






k8s部署ELK系列四:集成Logstash日志处理
文章目录
在 Kubernetes 集群中,应用服务的日志对于故障排查和性能分析至关重要。传统的日志查看方式(如 kubectl logs)存在不便于集中管理和持久化存储的问题,因此,我们需要构建一套集中化的日志采集系统。
ELK(Elasticsearch + Logstash + Kibana)是目前主流的日志分析解决方案,其中 Logstash 作为日志处理与转发的核心组件,能够实现日志数据的解析、过滤与清洗,并灵活转发到不同的存储后端。
本篇文章将介绍如何在 Kubernetes 环境中部署 Logstash,实现日志的收集、处理与转发,为后续日志分析和可视化打下基础。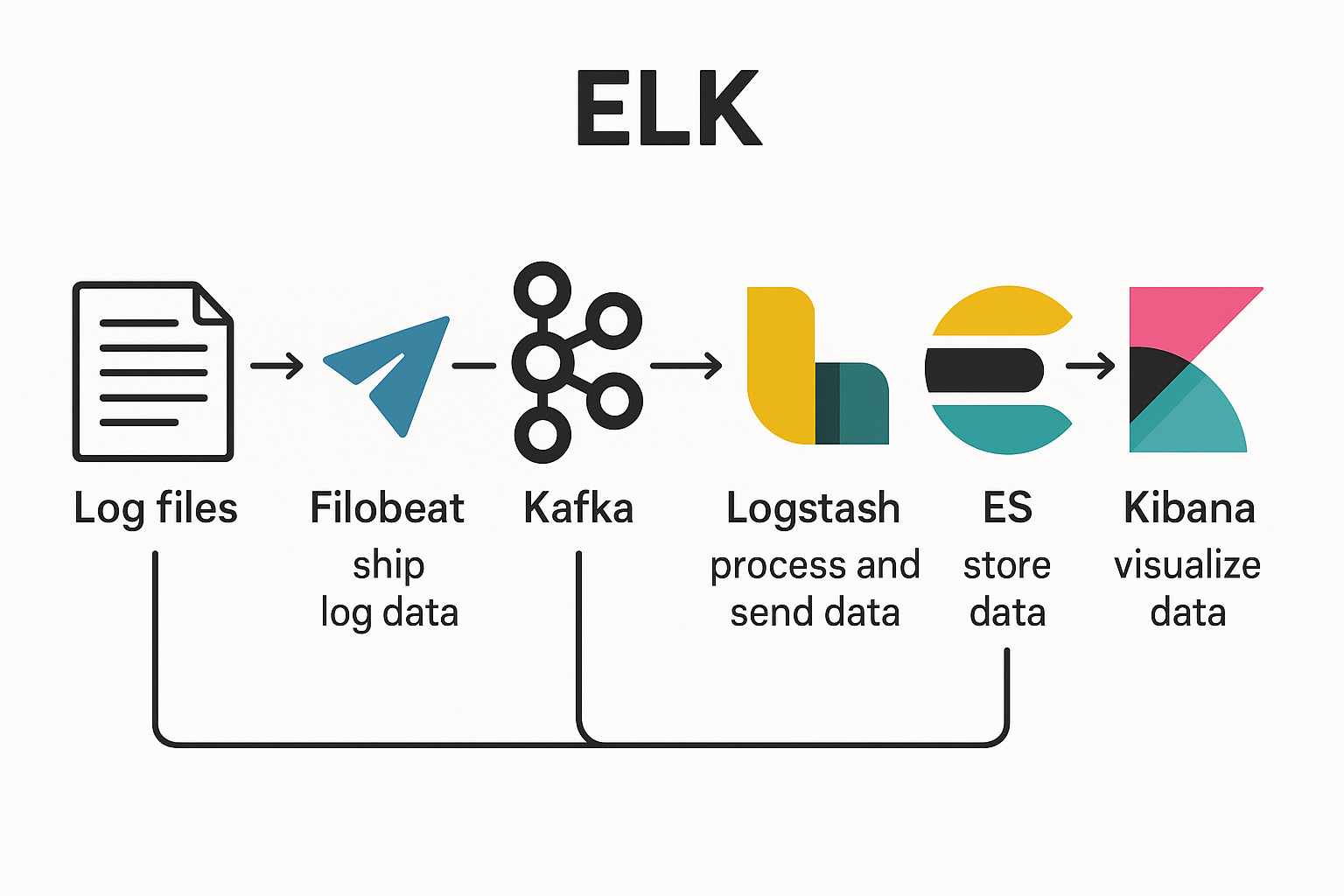
一、Logstash简介
Logstash 是 Elastic Stack 中的一款强大且灵活的数据收集与处理引擎,主要用于从多种来源收集数据,进行过滤、解析、转化后,转发到指定的存储系统(如 Elasticsearch 等)。它支持丰富的输入、过滤器和输出插件,能够对日志数据进行结构化处理和格式化转换。
与传统的日志处理工具相比,Logstash 具备高扩展性和复杂数据处理能力,适用于构建灵活的数据采集与处理管道,广泛应用于日志分析、监控系统和安全审计场景中。
二、Logstash处理流程解析
Logstash 的数据处理流程可以分为以下三个主要阶段:
1. 输入(Input)
Logstash 的数据输入是指从各种数据源获取数据的过程。Logstash 提供了多种输入插件,可以连接不同的数据源,包括文件、数据库、消息队列等。在 Kubernetes 环境中,Logstash 常用的输入源有:
- 文件输入(file):从本地或远程文件系统中读取日志。
- Kafka输入(kafka):从 Kafka 集群中拉取日志消息。
- Beats输入(beats):接收来自 Filebeat 等轻量级日志采集工具的日志数据。
2. 过滤(Filter)
Logstash 的强大之处在于它对数据进行复杂的过滤与转换处理。在这一阶段,Logstash 会根据预设的过滤条件,进行数据解析、格式化、增强等处理,确保数据以符合目标存储系统的格式进行传输。常见的 Logstash 过滤插件有:
- grok:用于对日志进行模式匹配,提取结构化数据。可以从非结构化的日志文本中提取出如 IP 地址、时间戳、日志级别等字段。
- mutate:用于对字段进行修改,比如重命名、删除、添加字段等。
- date:将日志中的日期字段转换为标准时间戳格式,确保日志的时间一致性。
- geoip:根据 IP 地址进行地理位置定位,添加地理信息字段。
3. 输出(Output)
在 Logstash 完成数据的解析与过滤后,最终会将处理过的数据输出到指定的目标存储系统。Logstash 支持多种输出插件,可以将数据输出到 Elasticsearch、Kafka、数据库、文件等系统。
在 Kubernetes 环境中,通常将处理过的日志数据输出到 Elasticsearch,以便进行后续的分析和可视化,或者输出到 Kafka 中进一步传递到其他服务。常见的输出插件有:
- elasticsearch:将数据写入 Elasticsearch。
- file:将数据写入文件。
- stdout:将数据输出到控制台,便于调试。
三、Logstash实战部署
1. 创建Namespace(elk-namespace.yaml)
首先,创建一个新的命名空间,用于部署 ELK 相关的资源
apiVersion: v1
kind: Namespace
metadata:
name: elk
2. 创建ConfigMap(logstash-configmap.yaml)
接下来,我们创建一个 ConfigMap,用来存储 Logstash 的配置文件。这里的配置将会告诉 Logstash 如何从 Kafka 中拉取日志,如何处理这些日志,并将其输出到 Elasticsearch
---
apiVersion: v1
kind: ConfigMap
metadata:
namespace: elk
name: logstash-config
labels:
app: logstash
data:
logstash.conf: |
input {
kafka {
bootstrap_servers => "kafka-0.kafka-headless.elk.svc.cluster.local:9092"
topics => ["k8s-outlog"]
group_id => "logstash-consumer-group"
codec => "json"
consumer_threads => 1
decorate_events => true
security_protocol => "PLAINTEXT"
}
}
filter {
if [fields][logformat] == "json" {
json {
source => "message"
target => "message"
}
}
}
output {
if [fields][logtype] =~ "k8s-outlog.*" {
elasticsearch {
hosts => ["http://elasticsearch-0.elasticsearch-cluster.elk.svc.cluster.local:9200"]
index => "k8s-outlog-%{+YYYY.MM.dd}"
}
}
if [fields][logtype] =~ "k8s-messagelog.*" {
elasticsearch {
hosts => ["http://elasticsearch-0.elasticsearch-cluster.elk.svc.cluster.local:9200"]
index => "k8s-messagelog-%{+YYYY.MM.dd}"
}
}
}
3. 创建Service(logstash-service.yaml)
创建一个 Service 服务,以便其他 Pod 能够访问 Logstash
apiVersion: v1
kind: Service
metadata:
name: logstash
namespace: elk
labels:
app: logstash
spec:
selector:
app: logstash
ports:
- protocol: TCP
port: 5044
targetPort: 5044
type: ClusterIP
4. 创建Deployment(logstash-deployment.yaml)
接下来,创建 Logstash 的 Deployment,指定 Logstash 容器的镜像、环境变量和配置文件挂载等信息
apiVersion: apps/v1
kind: Deployment
metadata:
name: logstash
namespace: elk
spec:
replicas: 1
selector:
matchLabels:
app: logstash
template:
metadata:
labels:
app: logstash
spec:
containers:
- name: logstash
image: harbor.local/k8s/logstash:7.17.0
env:
- name: "PIPELINE_WORKERS"
value: "2"
- name: "PIPELINE_BATCH_SIZE"
value: "5000"
- name: "PIPELINE_BATCH_DELAY"
value: "2"
- name: "LS_JAVA_OPTS"
value: "-Xms512m -Xmx1g"
- name: "path.config"
value: "/usr/share/logstash/pipeline"
- name: "xpack.monitoring.elasticsearch.hosts"
value: "http://elasticsearch-0.elasticsearch-cluster.elk.svc.cluster.local:9200"
volumeMounts:
- name: config
mountPath: /usr/share/logstash/pipeline/logstash.conf
readOnly: true
subPath: logstash.conf
- mountPath: /etc/localtime
readOnly: true
name: tz-config
volumes:
- name: config
configMap:
name: logstash-config
- name: tz-config
hostPath:
path: /etc/localtime
5. 部署所有资源
将上述 YAML 文件保存后,使用以下命令统一部署
kubectl apply -f elk-namespace.yaml
kubectl apply -f logstash-configmap.yaml
kubectl apply -f logstash-service.yaml
kubectl apply -f logstash-deployment.yaml
6. 验证Logstash Pod状态
kubectl get pod -n elk
 —
—
总结
📌 通过本实战,我们成功在 Kubernetes 集群中部署了 Logstash,并通过 Kafka 收集日志数据、进行处理后输出到 Elasticsearch。这是实现集中化日志管理和分析的关键一步。通过 Logstash 的强大功能,我们能够灵活地处理不同来源的日志数据,并将其转发到指定的存储系统,为后续的日志分析和可视化提供了基础。
下一篇文章将深入探讨 Kibana 的部署,作为 ELK 堆栈的最后一个组件,我们将配置 Kibana 以便可视化 Elasticsearch 中存储的日志数据,提升日志查询和分析的便捷性。

















 2266
2266

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









