









Kafka是一种高吞吐量的分布式发布/订阅消息系统,它可以处理网站中的所有数据流(网页浏览、搜索等),通过Hadoop的并行加载机制来统一线上和离线的消息处理,通过集群来提供实时的消费。有如下特性:
- 通过O(1)的硬盘数据结构提供消息的持久化,这种结构对于数以TB计的消息存储也能够保持长时间的稳定性能;
- 高吞吐量,即使是非常普通的硬件,Kafka也可以支持每秒数百万的消息;
- 支持通过Kafka服务器和消费机集群来对消息分区;
- 支持Hadoop并行数据加载。
Kafka是由Linkedin开发的一个分布式消息队列系统(Message Queue),
目标是构建一个处理海量日志、用户行为和网站运营统计等的数据处理框架。在结合了数据挖掘、行为分析、运营监控等需求的情况下,需要能够满足各种实时在线和批量离线处理应用场合对
低延迟和批量吞吐性能
的要求。
需求:高吞吐率、实时性、持久性
适用于:对数据稳定性、一致性、可靠性要求不高的场景。
既有的消息队列框架或对消息传送的可靠性提供了较高的保证,由此带来较大的负担,不能满足海量高吞吐率的要求;或完全面向实时消息处理系统,对于批量离线处理的场合无法提供足够的缓存和持久性要求。而多数针对大数据开发应用的日志收集处理系统(scribe,flume)则通常更适合批量离线处理场合,对实时在线处理的场合支持不够。
Kafka试图提供一个同时满足在线和离线处理海量数据的消息派发系统。
核心模型抽象:
topics:某种消息的高层抽象
producers:消息的生产者
consumers:消息的消费者
broker:集群中的一个节点服务器,多个broker组成一个集群
整体结构:
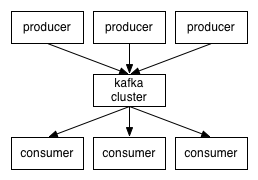
topic:
1、kafka集群会将每个topic进行分区,每个分区都是一个
排序且不可改变的队列
,新的消息会进入
队尾并分配一个唯一ID
,称之为
偏移量(offset);
2、无论消息是否被消费,集群都会保留消息,默认
配置的时间(过期时间)
,超过这个时间后,消息会被清除。
3、
消费端
唯一记录的元信息就是
自己在topic中的位置(offset);
4、分布式的原因:第一集群可以容纳大量的数据;第二可以并行的处理。
分布式:
1、每一份数据都会复制到不同的服务器上,以便于
容错处理
;
2、每一个topic的分区都会有
一个leader,并有零个或多个follower
,所有的读写请求都会经过leader来进行分发,若是leader发生错误的话,那么就会有一个follower成为leader。
生产者:
producers会将数据发送到topic,发送的目的地可以根据
轮询策略
或是到指定的分区策略。
消费者:
一般有两种模式,其一是队列,另一种是发布订阅。
队列:有很多消费者,每个消费者从队列中获取其中一个数据,一个数据只被消费一次。
发布订阅模式:将一个消费广播到所有的消费者,一个数据会被消费N次。
Kafka对于消费者提供了一种简单的抽象-消费组。每个消费者都会有一个消费组的名称,一个消费会发布到一个topic上,同时递送订阅到这个消息的消费组下的所有消费者。
如果所有的消费者都是同一消费组,那么就是一个队列模式。
反之,如果消费者有不同的组,那么就是发布订阅模式,消费会递送给所有的消费者。
通过对于消费组的名称不同来区分了队列和发布订阅模式。
活动流数据(页面访问、内容信息、搜索情况等)通常的处理方式是把活动以日志的形式写入文件,周期性的对文件进行统计分析;
运营数据(服务器的性能数据-CPU、IO使用率、请求时间、服务日志等)。















 1389
1389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









