







前言
据说天猫双十一交易额造假,交易额数据可以用二次或三次多项式完美拟合,看到这个后我觉得可以试一试。那么说干就干。我们用sklearn多项式回归来拟合,只做三次多项式,二次多项式也是一样,只要去掉三次项就可以了,后面会帖出完整代码实现
构造数据
要拟合的值就是交易额数据,多少亿多少亿,自变量我们就用年份,数据中应该包含三次项,二次项,一次项和常数项,因为年份数字比较大,都给他减去一个2000,让他只保留后面的两位,这样不影响结果
data = [[2009, 0.5], [2010, 9.36], [2011, 52.00],
[2012, 191.00], [2013, 350.00], [2014, 571.00],
[2015, 912.00], [2016, 1207.00], [2017, 1602.69],
[2018, 2135.00]]
# 构造三次多项式训练集
X = [[(data[i][0]-2000)**3, (data[i][0]-2000)**2, data[i][0]-2000, 1] for i in range(len(data))]
Y = [[data[i][1]] for i in range(len(data))]
训练
// 导入sklearn包
from sklearn.linear_model import LinearRegression
regression = LinearRegression()
regression.fit(X, Y)
看下效果
我们要看下使用模型预测的09到18年的数据与实际的相似程度,并用plt图表给他显示出来
# 真实值
data_y = [data[i][1] for i in range(len(data))]
data_x = [data[i][0] for i in range(len(data))]
# 预测植
test = [[d**3, d**2, d, 1] for d in range(9, 20)]
predict = regression.predict(test)
show_x = [d[2] for d in test]
show_y = [d[0] for d in predict]
# 使用plot显示图形
plt.scatter(np.array(data_x), data_y, marker='x', color='red', s=40, label='history')
plt.plot(np.array(show_x)+2000, show_y, color='green', label='predict')
plt.legend(loc='best')
plt.show()
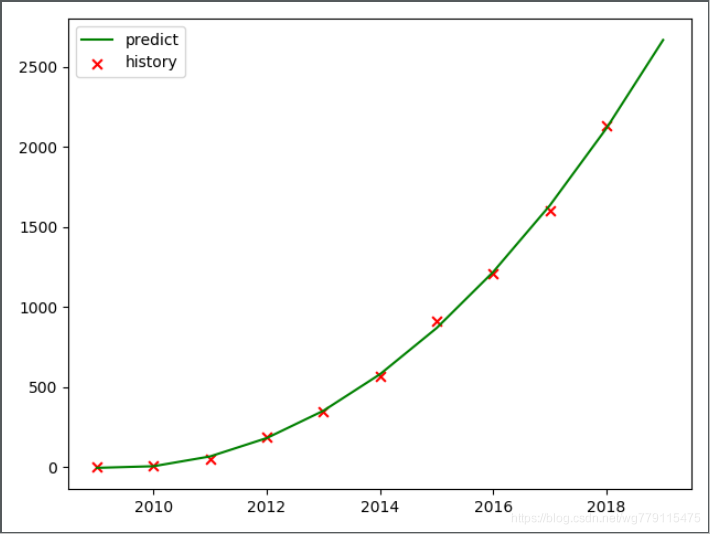
红叉是真实的交易值,绿色曲线是我们拟合的三次多项式曲线,我们看到,用三次多项式确实拟合的不错!
另外,当把预测值和真实值和误差做加和,你会发现他是一个接近于0的数,这说明天猫在交易额上加了一个均值为0的随机数
subtract = np.array(Y) - np.array(predict[0:-1])
print('误差加和:', np.sum(subtract))

完整代码
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
import numpy as np
data = [[2009, 0.5], [2010, 9.36], [2011, 52.00],
[2012, 191.00], [2013, 350.00], [2014, 571.00],
[2015, 912.00], [2016, 1207.00], [2017, 1602.69],
[2018, 2135.00]]
data_y = [data[i][1] for i in range(len(data))]
data_x = [data[i][0] for i in range(len(data))]
# 构造三次多项式训练集
X = [[(data[i][0]-2000)**3, (data[i][0]-2000)**2, data[i][0]-2000, 1] for i in range(len(data))]
Y = [[data[i][1]] for i in range(len(data))]
regression = LinearRegression()
regression.fit(X, Y)
print('多项式系数:', regression.coef_)
test = [[d**3, d**2, d, 1] for d in range(9, 20)]
predict = regression.predict(test)
show_x = [d[2] for d in test]
show_y = [d[0] for d in predict]
subtract = np.array(Y) - np.array(predict[0:-1])
print('误差加和:', np.sum(subtract))
print(subtract)
print(abs(np.sum(subtract)) < 0.000001)
print('方差:', subtract.T.dot(subtract)) # 方差
plt.scatter(np.array(data_x), data_y, marker='x', color='red', s=40, label='history')
plt.plot(np.array(show_x)+2000, show_y, color='green', label='predict')
plt.legend(loc='best')
plt.show()














 6423
6423











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









