







不同点 顺序表 链表
存储空间上 物理空间与逻辑空间一样连续 逻辑空间上连续,物理空间上不一定连续
时间复杂度 通过下标访问可以做到O(1) 要通过头链表一直访问到直到到达目标节点,所以为O(N)
数据的插入和删除 只能做到尾插和尾删(其他情况要移动链表,效率低下) 可以随意位置插入和删除
容量问题 容量不够会扩充,会出现空间浪费 ,扩容也会产生消耗 随数据量增加容量数量,不存在容量问题
缓存利用率 高 低
为什么顺序表缓存利用率高,而链表缓存利用率低?
结论:
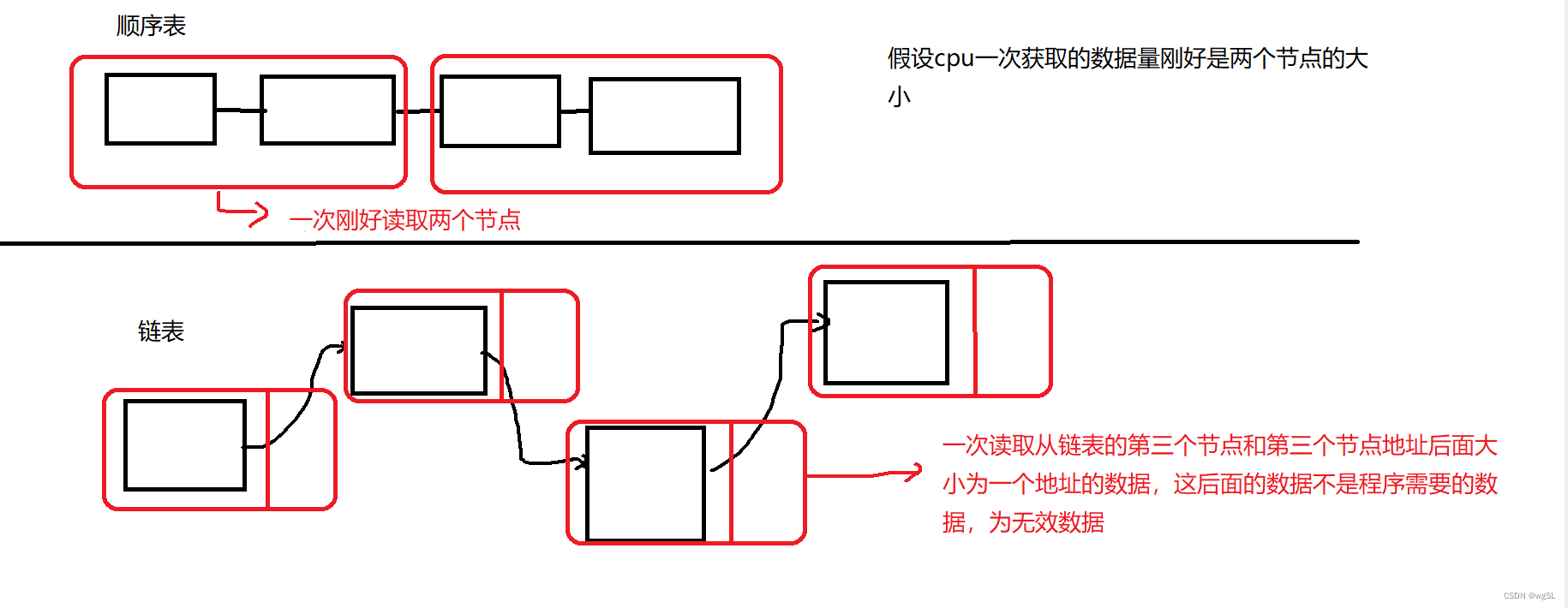
顺序表因为物理空间的连续,一次读取的数据量都是顺序表内的数据(除了顺序表的末尾处),那么当从内存中的数据放入缓存时,这其中的数据都是顺便表的数据(末节点不一定),所以这时缓存内的数据的利用率高
而链表因为物理空间上几乎不肯能连续,因此在一次访问数据中,内存数据放入缓存时,会在缓存中放入程序额外的数据,造成缓存数据污染,因此缓存利用率低
原因讲解:
这里不讨论硬件方面的基本认识,若有这方面不理解的可以观看下图
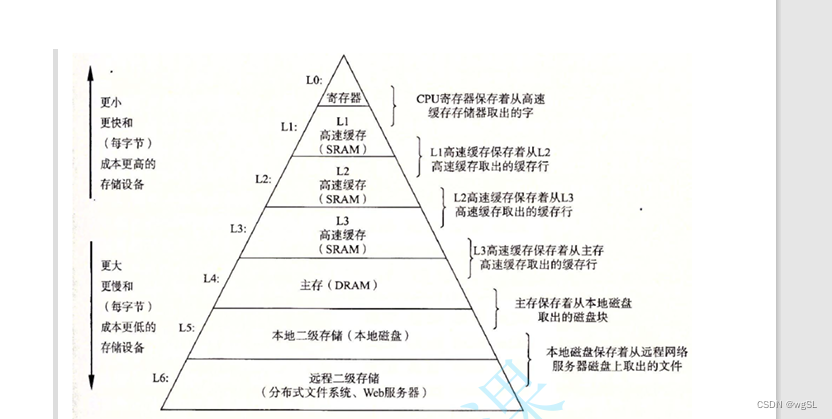
当程序开启时,程序所对应的数据会被cpu划分一段区域,这个区域被称为叫内存,存放着该区域的数据。之后,当cpu要获取程序数据进行运算的时候,cpu会将其中所要频繁用到的数据放入到距离cpu更进一步的区域缓存中,这样可以让cpu更快的获取频繁的数据。之后cpu再将缓存的数据放入到寄存器中(有一些特定的数据是不会放入寄存器的,会直接从内存或者缓存读取),之后cpu计算完数据后,在将数据返回给内存中。
cpu对于数据的获取是先访问缓存内部是否有对应的数据,若有则从缓存中读取数据进入cpu进行计算(这个过程也被称叫缓存命中),若缓存内未有cpu所需要的数据,那么cpu就会让内存的数据放入到缓存中,再从缓存中访问数据(这个过程也叫缓存不命中)
基于cpu每次所能处理的数据有限(处理的数据量分别是一次读取64位字节的×64架构和一次读取32位的×86架构),其读取数据的方式是内存寻址,会找到所需数据的地址处,一次性从获取地址处到对应读取字节量的数据量。
顺序表因为物理空间的连续,一次读取的数据量都是顺序表内的数据(除了顺序表的末尾处),那么当从内存中的数据放入缓存时,这其中的数据都是顺便表的数据(末节点不一定),所以这时缓存内的数据的利用率高
而链表因为物理空间上几乎不肯能连续,因此在一次访问数据中,内存数据放入缓存时,会在缓存中放入程序额外的数据,造成缓存数据污染,因此缓存利用率低















 891
891











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









