









CONTENT:
* AMR简介
* AMR 话音质量评定
* AMR 文件结构解析
* AMR 帧结构解析
* AMR 帧读取算法
* AMR 解码原理及流程
* AMR 模式选择自适应机制
一、AMR 简介
基于新的网络和新的要求,无论是从节省传输频带资源,还是保持线路通信的高效率等方面来看,研究采用各种可变速率语音编码技术的系统都有重要意义。目前为了适应此需要提出了AMR(Adaptive Multi-rate) 的概念,即自适应多速率语音编码器,主要用于移动设备的音频,压缩比比较大,但相对其他的压缩格式质量比较差,由于多用于人声通话。AMR又分为两种,一种是AMR-NB(AMR-NarrowBind),语音带宽范围:300-3700Hz,8KHz采样频率;另外一种是AMR-WB(AMR WideBand),语音带宽范围50-7000Hz,16KHz采样频率。但考虑语音的短时相关性,每帧长度均为20ms。这两种编码器根据带宽的要求虽然选用了不同的速率,但有异曲同工之处.
(1)AMR-NB
AMR的采样频率为8KHz,每20ms编码一帧,每个帧中包含160个语音样点。
AMR采用的是基于代数码激励线性预测(ACELP)的编码模式,编码端提取ACELP模型参数(线性预测系数,自适应码本和固定码本索引及增益),解码端接收到数据然后根据这些参数从新合成语音。
TD-SCDMA中AMR-NB的实现。此编码器运用了代数码本线性预测(ACELP)混合编码方式,也就是数字语音信号中既包括若干语音特征参数又包括部分波形编码信息,再运用这些特征信息重新合成语音信号的过程。控制这些参数的提取数目,根据速率要求对信息进行取舍而得到了以下8种速率,混合组成如表一所示的自适应语音编码器。如模式AMR_12.20就提取出244比特的参数信息,而模式AMR_4.70却只提取了95比特信息。根据这些比特所含的信息量可以将其分为3类比特class 0,1和2。在信道编码时class 0和1都将会使用循环冗余校验码进行差错检验,对于class 2则根据上一帧进行恢复。
表一 : AMR 编码器的编码速率
| 编码模型 | 编码器的比特速率 | 编码模型 | 编码器的比特速率 |
| AMR_12.2 | 12,20kbit/s(GSM_EFR) | AMR_5.90 | 5,90 kbit/s
|
| AMR AMR | 10,20 kbit/s | AMR_5.15 | 5,15 kbit/s |
| AMR_7.95 | 7,95 kbit/s | AMR_4.75 | 4,75 kbit/s |
| AMR_7.40 | 7,40kbit/s (IS-641) | AMR_SID | 1,80 kbit/s (无语音信息传输) |
| AMR_6.70 | 6,70kbit/s (PDC-EFR) |
|
|
包括低速率的背景噪声编码模式(DTX)1.80kb/s
( 2)AMR-WB
AMR-WB”全称为“Adaptive Multi-rate – Wideband”,即“自适应多速率宽带编码”,采样频率为
16kHz,是一种同时被国际标准化组织ITU-T和3GPP采用的宽带语音编码标准,也称为G722.2标准。
AMR-WB 支持9种不同的编码方式:6.6kb/s 8.85kb/s 12.65kb/s 14.25kb/s 15.85kb/s
18.25kb/s 19.85kb/s ,23.05kb/s,23.85kb/s,提供的语音带宽范围达到50~7000Hz,人声感觉比以前
更加自然、舒适和易于分辨 。
二、话音质量评定
语音编码或语音压缩编码研究的基本问题,就是在给定编码速率的条件下,如何能得到尽量好的
重建语音质量。主观评定方法符合人类听话时对语音质量的感觉得到了广泛应用。常用的方法有平均
得分意见(Mean Opinion Score, 简称MOS)判定法,下表说明了AMR话音编码器各模式的话音质量。
表二 : AMR话音编码器各模式的MOS值
| 编码方式 | AMR122 | AMR102 | AMR795 | AMR74 | AMR67 | AMR59 | AMR515 | AMR475 |
| MOS | 4.01 | 4.06 | 3.91 | 3.83 | 3.77 | 3.72 | 3.50 | 3.50 |
三、AMR文件结构解析
AMR文件由文件头和数据帧组成,文件头标识占6个字节,后面紧跟着就是音频帧;
格式如下所示:
| 文件头 (占 6 字节) |
| 语音帧 1 |
| 语音帧 2 |
| … |
文件头
单声道和多声道情况下文件的头部是不一致的,单声道情况下的文件头只包括一个Magic number,
而多声道情况下文件头既包含Magic number,在其之后还包含一个32位的Chanel description field。
多声道情况下的32位通道描述字符,前28位都是保留字符,必须设置成0,最后4位说明使用的声道
个数。
语音数据
文件头之后就是时间上连续的语音帧块了,每个帧块包含若干个8位组对齐的语音帧,相对于若干个
声道,从第一个声道开始依次排列。每一个语音帧都是从一个8位的帧头开始:
其中P为填充位必须设为0,每个帧都是8位组对齐的。
对于不同的编码模式,它的音频帧的大小是不同的,比特率也是不同的;如下图所示:
|
| 规格 | 比特率(kbps) | 音频帧大小(字节) | 帧头(字节) | FT |
| 0 | AMR 4.75 | 4.75 | 13 | 04 00000100 | 0000 |
| 1 | AMR 5.15 | 5.15 | 14 | 0C 00001100 | 0001 |
| 2 | AMR 5.9 | 5.90 | 16 | 14 00010100 | 0010 |
| 3 | AMR 6.7 | 6.70 | 18 | 1C 00011100 | 0011 |
| 4 | AMR 7.4 | 7.40 | 20 | 24 00100100 | 0100 |
| 5 | AMR 7.95 | 7.95 | 21 | 2C 00101100 | 0101 |
| 6 | AMR 10.2 | 10.20 | 27 | 34 00110100 | 0110 |
| 7 | AMR 12.2 | 12.20 | 32 | 3C 00111100 | 0111 |
音频数据帧大小的计算:
AMR 一帧对应20ms,那么一秒有50帧的音频数据。由于比特率不同,每帧的数据大小也不同。
如果比特率是12.2kbs,那么每秒采样的音频数据位数为:
12200 / 50 = 244bit = 30.5byte,取整为31字节。
再加上一个字节的帧头,这样数据帧的大小为32字节。
四、帧格式解析
AMR语音帧格式由帧头和语音数据组成;并且分为两种类型的帧格式:AMR IF1 和 AMR IF2
如下图所示:
| 帧头 | 语音数据 |
| 1个字节帧头 (AMR Header) |
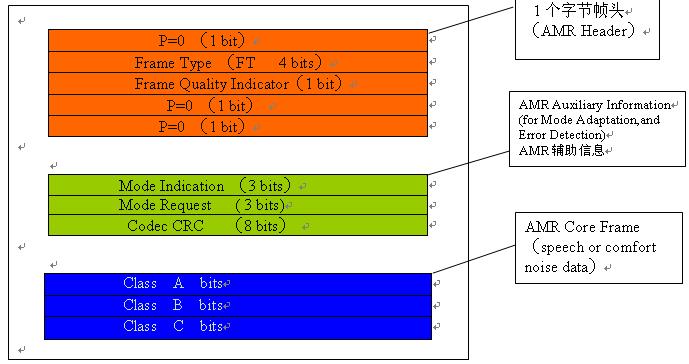
a . AMR Header占1个字节,如下图所示:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| P | FT | Q | P | P | |||
| 0 |
|
|
|
| 0 | 0 | 0 |
P = 0;
FT:Frame Type,对应不同编码模式;占4 bit;
Q:帧质量指示器,0:表示为坏帧; 占 1 bit。
后面的2个P补0
b. 帧头后面就是辅助信息。
此辅助信息针对自适应模式及差错检测。
c. 辅助信息后面就是语音数据。每一帧的数据有分为三个部分:Class A ,Class B ,Class C;
Class A:是一帧中最敏感、最重要的数据。这部分数据如有损坏,整个帧将无法解码。所以,一般在无线传输的时候要使用各种冗余的方式对这部分数据加以保护。
Class B:相对而言,比Class A不重要的数据。
Class C:比Class B还不重要的数据。
(2)AMR IF2的帧格式如下图所示:
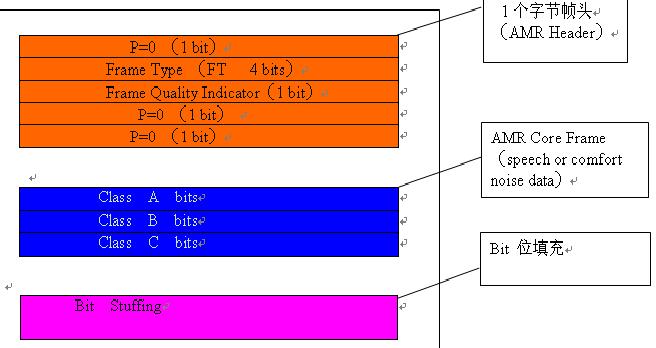
相对于IF1格式, IF2 省去了Frame Quality Indicator, Mode Indication, Mode Request 和CRC 校验。但是增加了bit 填充。因为AMR帧中数据的长度并不是字节(8bit)的整数倍,所以在有些帧的末尾需要增加bit填充,以使整个帧的长度达到字节的整数倍。
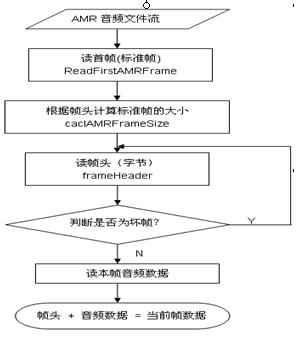
五、AMR帧读取算法
因为可能存在异常帧,所以不一定所有的语音帧大小一致,对于跟正常帧大小不一致的,或者帧头跟正常帧头不一致的,就不交给解码器,直接抛弃该坏帧。
读取帧的算法:
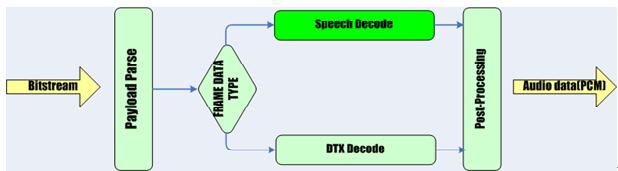
六、 AMR解码流程
AMR Payload Decode原理分析如图中Payload Parse模块-----解码出编码语音数据;
AMR Speech Decode原理分析如图中Speech Decode模块----解码语音帧;
AMR DTX decode原理分析如图中DTX Decode模块-----解码噪音帧;
AMR Post-Processing原理分析如图中的Post-Processing模块-----语音后处理;
七.AMR模式选择的自适应机制
自适应的基本概念是以更加智能的方式解决信源和信道编码的速率分配问题,使得无线资源的配置
和利用更加灵活和高效。实际的语音编码速率取决于信道的条件,它是信道质量的函数。而这部分的工
作是解码器根据噪声等测量参数协助基站来完成,选择模式,决定速率快慢。原则上在信道很差的时候
采用速率比较低的编码器,这样就能分配给信道编码更多的比特数来实现纠错,实现更可靠的差错控制,
从而有效地抑制错误发生,提高话音质量。
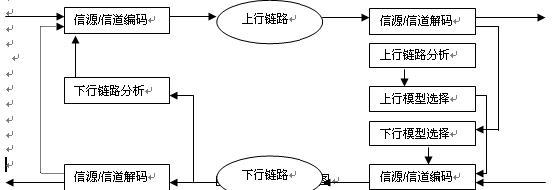
自适应过程实现框图















 1881
1881

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









