









目录
基本类型的封装类-自动拆箱与装箱
在Java中存在八种基本类型,分别为bite、int、long、double、boolean、float、short、char。与这八种类型相对应,Java提供了八种类类型:Byte、Integer、Long、Double、Boolean、Float、Short、Character。后面的八个类遵循类的使用规则,需要new一个实例空间。
但在Java在1.5版本中增加了“自动拆箱与自动装箱”功能,即在使用int类型时如果想要使用Integer类型,即可自动转换即:
public class TestInteger {
//自动拆箱与装箱
public static int fun(Integer num) {
return ++num;
}
public static void main(String[] args) {
int a = 1;
System.out.println(fun(a));
}
}变量a的类型为int,fun方法中的形参是Integer类型,但是使用fun方法调用a时并没有任何错误的显示,且结果成功。这是因为Java提供的自动装箱功能,反之亦然。对于其他七个基本类型同样如此!
泛型初步
在日常编写方法时总会遇到调用方法的参数类型未知的情况,我们可以使用重载的方法,将可能的参数类型均编写为一个方法,这个方案确实可以解决问题,但是消耗的代码行数太多,而且代码的重复也很多,使得代码不够简洁,占用代码段空间过大,影响运行速度。故我们抛弃这个方案,选择使用泛型-Java提供的功能!
public class TestT {
public static <T> T fun(T num) {
return num;
}
public static void main(String[] args) {
String a = "520";
System.out.println(fun(a));
int b = 1314;
System.out.println(fun(b));
}
}如上所示,我们调用了两次fun方法,两次调用的参数不同,但是仅仅使用了一个方法。这就是泛型的强大之处。 “public static <T> T fun(T num)”是泛型方法的表示形式,<T>是泛型的标志,T表示返回值的类型也是泛型,T num表示方法的形参是T类型的参数。泛型的特点是编写时不确定,运行时确定。泛型只能是类类型,对于八大基本类型,使用他们的类类型即可(自动拆箱与装箱)!
利用泛型可以定义泛型类,如下:
public class MyAllType <T> {
private T member;
public MyAllType() {
}
public T getMem() {
return member;
}
public void setMem(T member) {
this.member = member;
}
public void doSomething(T one) {
System.out.println(one.getClass());
}
public <K> K doSome(K one) {
System.out.println("one :" + one);
return one;
}
}
上面都是一些简单的泛型使用方式,而public class MyAllType <T>中的<T>表示泛型类的标志。
Java高级内部类
关于ArrayList
ArrayList与LinkedLIst都是Java为了解决数组问题而创造的两个高度封装的类,高度封装的类的意思是指内部实现比较复杂,而使用接口则十分简单。ArrayList内部使用数组实现,而LinkedList内部使用链表实现。二者均为“动态数组”,这里的动态并非真的动态扩容,而是当一定数量的数组使用完之后,把数组里的元素全部复制一遍后申请一个更大的数组空间,然后把复制的元素赋值给新的数组空间。
但是由于ArrayList内部使用数组实现,所有ArrayList访问数组中的某一个数组元素的时间复杂度为O(1),而LinkedList则需要O(n)。但是当需要删除或插入一个元素是ArrayList的时间复杂度为O(n),而LinkedList时间复杂度为O(1)。故当不需要频繁删除或插入操作时选择ArrayList更高效,反之LinkedList更为高效。
“ArrayList<T> TList = new ArrayList<T>();”这个就是ArrayList的生成语法,<T>是ArrayList的元素的类型,这也是泛型的应用,正是由于Java的泛型才可以使的ArrayList等高级内部工具类的出现。
ArrayList提供了很多内部方法供我们使用,添加方法(add),对象.add()将括号内的数值存入数组中。
for(int num : intList) {
System.out.println(num);
}
for (int index = 0; index < intList.size(); index++) {
int num = intList.get(index);
System.out.print(index + " : " + num + " , ");
}存储完毕后,可以使用上面所示代码输出ArrayList中所存元素,上面所示方法为for循环的两种使用方法。第一种中 int 为数组中元素的类型,intList是数组名,第二种可以更好的展示出数组下标与元素的对应关系。
提取元素(get):对象.get(index)可以提取到数组下标为index的元素;
判断方法(contains):对象.contains(元素)可以判断一个元素是否存在数组中,在执行contains方法时JVM会自动调用equals方法,如果我们没有覆盖equals的话就会调用Object类的equals方法,比较首地址。
查找方法(indexOf):对象.indexOf(元素)可以得到所查找元素的下标。
代码实现如下:
ArrayList<Complex> complexList = new ArrayList<>();
for (int i = 0; i < 10; i++) {
complexList.add(new Complex(i));
}
for (Complex c : complexList) {
System.out.println(c);
}
// Complex c1 = new Complex(13);
Complex c1 = new Complex(3);
Complex c2 = complexList.get(4);
System.out.println(complexList.contains(c1));//判断是否存在
System.out.println(complexList.contains(c2));
int index = complexList.indexOf(c1);//查找数组元素下标
System.out.println("index : " + index);
System.out.println("index : " + complexList.indexOf(c2));
LinkedList<String> strList = new LinkedList<>();
strList.add("abcde");
String str = strList.get(0);
System.out.println(str);
}
}关于HashMap
HashMap是双泛型类,采用的是<键,值>(键值对)来存储数据,它的基本操作为添加键值对(put方法)和根据键或值来得到另一个值或键(get方法)。put用来存储一个键值对,而get用来提取一个键值对。 基本操作如下所示:
public static void main(String[] args) {
HashMap<String, String> nameMap = new HashMap<>();
nameMap.put("1001", "张三");
nameMap.put("1002", "李三");
nameMap.put("1003", "王五");
nameMap.put("1004", "赵六");
nameMap.put("1005", "黄七");
String hash = nameMap.get("李四");
System.out.println(hash);
nameMap.put("1002", "李四");
System.out.println(nameMap.size());
}
键值为对象类型的时候就需要重写hashCode和equals方法,覆盖equal方法是因为原来Object类的equals方法比较的是地址,只有覆盖之后才能完成相等比较。
而覆盖hashCode是因为当我们向HashMap添加一个值时,HashMap首先会调用hashCode来计算hash值作为地址,如果没有重写hashCode方法,所以hashmap是调用的Object的hashCode方法来计算hash值,Object中hashCode计算出来的hash值其实就是对象的地址,所以必须覆盖hashCode方法。如下所示:
当我们使用值去搜索键时则会得到:
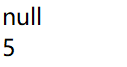 无法得到正确的键,所以我们必须覆盖hashCode方法!
无法得到正确的键,所以我们必须覆盖hashCode方法!
为了更好的验证HashMap的有关知识,我建立了一个数据类(包含学号、姓名和性别),作为存储的值。如下:
public class StudentInfo {
private String stuId;
private String name;
private boolean sex;
public StudentInfo() {
}
public StudentInfo(String stuId, String name, boolean sex) {
this.name = name;
this.sex = sex;
this.stuId = stuId;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getStuId() {
return stuId;
}
public void setStuId(String stuId) {
this.stuId = stuId;
}
public boolean isSex() {
return sex;
}
public void setSex(boolean sex) {
this.sex = sex;
}并且覆盖掉hashCode和equals方法
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((stuId == null) ? 0 : stuId.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
StudentInfo other = (StudentInfo) obj;
if (stuId == null) {
if (other.stuId != null)
return false;
} else if (!stuId.equals(other.stuId))
return false;
return true;
}
为了输出更美观简洁,重写了ToString方法:
@Override
public String toString() {
return "StudentInfo [stuId=" + stuId + ", name=" + name + ", sex=" + sex + "]";
}HashMap使用时需要注意几点:
1、键不能重复:因为使用键值对的存储方式,一个键只能对应一个值,就像每个身份证只对应一个人一样。具有唯一性!当存储一个键值对时,JVM首先会先查看这个键是否存在,如果存在就用新值覆盖旧值,如果没有则建立一个新的键值对。如下:nameMap.put("1001", "张三");nameMap.put("1001", "0");之后再次使用get方法查看1001的值则为:
 得以验证。
得以验证。
2、值可以重复,甚至可以为null
3、无序性与遍历:HashMap存储的键值对是无序的,即按顺序存储后,JVM会形成一个毫无规律可言的顺序存储。先产生一个HashMap:
HashMap<String, StudentInfo> studentPool;//键值对,使用HashMap必须重载hashCode与equals方法
studentPool = new HashMap<String,StudentInfo>();
studentPool.put("12345678", new StudentInfo("12345678", "张三丰", true));
studentPool.put("12345677", new StudentInfo("12345677", "李四", true));
studentPool.put("12345676", new StudentInfo("12345676", "王五", true));
studentPool.put("12345675", new StudentInfo("12345675", "刘六", true));
studentPool.put("12345674", new StudentInfo("12345674", "曹七", true));
studentPool.put("12345673", new StudentInfo("12345673", "马八", true));
studentPool.put("12345672", new StudentInfo("12345672", "牛九", false));之后则输出这个HashMap,输出时可以依靠两个提供的内部方法:keySet方法和values方法,keySet可以取得键集合,而values可以取得值集合。
for (String id : studentPool.keySet()) {
System.out.println(id);
}
for (StudentInfo student : studentPool.values()) {
System.out.println(student);
}遍历结果如下: 
完成了HashMap的遍历以及验证了无序性!
如果想要删除一个键值对的话,可以使用remove方法,如下所示可以使用根据键删除或者根据键与值一起删除:
HashMap以及ArrayList的出现,是泛型的具体应用,提供了多种多样的处理不同数据的方法,提高了解决问题的效率,能够大幅提高之后需要实现的算法的时间复杂度!帮助我们更好的解决问题,实现需求。















 4013
4013











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









