







BeanFactoryPostProcessors调用时机
前面的文章讲到通过BeanFactoryPostProcessors来扩展spring的方法,那么BeanFactoryPostProcessors究竟是什么时候执行到的呢?本文会通过分析容器的初始化流程来讲到BeanFactoryPostProcessors的调用的时机
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(ConsumerConfiguration.class);
这么一行代码即完成了容器的初始化,之后便可以对容器进行使用,这一行代码的底层完成了哪些复杂的操作呢?
我们先点进构造方法
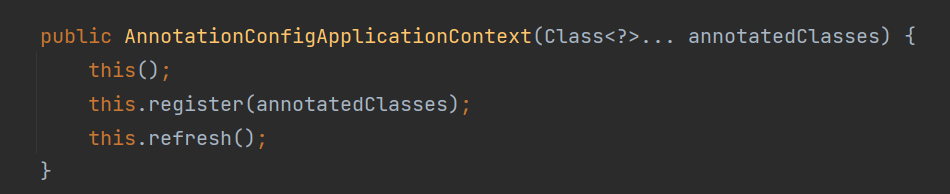
this()方法详解

前面文章总结过这部分的执行过程,此处只做简单的总结
这里面实例化了两个对象 reader 和 scanner
reader 作用:
1、把context.register()的类变成BD,并放入容器
2、把几个固定的postProcessor包装成BD,并放入容器
scanner作用:
1、context.scan() 对指定包进行扫描
2、被继承进行个性化扫描,其中ConfigurationClassPostProcessor中实现了个性化扫描
this.register(annotatedClasses)方法详解

最终由这个方法进行执行,主要的作用就是创建了一个BD,然后注册到容器中去
this.refresh()方法详解
这个是一个关键的方法,spring容器的初始化都是在这里完成的
public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
// Prepare this context for refreshing.
// 对AbstractApplicationContext中使用到的组件进行初始化
prepareRefresh();
// Tell the subclass to refresh the internal bean factory.
// 获取到beanFactory,这个beanFactory是在AbstractApplicationContext子类的中创建的,这时候拿出来是在AbstractApplicationContext类可以用
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
// Prepare the bean factory for use in this context.
// 执行了beanFactory中的一些方法,为了对beanFactory和用到的组件初始化
prepareBeanFactory(beanFactory);
try {
// Allows post-processing of the bean factory in context subclasses.
// 这个方法没实现,是要交给子类实现的,AnnotationConfigApplicationContext也没实现
// 其他子类有实现的,看注释意思为允许对beanFactory后置处理,应该是为下一步做的基本操作
postProcessBeanFactory(beanFactory);
// Invoke factory processors registered as beans in the context.
// 执行beanFactory后置处理
// 包含BeanFactoryPostProcessor和BeanDefinitionRegistryPostProcessor
invokeBeanFactoryPostProcessors(beanFactory);
// Register bean processors that intercept bean creation.
// 注册beanPostProcessors 把bdMap中的beanPostProcessors注册到
// 两种方式注册BeanPostProcessors
// 1、beanFactor.addBeanPostProcessor 注册到beanFactor.beanPostProcessors
// 2、注册进bdMap的BeanPostProcessor
registerBeanPostProcessors(beanFactory);
// Initialize message source for this context.
// 国际化用的
initMessageSource();
// Initialize event multicaster for this context.
// 事件相关的
initApplicationEventMulticaster();
// Initialize other special beans in specific context subclasses.
// 这个方法没实现,是要交给子类实现的,初始化特殊的bean,AnnotationConfigApplicationContext没实现
onRefresh();
// Check for listener beans and register them.
// 也是事件相关的
registerListeners();
// Instantiate all remaining (non-lazy-init) singletons.
// 实例化在这里完成
finishBeanFactoryInitialization(beanFactory);
// Last step: publish corresponding event.
finishRefresh();
}
我们重点看invokeBeanFactoryPostProcessors方法,BeanFactoryPostProcessors就是在这里执行完的,我们可以先简单的分析一下
invokeBeanFactoryPostProcessors执行之前都是容器的初始化方法,就是对容器中的一些组件进行初始化,可以认为都是一些无关紧要的事情,这么看来容器做的第一件重要的事情就是invokeBeanFactoryPostProcessors,那么为什么要把invokeBeanFactoryPostProcessors放在第一位来完成呢?
我们根据BeanFactoryPostProcessors的作用就可以知道,BeanFactoryPostProcessors是对容器进行增强的,所以要放在最开始执行,之后才能执行bean有关的操作,如果放在bean后面执行,那就达不到想要的效果了。
我们来看代码

这里有一个需要注意的点,看到这里传进来了两个参数,一个是容器本事,一个是通过getBeanFactoryPostProcessors获取到的BeanFactoryPostProcessors列表,这个列表中存放着通过AnnotationConfigApplicationContext#addBeanFactoryPostProcessor注册进来的BeanFactoryPostProcessors,除了这种方法,还能通过往容器中添加BD,BD的class是BeanFactoryPostProcessors的方法进行注册,那样的话就会注册到bdmap中
为什么要有这两种方式呢?暂时还没有找到原因,如果你知道其中的原因,欢迎留言讨论。
继续往后跟

这个方法最终完成了BeanFactoryPostProcessors的调用
BeanFactoryPostProcessors调用顺序
我认为invokeBeanFactoryPostProcessors里面最重要的逻辑就是分批调用,为什么分批调用?我认为有两个原因,如果不准确欢迎留言讨论
1、有些BeanFactoryPostProcessors需要顺序执行
2、为了区分BeanFactoryPostProcessor和BeanDefinitionRegistryPostProcessor
public static void invokeBeanFactoryPostProcessors(
ConfigurableListableBeanFactory beanFactory, List<BeanFactoryPostProcessor> beanFactoryPostProcessors) {
// Invoke BeanDefinitionRegistryPostProcessors first, if any.
// 这个集合用来保存执行完的processedBeans,为什么要存储执行完的?
// 递归执行的时候防止重复
Set<String> processedBeans = new HashSet<>();
if (beanFactory instanceof BeanDefinitionRegistry) {
BeanDefinitionRegistry registry = (BeanDefinitionRegistry) beanFactory;
// 存储所有的BeanFactoryPostProcessor
List<BeanFactoryPostProcessor> regularPostProcessors = new ArrayList<>();
// 存储所有的BeanDefinitionRegistryPostProcessor
List<BeanDefinitionRegistryPostProcessor> registryProcessors = new ArrayList<>();
// 执行所有通过content.addBeanFactoryPostProcessor注册进来的PostProcessor 这种PostProcessor不进BDMap,不进单例池
// 如果是BeanDefinitionRegistryPostProcessor,立刻执行postProcessBeanDefinitionRegistry方法,并存processedBeans和registryProcessors中
// 如果是BeanFactoryPostProcessor 直接存储到regularPostProcessors中
for (BeanFactoryPostProcessor postProcessor : beanFactoryPostProcessors) {
if (postProcessor instanceof BeanDefinitionRegistryPostProcessor) {
BeanDefinitionRegistryPostProcessor registryProcessor =
(BeanDefinitionRegistryPostProcessor) postProcessor;
registryProcessor.postProcessBeanDefinitionRegistry(registry);
registryProcessors.add(registryProcessor);
}
else {
regularPostProcessors.add(postProcessor);
}
}
// Do not initialize FactoryBeans here: We need to leave all regular beans
// uninitialized to let the bean factory post-processors apply to them!
// Separate between BeanDefinitionRegistryPostProcessors that implement
// PriorityOrdered, Ordered, and the rest.
// 为了分批执行创建的,一次执行一批,把每一批放这个里面
List<BeanDefinitionRegistryPostProcessor> currentRegistryProcessors = new ArrayList<>();
// First, invoke the BeanDefinitionRegistryPostProcessors that implement PriorityOrdered.
// 取出来容器中BDMap中的所有BeanDefinitionRegistryPostProcessor
// 这里通常只有一个ConfigurationClassPostProcessor,它完成了扫描
String[] postProcessorNames =
beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
}
}
sortPostProcessors(currentRegistryProcessors, beanFactory);
registryProcessors.addAll(currentRegistryProcessors);
// 这里完了扫描 这里的扫描是指解析配置类(解析配置类中的各种注解)
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
currentRegistryProcessors.clear();
/**
* 下面又获取并执行了1+n遍BeanDefinitionRegistryPostProcessor,因为上一步会扫描进来BD
* 为什么获取了1+n遍?
* 第一遍是执行了所有实现了Ordered的BeanDefinitionRegistryPostProcessor(去掉上面执行完的)
* 其余的n编执行了剩余的所有Ordered的BeanDefinitionRegistryPostProcessor
* 因为每一次执行都可能有新的BeanDefinitionRegistryPostProcessor进来,所以执行n编
*/
// Next, invoke the BeanDefinitionRegistryPostProcessors that implement Ordered.
postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
if (!processedBeans.contains(ppName) && beanFactory.isTypeMatch(ppName, Ordered.class)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
}
}
sortPostProcessors(currentRegistryProcessors, beanFactory);
registryProcessors.addAll(currentRegistryProcessors);
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
currentRegistryProcessors.clear();
// Finally, invoke all other BeanDefinitionRegistryPostProcessors until no further ones appear.
boolean reiterate = true;
while (reiterate) {
reiterate = false;
postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
if (!processedBeans.contains(ppName)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
reiterate = true;
}
}
sortPostProcessors(currentRegistryProcessors, beanFactory);
registryProcessors.addAll(currentRegistryProcessors);
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
currentRegistryProcessors.clear();
}
// Now, invoke the postProcessBeanFactory callback of all processors handled so far.
// 执行BeanDefinitionRegistryPostProcessor的postProcessBeanFactory接口
// 执行BeanFactoryPostProcessor(只包含content.addBeanFactoryPostProcessor进来的)的postProcessBeanFactory接口
invokeBeanFactoryPostProcessors(registryProcessors, beanFactory);
invokeBeanFactoryPostProcessors(regularPostProcessors, beanFactory);
}
else {
// Invoke factory processors registered with the context instance.
invokeBeanFactoryPostProcessors(beanFactoryPostProcessors, beanFactory);
}
// Do not initialize FactoryBeans here: We need to leave all regular beans
// uninitialized to let the bean factory post-processors apply to them!
// 这里开始执行BeanFactoryPostProcessor 这个地方不用递归是因为这个时候已经不能注册BD了,BDMap里面不会有新增的BeanFactoryPostProcessor
String[] postProcessorNames =
beanFactory.getBeanNamesForType(BeanFactoryPostProcessor.class, true, false);
// Separate between BeanFactoryPostProcessors that implement PriorityOrdered,
// Ordered, and the rest.
List<BeanFactoryPostProcessor> priorityOrderedPostProcessors = new ArrayList<>();
List<String> orderedPostProcessorNames = new ArrayList<>();
List<String> nonOrderedPostProcessorNames = new ArrayList<>();
// 给所有的BeanFactoryPostProcessor(不包含content.addBeanFactoryPostProcessor进来的)分类
for (String ppName : postProcessorNames) {
if (processedBeans.contains(ppName)) {
// skip - already processed in first phase above
}
else if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {
priorityOrderedPostProcessors.add(beanFactory.getBean(ppName, BeanFactoryPostProcessor.class));
}
else if (beanFactory.isTypeMatch(ppName, Ordered.class)) {
orderedPostProcessorNames.add(ppName);
}
else {
nonOrderedPostProcessorNames.add(ppName);
}
}
// 分三类执行
// 1、实现了PriorityOrdered的
// First, invoke the BeanFactoryPostProcessors that implement PriorityOrdered.
sortPostProcessors(priorityOrderedPostProcessors, beanFactory);
invokeBeanFactoryPostProcessors(priorityOrderedPostProcessors, beanFactory);
// 2.实现了Ordered并且没实现Ordered的
// Next, invoke the BeanFactoryPostProcessors that implement Ordered.
List<BeanFactoryPostProcessor> orderedPostProcessors = new ArrayList<>(orderedPostProcessorNames.size());
for (String postProcessorName : orderedPostProcessorNames) {
orderedPostProcessors.add(beanFactory.getBean(postProcessorName, BeanFactoryPostProcessor.class));
}
sortPostProcessors(orderedPostProcessors, beanFactory);
invokeBeanFactoryPostProcessors(orderedPostProcessors, beanFactory);
// 3、没实现PriorityOrdered和Ordered的
// Finally, invoke all other BeanFactoryPostProcessors.
List<BeanFactoryPostProcessor> nonOrderedPostProcessors = new ArrayList<>(nonOrderedPostProcessorNames.size());
for (String postProcessorName : nonOrderedPostProcessorNames) {
nonOrderedPostProcessors.add(beanFactory.getBean(postProcessorName, BeanFactoryPostProcessor.class));
}
invokeBeanFactoryPostProcessors(nonOrderedPostProcessors, beanFactory);
// Clear cached merged bean definitions since the post-processors might have
// modified the original metadata, e.g. replacing placeholders in values...
beanFactory.clearMetadataCache();
}
首先我们给BeanFactoryPostProcessor进行一下分类
第一类:不进bdmap的BeanFactoryPostProcessor
第二类:进bdmap的BeanFactoryPostProcessor
第三类:不进bdmap的BeanDefinitionRegistryPostProcessor
第四类:进bdmap的BeanDefinitionRegistryPostProcessor
还有一个分类维度是是否添加了顺序注解的,我们就不放在大类里面进行区分
最后我们总结一下BeanFactoryPostProcessor的调用顺序
1、执行第三类
2、执行第四类中实现PriorityOrdered接口的,但是当前只会有一个ConfigurationClassPostProcessor,它完成了扫描
3、执行第四类所有实现了Ordered的BeanDefinitionRegistryPostProcessor
4、递归执行第四类所有没实现Ordered的和步骤二、三中扫描出来的BeanDefinitionRegistryPostProcessor
————————————————————————————
以上执行的都是postProcessBeanDefinitionRegistry方法
————————————————————————————
以下执行的都是postProcessBeanFactory方法
————————————————————————————
5、执行第一类、第三类的postProcessBeanFactory方法
6、执行第二类、第四类中实现PriorityOrdered注解的
7、执行第二类、第四类中实现Ordered并且没实现PriorityOrdered的
8、执行第二类、第四类中没实现Ordered并且没实现PriorityOrdered的















 706
706











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









