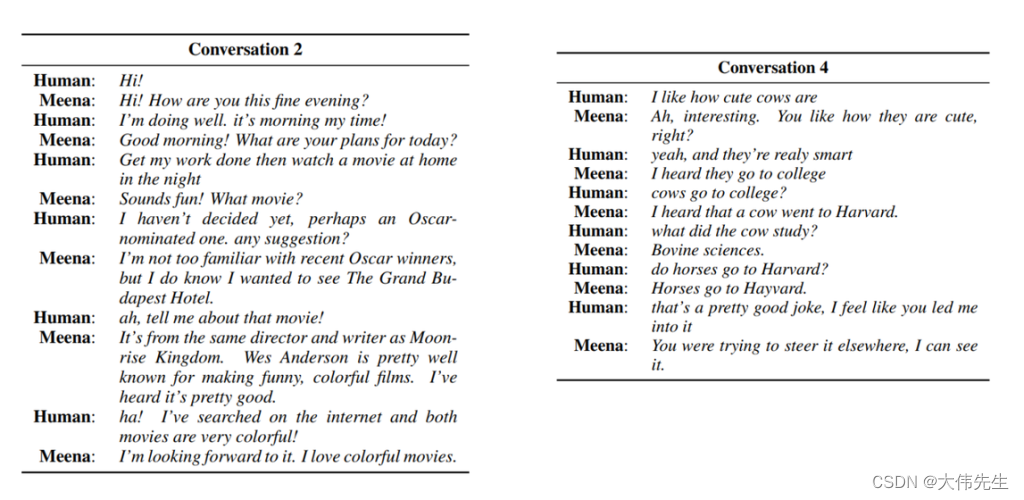
米娜与人类的对话
在Google AI最近的论文《走向类人开放域聊天机器人》中介绍,Meena的主要架构是带有进化变压器的seq2seq模型。它经过了从公共领域社交媒体对话中挖掘和过滤的341GB文本(40B单词)的训练。与OpenAI的语言模型GPT-2相比,Meena的模型容量大1.7倍,并且训练的数据增加了8倍。
根据研究团队的说法,最好的Meena模型具有2.6B参数,并根据10K BPE子词的词汇量实现了2.8的测试困惑度。
根据研究团队的说法,最佳Meena模型的参数为2.6B,基于8K个BPE子词的词汇表,测试困惑度为10.2。
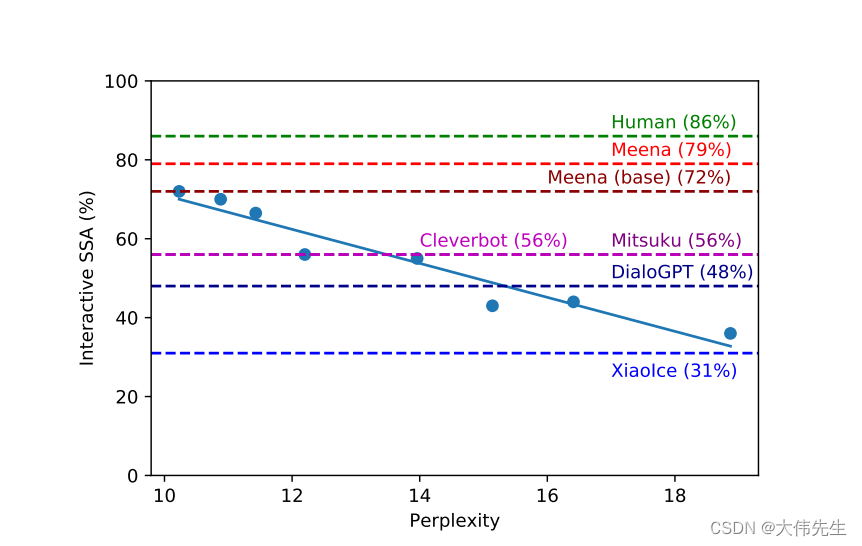
交互式 SSA 与困惑。每个点都是不同的Meena模型版本。
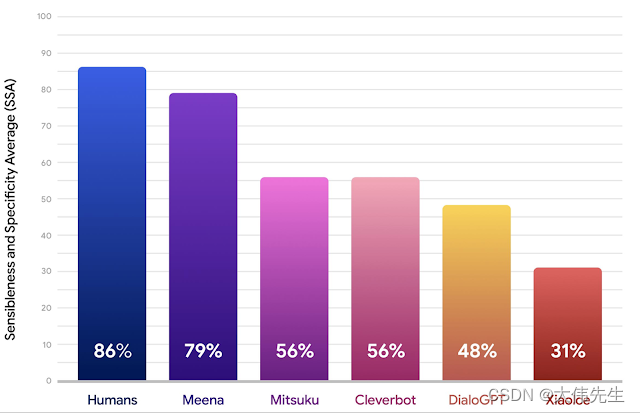
Meena Sensibleness and Specificity Average(SSA)与Human Human,Mitsuku,Cleverbot,XiaoIce和DialoGPT相比。
为了评估Meena的表现,研究人员提出了一个简单的人类评估指标,称为敏感性和特异性平均(SSA),它考虑了人类对话的两个基本方面:有意义和具体。结果表明,完整版的Meena(具有过滤机制和调谐解码)的SSA得分为79%,绝对SSA比现有的SOTA聊天机器人(如Mitsuku,Cleverbot,XiaoIce和DialoGPT)高出整整23%。
Meena也在接近人类,其平均SSA得分为86%。在一个令人惊讶的发现中,研究人员观察到SSA和困惑之间存在很强的相关性 - 这是任何神经seq2seq模型都可以使用的自动指标。实验表明,Meena与其训练数据的拟合越好,其响应就越明智和具体。
研究人员承认,他们的方法仍然存在弱点——例如,静态评估数据集过于有限,无法捕捉人类对话的所有方面和细微差别。
在未来的研究中,研究人员将探索扩大人类相似性的指标,同时继续通过优化测试集的困惑度和改进算法、架构、数据和计算来优化可感知性。他们还将考虑其他属性,如个性和事实性,以及模型安全和偏见的其他关键重点领域。
论文《走向类人开放域聊天机器人》发表在arXiv上。与Meena的对话示例在GitHub上。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









