







接上篇。
过程
我们在学C语言中,经常会注意到一个话题,就是函数参数的入栈问题。然后,就有接下来的图片
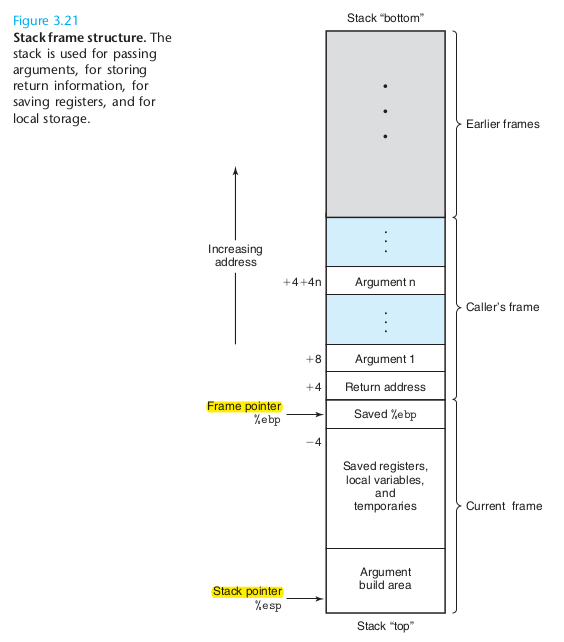
然后在栈向下生长的方向上,一般来就,就调用者和非调用者的关系。一般来说,当一个函数调用另一个函数时,会先把最右边的参数压入到高地址,然后把最左边的参数压入低地址。最后把函数的返回地址压入栈。这也是平时所说的,函数从右往左入栈的来源。
上图中,还引出另一个问题,如果被调用者的参数,是调用者的局部变量,机器级该如何去解释?下面插入书中的一段代码:
int P(int x)
{
int y = x*x;
int z = Q(y);
return y + z;
}我们知道,调用者P的局部变量y是被调用者Q的形参。那么,y的这个值怎么样在栈上保存,才使得Q退出栈出,y仍然可用?
两种方法:
1。 将y保存在P的栈上,这样当Q的栈清空时,y仍然可用。
2。 将y保存在Q的栈上,当Q的栈空间回收时,把这个值恢复到P的栈上,或者是可访问的通用寄存器上。
如果Q的参数是一个指针呢?
原书图3.24刚好指出了这个问题。
下面是原书的图3.23的代码片段
int swap_add(int *xp, int *yp)
{
int x = *xp;
int y = *yp;
*xp = y;
*yp = x;
return x + y;
int caller()
{
int arg1 = 534;
int arg2 = 1057;
int sum = swap_add(&arg1, &arg2);
int diff = arg1 - arg2;
return sum * diff;
}当caller调用swap_add时,不是传的形参,而是指针。那么在栈上的空间分布如何?
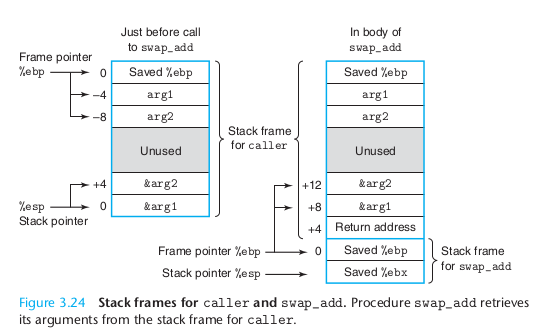
可以看到,在调用swap_add前,caller的栈空间中,就有arg1, arg2的值。那么,传递的参数,&arg1, &arg2是在caller的栈上。然后再压入返回值。也就是说,引用类型的参数,在调用者的栈空间上。汇编代码如下:

可以看出,-4(%ebp)和-8(%ebp)为arg1和arg2的值存放的地址。然后把这两个地址放到4(%esp)和(%esp)中,,最后才调用swap_add。这时的栈空间是caller的栈空间。
那么,swap_add是如何去找这两个参数的呢?因为调用swap_add之后,栈空间是swap_add的栈空间,而不是caller的栈空间。
当调用swap_add之后,对%ebp, %esp改变了值。那么,&arg1和&arg2对于caller栈来说,是%ebp和%ebp+4这两个地址。但对于swap_add 来说,由于新加了一个返回地址,还有ebp的地址。所以&arg1和&arg2对于swp_add的栈指针的偏移地址,是%ebp+8, %ebp+12。那么生成的汇编代码如下:
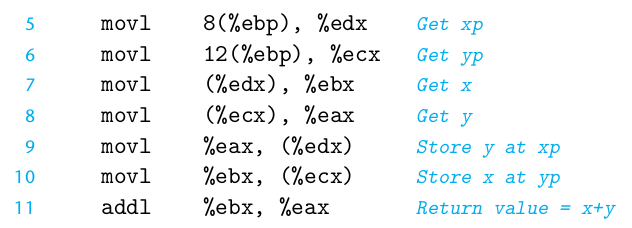
第5行和第6行,即&arg1和&arg2的地址,然后第7行和第行,再从地址上取值。最后放到%eax和%ebx中。
最后用leave指令释放栈指针。
另外书中提到一下,GCC分配的栈空间,必须是16字节的整数倍,保证了数据的严格对齐。
递归
在汇编语言的实现上,也是一层一层去展开栈空间。然后在调用者的栈上,存放局部变量,使用栈在一层层回退时,变量仍然可以使用。
数组
对于二维数组来说,一般&D[i][j] = x+L(c*i + j).这也可以理解为什么在内存中,先展开j,然后再展开i了。在址址计算中,编译器尽可能用位移与加法,来做乘法操作。
变长数组是C99上的特性,gcc已经完美支持了。
结构与联合
C的结构体相当于C++的类。对于联合,主要说到,如果在联合里面,无法区分类型时,最好用一个type来区分类型。这样可以最有效的应用空间。
typedef enum { N_LEAF, N_INTERNAL } nodetype_t;
struct NODE_T {
nodetype_t type;
union {
struct {
struct NODE_T *left;
struct NODE_T *right;
} internal;
double data;
} info;
};数据对齐
由于在32位机器上,一般是4字节对齐,在64位机器上,一般是8字节对齐。那么我们在写结构体时,一般会把8位,16位,32位的定义,有意识的拼在一起。完成32位,或者是64位的对齐。便于处理器的优化,也不会引发不对齐造成的异常。
GDB调试器
对于调试命令,不需要做过多的总结。
主要要理解,编译器的优化引发的调试器的一些问题。
对于-O2的优化,会引发下列问题:
1。 建立和完成函数的栈管理代码与实现过程操作的代码混在一起。感觉是方便CPU预取指令做的优化。但是会引发汇编上的阅读困难。
2。 内联函数直接展开在函数的内部,虽然减小了函数调用上的开销,但是没办法在内联函数上加断点。如果必须要给内联函数上加断点,建议把inline关键字去掉。
3。 一般的递归,编译器会把流程优先成while循环产生的代码。这样可以优化栈空间的大小问题。
这里面引出另一个问题,一般来说,对于嵌入式开发中的驱动开发,会有严格的时序问题,如果在编译中,把看似不相干的代码,优化成时序无关的代码片断,会在驱动中出各种问题。需要去查一下linux内核中,是采用什么样的关健字,防止编译器在-o2优化时,避免驱动的优化的。关于O3的优化的讨论,可以参考这个链接。
存储越界及优化
理解了gets函数造成的问题,我们可以清楚,在gets的栈空间的分配一定的情况下,字符串长度过大,直接会破坏栈指针,甚至可以去改栈指针。达到跳转的目的。
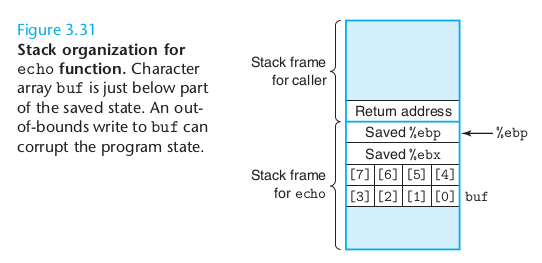
如果是把return address修改掉,那么直接可以跳转到其它地方了。这也是黑客破解的常用方法之一。
为了防止这种攻击,在gcc做了一些优化。
1。 栈随机化,不是按照出虚拟地址空间固定分配栈空间了。利用地址空间分布随机化,更难的得到栈的地址了。
2。 栈破坏检测,在栈里面加入cannary,用来检查栈是不是被改过。
3。 将内存中的页标记,由原来的读写执行只用一位表示。把执行标记分开表示。由硬件来完成内存的检查。在不降低性能的情况下,保证了安全。
后续的64位章节上的汇编语言分析暂且略过,包括浮点。















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









