






实现的比较粗略,仅供参考。
在这里我将空表示为@,结束符表示为#
程序从指定文件中读取产生式,产生式要求一行一个并且非终结符与产生式之间以"->"连接无空格,其实,只要保证两个之间有两个字符就可以,因为是这么读取的,你也可以自己修改源码。
非终结符只能是26个大写字母,并且不接受A'之类的,只能是单个字符。
改变文件路径直接在main中改就可以了。
消除左递归部分没有做的很完整,只能部分消除,也没有消除不可到达产生式。
更多注释在代码中。用例:
E->TA
A->+TA
A->@
T->FB
B->*FB
B->@
F->(E)
F->a
匹配句子:a+a#
结果:

第一行是输入,剩余的是程序输出。
中间的first集、follow等等在控制台输出,截图:
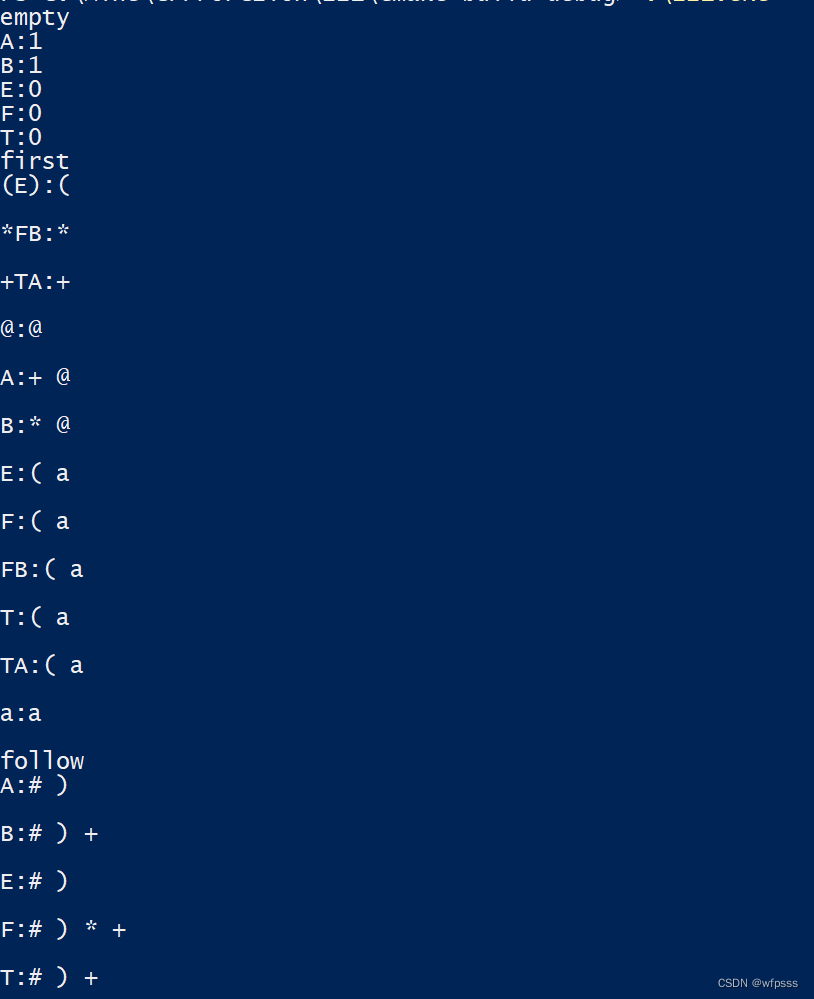
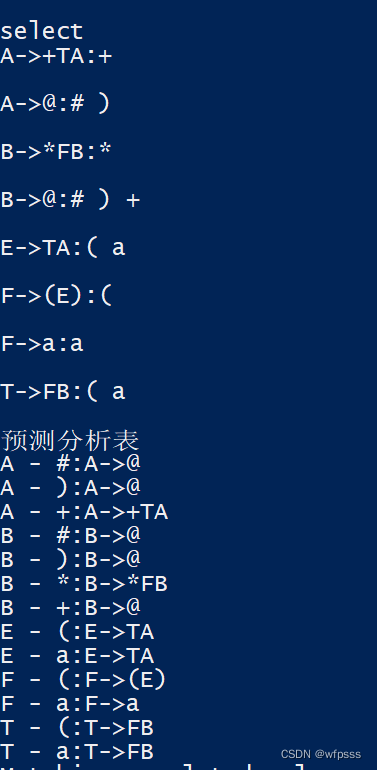
empty就是非终结符是否能产生空,1能0不能,first就是输出first集合,非终结符的、串的,以此类推follow、select、预测分析表。
源码如下:
#include <algorithm>
#include <fstream>
#include <iostream>
#include <map>
#include <set>
#include <string>
#include <vector>
// 本程序实现LL1文法的判别、推导
// 消除了左递归 但未实现消除不可到达产生式
// 为了看起来更直观 使用@符号表示空 #表示句子结束
// 程序从指令路径文件中读取产生式
// 用于输出set集合 测试用
std::ostream& operator<<(std::ostream& os, std::set<char>& s)
{
for (auto& it : s)
{
std::cout << it << " ";
}
std::cout << std::endl;
return os;
}
// 产生式类
// 一个产生式应该具备这种形式:A->xxx并且文件中每一行都应该满足A->xxx这种形式 不允许出现A->xxx|yyy
// 其中A是非终结符 xxx、yyy是非终结符、终结符和@的组合或其中一个
// 产生式第一行左部是文法开始符号
// 非终结符应该只包含26个大写字母 终结符不应该包括@和#
class Product
{
friend void addFirst(const char& dest, const char& from, Product* p);
public:
explicit Product(const std::string& str)
{
// 打开文件并装载到m_productions中
std::ifstream is(str);
if (!is.is_open())
{
throw std::logic_error("open file error... filename:" + str);
}
std::string line;
while (std::getline(is, line))
{
// 输入产生式
m_productions.insert(std::make_pair(line[0], line.substr(3)));
// 放进非终结符
m_nt.insert(line[0]);
// 放进右部的串
m_rs.insert(line.substr(3));
}
is.close();
// 获取文法开始符号 规定开始符号应该是第一个产生式的左部
is.open(str);
std::getline(is, line);
m_start = line[0];
is.close();
}
// 打印输出 测试用
#define PRINT(set) \
for (auto& it : set) \
{ \
std::cout << it.first << ":" << it.second << std::endl; \
}
// 消除文法左递归
bool removeLR();
// 打印产生式
void printPro()
{
PRINT(m_productions)
}
// 打印右部符号串
void printRs()
{
for (auto& it : m_rs)
{
std::cout << it << std::endl;
}
}
// 计算非终结符是否能产生空
void toEmpty();
// 打印非终结符是否能产生空
void printEmpty()
{
std::cout << "empty" << std::endl;
PRINT(m_toempty)
}
// 计算first集合
void toFirst();
// 打印first集合
void printFirst()
{
std::cout << "first" << std::endl;
PRINT(m_first)
}
// 计算follow集合
void toFollow();
// 打印follow集合
void printFollow()
{
std::cout << "follow" << std::endl;
PRINT(m_follow)
}
// 计算select集合
void toSelect();
// 打印select集合
void printSelect()
{
std::cout << "select" << std::endl;
PRINT(m_select)
}
// 判断是否是LL1文法
bool isLL1();
// 构建预测分析表
void buildPat();
// 输出预测分析表
void printPat()
{
std::cout << "预测分析表\n";
for (auto& it : m_pat)
{
std::cout << it.first.first << " - " << it.first.second << ":" << it.second << std::endl;
}
}
// 完成所有动作
void finish();
// 匹配给定句子 将从文件中读入 并将结果写入文件 要求输入句子由#结尾 并且句子只有一行
void matchSentence(const std::string& file);
private:
// 文法开始符号
char m_start;
// 产生式集合
std::multimap<char, std::string> m_productions;
// 非终结符集合
std::set<char> m_nt;
// 右部符号串集合
std::set<std::string> m_rs;
// 非终结符对应的是否能产生@(空)
std::map<char, bool> m_toempty;
// 非终结符与串对应的first集合
std::map<std::string, std::set<char> > m_first;
// 非终结符对应的follow结集合
std::map<char, std::set<char> > m_follow;
// 产生式的select集合
std::map<std::string, std::set<char> > m_select;
// 预测分析表 非终结符遇见终结符 对应的产生式
std::map<std::pair<char, char>, std::string> m_pat;
};
// 消除左递归
bool Product::removeLR()
{
// 左递归形式如:S->S**T
// 要想消除左递归 必须需要S具有这样的产生式 S->T T为任意非终结符
// 顺序使用一个不在当前非终结符集合的大写字母作为消除递归的中间符号
// 对于S->S**T|T 消除左递归后为
// S->TS'
// S'->**TS'
// S'->@
std::vector<std::multimap<char, std::string>::iterator> rm; // 待删除的产生式集合
for (auto it = m_productions.begin(); it != m_productions.end(); ++it)
{
// 出现左递归
if (it->first == it->second[0])
{
// 放进去 等会删除
rm.push_back(it);
// 给出需要找到的右部 自左向右找非终结符(除了第一个)
std::string str;
for (size_t i = 1; i < it->second.size(); ++i)
{
if (it->second[i] >= 'A' && it->second[i] <= 'Z')
{
str.push_back(it->second[i]);
}
}
// 看看能不能找到另一个产生式 不能则消除失败
bool isfind = false;
for (auto it2 = m_productions.begin(); it2 != m_productions.end(); ++it2)
{
if (it2->first == it->first && it2->second == str)
{
rm.push_back(it2);
isfind = true;
break;
}
}
if (!isfind)
{
std::cerr << "消除左递归失败" << std::endl;
return false;
}
// 开始消除左递归
// 找一个没被使用的非终结符
char n = '\t';
for (char c = 'A'; c <= 'Z'; ++c)
{
if (!m_nt.count(c))
{
n = c;
m_nt.insert(c);
break;
}
}
if (n == '\t')
{
std::cerr << "消除左递归失败,26个非终结符均已使用" << std::endl;
return false;
}
// 构建
std::pair<char, std::string> p1(it->first, str + n); // 这是形如S->TS'
std::pair<char, std::string> p2(n, it->second.substr(1) + n); // 这是形如S'->**TS'
std::pair<char, std::string> p3(n, "@"); // 这是形如S'->@
m_productions.insert(p1);
m_productions.insert(p2);
m_productions.insert(p3);
}
}
// 先删除类中右部的串
for (auto& it : rm)
{
auto it2 = std::find(m_rs.begin(), m_rs.end(), it->second);
m_rs.erase(it2);
}
// 删除产生式
for (auto& it : rm)
{
m_productions.erase(it);
}
return true;
}
// 计算空
void Product::toEmpty()
{
std::multimap<char, std::string> pro = m_productions;
// 运用规则:如果产生式右部为空 则设置该终结符为能产生空并消去所有以此终结符为左部的产生式
std::vector<std::multimap<char, std::string>::iterator> to_remove;
for (auto it = pro.begin(); it != pro.end(); ++it)
{
if (it->second == "@")
{
// 插入此非终结符可以产生空
m_toempty.insert(std::make_pair(it->first, true));
// 消去所有以此终结符为左部的产生式 放入待删除数组
char c = it->first;
for (auto it2 = pro.begin(); it2 != pro.end(); ++it2)
{
if (it2->first == c)
{
to_remove.push_back(it2);
}
}
}
}
// 真正删除
for (auto it : to_remove)
{
pro.erase(it);
}
to_remove.clear();
// 运用规则 删除所有产生式右部含有非终结符的产生式 若这使得以某一非终结符为左部的所有产生式都被删除,则设置该终结符不能产生空
std::set<char> now_chars; // 现在的非终结符
for (auto it = pro.begin(); it != pro.end(); ++it)
{
now_chars.insert(it->first);
for (char c : it->second)
{
// 判断是否是非终结符 非终结符只包含26个大写字母
if (!(((int)c >= 'A') && (int)c <= 'Z'))
{
to_remove.push_back(it);
break;
}
}
}
for (auto it : to_remove)
{
pro.erase(it);
}
to_remove.clear();
// 删除所有还在的非终结符
for (auto& it : pro)
{
now_chars.erase(std::find(now_chars.begin(), now_chars.end(), it.first));
}
// 剩下的非终结符, 以其为左部的所有产生式都被删除 其不能产生空
for (const char& c : now_chars)
{
m_toempty.insert(std::make_pair(c, false));
}
// 至此 所有产生式的右部都是非终结符(或其集合)
// 进行循环
while (true)
{
bool ischange = false; // 经过下面两个规则后 是否有变动
// 运用规则:扫描产生式右部的每一符号,若所扫描到的非终结符在数组中对应的标志是“真”,则删去该非终结符,
// 若这时产生式右部为空,则将产生式左部的非终结符在数组中对应的标志改为“是”,并删除该非终结符为左部的所有产生式
for (auto it = pro.begin(); it != pro.end(); ++it)
{
size_t flag = 0; // 用这个变量来判断右部是否都能产生空
for (char& c : it->second)
{
// 产生空集合要包含该产生式(应该包含) 并且要能产生@(空)
if (!(m_toempty.count(c) && m_toempty[c]))
{
flag++;
}
}
if (flag == it->second.size())
{
m_toempty.insert(std::make_pair(it->first, true));
ischange = true;
to_remove.push_back(it);
}
}
// 真正删除
for (auto it : to_remove)
{
pro.erase(it);
}
to_remove.clear();
// 运用规则:若所扫描到的非终结符在数组中对应的标志是“否”,则删去该产生式,
// 若这使产生式左部非终结符的有关产生式都被删去,则把数组中该非终结符对应的标志改为“否”
std::set<char> now_chars2; // 现在的非终结符
for (auto it = pro.begin(); it != pro.end(); ++it)
{
now_chars2.insert(it->first);
// 判断标志
if (!m_toempty[it->first])
{
to_remove.push_back(it);
}
}
for (auto it : to_remove)
{
pro.erase(it);
}
to_remove.clear();
// 删除所有还在的非终结符
for (auto& it : pro)
{
now_chars2.erase(std::find(now_chars2.begin(), now_chars2.end(), it.first));
}
// 剩下的非终结符, 以其为左部的所有产生式都被删除 不能产生空
for (const char& c : now_chars2)
{
ischange = true;
m_toempty.insert(std::make_pair(c, false));
}
// 如果没有改变 退出
if (!ischange)
{
break;
}
}
}
// 计算first集
// 为了简便 抽出来的函数
void addFirst(const char& dest, const char& from, Product* p)
{
// 如果不是非终结符 直接加入就好
std::string str;
str.push_back(dest);
if (!(from >= 'A' && from <= 'Z'))
{
p->m_first[str].insert(from);
return;
}
// 如果是非终结符 将其first集合加入左部
std::string str2;
str2.push_back(from);
for (auto& it : p->m_first[str2])
{
p->m_first[str].insert(it);
}
}
// 真正的计算过程
void Product::toFirst()
{
// 首先对非终结符求first集合
// 运用规则:若X为非终结符,且有产生式X->a…,a为终结符,则a属于first(X)
// 和规则:若X为非终结符且X->@,则@属于first(X)
for (auto& it : m_productions)
{
// 检查右部第一个是不是非终结符或@(空) (不是终结符那就是非终结符)
if ((it.second[0] == '@') || (!(it.second[0] >= 'A' && (it.second[0] <= 'Z'))))
{
std::string str;
str.push_back(it.first);
m_first[str].insert(it.second[0]);
}
}
// 运用规则:对于每一个产生式右部为非终结符...的产生式 应该将其的first集合加入左部非终结符的first集合
// 如果其能产生空 应当将其后面{-->如果仍是非终结符 递归前面 -->如果是非终结符 加入左部非终结符的first集合}
while (true)
{
bool ischange = false;
for (auto& it : m_productions)
{
// 判断first集合大小是否有变化
std::string ss;
ss.push_back(it.first);
size_t size = m_first[ss].size();
for (auto& it2 : it.second)
{
std::string str;
str.push_back(it2);
if (!m_first.count(str))
{
// first为空的非终结符
if (it2 >= 'A' && it2 <= 'Z')
{
break;
}
// 非终结符
else
{
addFirst(it.first, it2, this);
break;
}
}
for (auto& it3 : m_first[str])
{
// 将其fisrt集合所有除了为空的值加入左部
if (it3 != '@')
addFirst(it.first, it3, this);
}
// 判断其能否推出空 若能,继续
if (!m_toempty[it2])
{
break;
}
}
// 判断其产生是否都能产生空 若能 加入空
bool isempty = true;
for (auto& it2 : it.second)
{
if (!(m_toempty.count(it2) && m_toempty[it2]))
{
isempty = false;
break;
}
}
if (isempty)
{
addFirst(it.first, '@', this);
}
size_t size1 = m_first[ss].size();
if (size != size1)
{
ischange = true;
}
}
if (!ischange) break;
}
// 至此 对于所有非终结符求其first集合结束 接下来求右部串的first集合
// 对于串本身 如果字符-->是非终结符X 则将X的first集合(除了空(@))加入串的first集合
// 若X的first集合包含空(@) 则判断串的下一个字符 -->若字符不是非终结符 那么将该终结符加入串的first集合 退出
// 如果X的first集包含空并且X是串的最后一个字符 给串加入空
for (auto& it : m_rs)
{
for (auto& it2 : it)
{
// 如果是非终结符
if (it2 >= 'A' && it2 <= 'Z')
{
std::string str;
str.push_back(it2);
for (auto it3 : m_first[str])
{
if (it3 != '@')
{
m_first[it].insert(it3);
}
}
// 如果该非终结符的first集合包含空(@)就继续 否则退出
if (!m_first[str].count('@'))
{
break;
}
else if (it[it.size() - 1] == it2)
{
m_first[it].insert('@');
}
}
// 不是非终结符
else
{
m_first[it].insert(it2);
break;
}
}
}
}
// 计算follow集
void Product::toFollow()
{
// 对于follow集 只求非终结符
// 定义如下:
// 设G=(VT, VN, S, P)是上下文无关文法,A属于非终结符,S是开始符号,那么A的后跟字符串的首字符集定义为:
// (1) FOLLOW(A)={a|S-*->uAB且a属于终结符, a属于FIRST(B), u属于终结符*, B属于符号*
// (2) 若S-*->uAB且B-->空,则#属于FOLLOW(A)
// 首先将结束符号#加入文法开始符号中
m_follow[m_start].insert('#');
while (true)
{
bool ischange = false;
// 扫描产生式右部
for (auto& it : m_productions)
{
// 从左向右扫描 找第一个非终结符X 看其后面是否有值-->若有:若是--->非终结符 将first集除空以外元素所有加入follow(X)
// 若该非终结符能推出空且为右部最后一个符号 则将follow(左部)加入follow(X)
// --->非终结符 将其自己加入follow(X)
// -->没有 将follow(左部)加入follow(X)
// 这里有个问题 若产生式为X->aBCDE CD均能产生空 则first(E)也应该加入follow(B)
for (uint32_t i = 0; i <= it.second.size(); ++i)
{
// 计算现在的元素的大小
size_t size;
// 找到第一个非终结符
if (it.second[i] >= 'A' && it.second[i] <= 'Z')
{
size = m_follow[it.second[i]].size();
// 判断是不是右部串最后一个符号
if (i == it.second.size() - 1)
{
// 如果是 则将follow(左部)加入follow(X)
for (auto& it2 : m_follow[it.first])
{
m_follow[it.second[i]].insert(it2);
}
}
// 若不是 判断下一个是不是非终结符
else
{
uint32_t n = i;
while (true)
{
char N = it.second[n + 1]; // 当前字符
// 是 则将当前字符的first集中除了@(空)以外的元素加入c元素的follow集
if (N >= 'A' && N <= 'Z')
{
std::string str;
str.push_back(N);
for (auto& it2 : m_first[str])
{
if (it2 != '@')
m_follow[it.second[i]].insert(it2);
}
// 判断能否产生空并且为右部最后一个元素 若能且是 则将follow(左部)加入follow(前个元素)
if (m_first[str].count('@') && (n + 1) == it.second.size() - 1)
{
for (auto& it2 : m_follow[it.first])
{
m_follow[it.second[i]].insert(it2);
}
break;
}
// 若能判断空并且不为右部最后一个元素 //ppt并未给出说明 应该是要重复判断下一个元素
else if (m_first[str].count('@'))
{
n++;
}
else
{
break;
}
}
// 不是 将自己加入follow(前个元素)
else
{
m_follow[it.second[i]].insert(N);
break;
}
}
}
if (size != m_follow[it.second[i]].size())
{
ischange = true;
}
}
}
}
if (!ischange) break;
}
}
// 计算select集
void Product::toSelect()
{
// 定义如下:
// 给定上下文无关文法的产生式A->右部
// (1) 若右部不能产生空,则SELECT(A->右部)=FIRST(右部)
// (2) 若右部能产生空,则SELECT(A->右部)=(FIRST(右部)-{@})并上FOLLOW(A)
for (auto& it : m_productions)
{
std::string str;
str.push_back(it.first);
str += "->";
str += it.second;
// 能产生空
if (m_first[it.second].count('@'))
{
for (auto& it2 : m_first[it.second])
{
if (it2 != '@')
m_select[str].insert(it2);
}
for (auto& it2 : m_follow[it.first])
{
m_select[str].insert(it2);
}
}
else
{
for (auto& it2 : m_first[it.second])
{
m_select[str].insert(it2);
}
}
}
}
// 判断是否是LL1文法
bool Product::isLL1()
{
// 必须在调用完毕removeLR、toEmpty、toFirst、toFollow、toSelect后才能判断是否是LL1文法
// 根据定义 满足具有相同左部的产生式的select集的交集为空的文法才是LL1文法
for (auto& it : m_nt)
{
// 找到所有以it为左部的产生式并看看这些产生式的select是否有重复的
std::set<char> tmp; // 如果有相同左部产生式不能向set放入集合 说明重复了 就不是LL1文法了
for (auto& it2 : m_select)
{
if (it2.first[0] == it)
{
for (auto& it3 : it2.second)
{
auto it4 = tmp.insert(it3);
// 插入失败
if (!it4.second)
{
return false;
}
}
}
}
tmp.clear();
}
// 所有的都检测完毕 返回成功
return true;
}
// 计算预测分析表
void Product::buildPat()
{
// 定义的求出预测分析表方法
// 1.对文法G的每个产生式A->右部执行第二步和第三步;
// 2.对每个终结符a属于FIRST(右部),把A->右部加至m_pat[A,a]中
// 3.若@(空)属于FIRST(右部),则对任何b属于FOLLOW(A)把A->右部加至m_pat[A,b]中
// 4.把所有无定义的m_pat[A,a]标上“出错标志”
// 在这里直接使用select集求
// 对于A->XYZ的select集xyz
// m_pat[A-x]、m_pat[A-y]、m_pat[A-z]都填上A->XYZ
// 对剩余的填上出错标志 在这里由于不想求全部的非终结符 就不设置了 这样的话碰到空就是出错
// 首先要求必须是LL1文法
if (!isLL1())
{
std::cerr << "it's not the LL1 grammar" << std::endl;
exit(2);
}
for (auto& it : m_select)
{
for (auto& it2 : it.second)
{
m_pat.insert(std::make_pair(std::pair<char, char>(it.first[0], it2), it.first));
}
}
}
// 完成所有动作 就是调用上面所有内容
void Product::finish()
{
// 左递归消除失败就不用继续了
if (!this->removeLR())
{
std::cerr << "左递归消除失败 程序结束" << std::endl;
return;
}
// 顺序完成各种计算
this->toEmpty();
this->toFirst();
this->toFollow();
this->toSelect();
this->buildPat();
}
// 匹配给定句子
void Product::matchSentence(const std::string& file)
{
std::ifstream is(file);
if (!is.is_open())
{
std::cout << "open file error... filename:" << file << std::endl;
}
// 读取输入
std::string sentance;
std::getline(is, sentance);
is.close();
// 以sentence充当句子栈
// 为方便输出 仍以string充当符号栈
std::string sign; // 符号栈
// 句子要逆序入栈
std::reverse(sentance.begin(), sentance.end());
// 先将结束符和文法开始符号入栈
sign.push_back('#');
sign.push_back(m_start);
// 打开文件 准备追加内容
std::ofstream os;
os.open(file, std::ios::app);
// X为sign的栈顶符号 x为sentence的栈顶符号
// 当X==x时 同时出栈
// 否则将m_pat[X,x]逆序入sign栈
os << "\n栈内容\t栈顶符号\t当前句子\t匹配的产生式\n";
while (true)
{
if (sign[sign.size() - 1] == sentance[sentance.size() - 1])
{
// 判断是否结束
if (sign.empty() && sentance.empty())
{
os << "分析结束 匹配完成 成功!";
std::cout << "Matching completed, please go to the " << file << " to view" << std::endl;
break;
}
else
{
std::string str = sentance;
std::reverse(str.begin(), str.end());
os << sign << "\t" << sign[sign.size() - 1] << "\t" << str << "\t"
<< "退栈\n";
sign.pop_back();
sentance.pop_back();
}
}
else
{
std::string strs = sentance;
std::reverse(strs.begin(), strs.end());
std::pair<char, char> pair(sign[sign.size() - 1], sentance[sentance.size() - 1]);
std::string str = m_pat[pair];
os << sign << "\t" << sign[sign.size() - 1] << "\t" << strs << "\t" << str << "\n";
// 如果为空 说明出错
if (str.empty())
{
os << "分析结束 匹配错误 失败!";
std::cerr << "match error" << std::endl;
break;
}
str = str.substr(3);
// 将符号栈最后一位出栈
sign.pop_back();
// 如若不是产生@(空) 将对应的产生式逆序加入
if (str != "@")
{
std::reverse(str.begin(), str.end());
sign += str;
}
}
}
os.close();
}
int main()
{
Product t("C://Mine//x.txt");
t.finish();
t.removeLR();
t.printEmpty();
t.printFirst();
t.printFollow();
t.printSelect();
t.printPat();
t.matchSentence("C://Mine//c.txt");
return 0;
}















 5061
5061











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









