







1、介绍
IK Analyzer 是一个开源的,基于 java 语言开发的轻量级的中文分词工具包。从 2006年 12 月推出 1.0 版开始, IKAnalyzer 已经推出了 4 个大版本。最初,它是以开源项目Luence 为应用主体的,结合词典分词和文法分析算法的中文分词组件。 从 3.0 版本开始,IK 发展为面向 Java 的公用分词组件,独立于 Lucene 项目,同时提供了对 Lucene 的默认优化实现。 在 2012 版本中,IK 实现了简单的分词歧义排除算法,标志着 IK 分词器从单纯的词典分词向模拟语义分词衍化。
1.1、分词效果示例
IK Analyzer 2012 版本支持 细粒度切分 和 智能切分,以下是两种切分方式的演示样例。
文本原文 :
张三说的确实在理
- 智能分词(smart = true)结果:
张三 | 说的 | 确实 | 在理
- 最细粒度分词(smart = false)结果:
张三 | 三 | 说的 | 的确 | 的 | 确实 | 实在 | 在理
2、Maven依赖
<dependency>
<groupId>com.janeluo</groupId>
<artifactId>ikanalyzer</artifactId>
<version>2012_u6</version>
</dependency>
3、代码样例
// 构建IK分词器,useSmart=true时,分词器采用智能切分;
// 当为false时,分词器进行最细颗粒度切分。
Analyzer analyzer = new IKAnalyzer(true);
// 获取Lucene的TokenStream对象
TokenStream ts = null;
try {
ts = analyzer.tokenStream("myfield", new StringReader("小明是个老司机"));
// 获取词元位置属性
OffsetAttribute offset = ts.addAttribute(OffsetAttribute.class);
// 获取词元文本属性
CharTermAttribute term = ts.addAttribute(CharTermAttribute.class);
// 获取词元文本属性
TypeAttribute type = ts.addAttribute(TypeAttribute.class);
// 重置TokenStream(重置StringReader)
ts.reset();
// 迭代获取分词结果
while (ts.incrementToken()) {
System.out.println(offset.startOffset() + " - " + offset.endOffset() + " : "
+ term.toString() + " | " + type.type());
}
// 关闭TokenStream(关闭StringReader)
ts.end(); // Perform end-of-stream operations, e.g. set the final offset.
} catch (IOException e) {
e.printStackTrace();
} finally {
// 释放TokenStream的所有资源
if (ts != null) {
try {
ts.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
4、词典扩展
IK Analyzer 2012 版本也支持用户扩展词典,实现方法很简单,在 resources根目录下创建名为 IKAnalyzer.cfg.xml 的配置文件:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic;</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.dic;</entry>
</properties>
在配置文件中,用户可一次配置多个词典文件。文件名使用 “;” 号分隔。文件路径为相对 java 包的起始根路径。
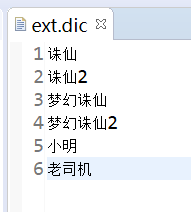
ext.dic 文件格式如下:
结束语
本篇只是告诉大家如何简单实用IKAnalyzer,如果对IK分词的实现原理感兴趣可以参考这篇文章:http://3dobe.com/archives/44/
IKAnalyzer代码及文档下载:https://gitee.com/wltea/IK-Analyzer-2012FF

















 181
181

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









