







本节代码存放在github网址上,环境:python3
利用AdaBoost元算法提高分类性能
元算法(meta-algorithm)或者集成方法(ensemble method)是对其他算法进行组合的一种方式
AdaBoost算法
优点:范化错误率低,易编码,可以应用在大部分分类器上,无参数调整
缺点:对离群点敏感
适用数据类型: 数值型和标称型数据
bagging和boosting所使用的多个分类器类型都是一致的!
bagging: 基于数据随机抽样的分类器构建方法
放回取样得到S个数据集,将某个学习算法分别作用于每个数据集就得到了S个分类器,要对新数据进行分类时,可以应用这S个分类器进行分类,
选取分类器投票结果中最多的类别作为最后的分类结果。分类器的权重是相等的。
random forest 也是bagging方法的一种
boosting:通过集中关注被已有分类器错分的那些数据来获得新的分类器
不同的分类器是通过串行训练获得的,每个新的分类器都根据已训练出的分类器的性能来训练。
其分类结果是基于所有分类器的加权求和结果的,分类器权重并不相等,每个权重代表的是其对应分类器在上一轮迭代中的成功度。
AdaBoost一般流程
- 收集数据:可以使用任何方法
- 准备数据:依赖于所使用的弱分类器类型,本章使用的是单层决策树,这种分类器可以处理任何数据类型。当然也可以使用任意分类器作为弱分类器,KNN, 决策树,朴素贝叶斯,Logistic回归,SVM中任一分类器都可以充当弱分类器。作为弱分类器,简单分类器的效果最好。 确保类别标签是+1和-1,而非1和0.
- 分析数据:可以使用任一方法分析数据:可以使用任一方法
- 训练算法:AdaBoost的大部分时间都用在训练上, 分类器将多次在同一数据集上训练弱分类器。
- 测试算法:计算分类的错误率测试算法:计算分类的错误率
- 使用算法:同SVM同,AdaBoost预测两个类别中的一个。若想把它应用到多分类的场合,需要像多类SVM中的做法一样对AdaBoost进行修改。使用算法:同SVM同,AdaBoost预测两个类别中的一个。若想把它应用到多分类的场合,需要像多类SVM中的做法一样对AdaBoost进行修改。
AdaBoost运行过程
训练数据中的每个样本,并赋予其一个权重,这些权重构成了向量D. 一开始,这些权重都初始化成相等值。首先在训练集上训练出一个弱分类器,并计算该分类器的错误率,然后在同一数据集上再次训练弱分类器。在分类器的第二次训练中会调整每个样本的权重,其中第一次分对的的样本中的权重将会降低,而第一次分错的样本中的权重将会提高。为了从所有弱分类器中得到最终的分类结果,AdaBoost为每个弱分类器都分配了一个权重值alpha,这些alpha是基于每个弱分类器的错误率进行计算的。
错误率ε定义为:

alpha定义为:
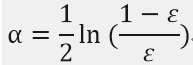
计算出alpha后,可以对权重D进行更新,以使那些正确分类的样本权重降低而错分样本的权重提高。D的计算方法如下:
若某个样本被正确分类,该样本权重更改为:
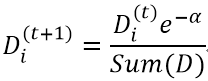
若某个样本被错分,该样本权重更改为:
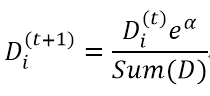
基于单层决策树构建弱分类器
伪代码如下:
将最小错误率minError设为+inf
对数据集中每个特征(第一层循环):
对每个步长(第二层循环):
对每个不等号(第三层循环):
建立一棵单层决策树并利用加权数据集对它进行测试
如果错误率低于minError,则将当前单层决策树设为最佳单层决策树
返回最佳单层决策树
python代码如下:
# -*- coding: utf-8 -*-
__author__ = 'WF'
# import warnings
import numpy as np
# warnings.simplefilter(action='ignore', category=FutureWarning)
# 加载简单数据集
def loadSimpleData():
dataMat = np.matrix([[1., 2.1],
[2., 1.1],
[1.3, 1.],
[1., 1.],
[2., 1.]])
classLabel = [1.0, 1.0, -1.0, -1.0, 1.0]
return dataMat, classLabel
# 图形化展示数据
def plot_simpledata():
import matplotlib.pyplot as plt
x, y = loadSimpleData()
y = np.array(y)
x = np.array(x)
# print(y)
# x1 = x[np.nonzero(y)[0]]
x1 = x[np.where(y == 1.0)[0]]
# print(np.nonzer 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3727
3727











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









