







2.0 Redis主从复制
2.0.1 概念
主从复制
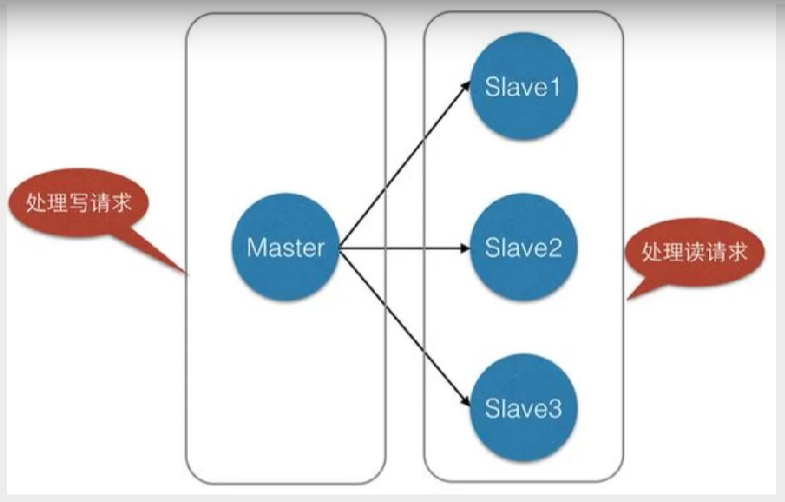
是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(master),后者称为从节点(slave);数据的复制是单向的,只能由主节点到从节点。master以写为主,slave以读为主。
默认情况下,每台Redis服务器都是主节点;且一个主节点可以有多个从节点(或没有从节点),但一个从节点只能有一个主节点。
主从复制的作用
- 数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
- 故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。
- 负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
- 高可用基石:除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础。
一般来说,要将redis运用于生产项目中,只使用一台redis是万万不能的
- 从结构上,单个redis服务器会发生单点故障,且单机处理所有的请求会导致负载过大
- 从容量上,单机内存容量有限,一般来说,单台redis最大使用内存不应该超过20G
2.0.2 配置主从
主从复制,读写分离!80%的情况都是在进行读操作!减缓服务器的压力,架构中经常使用!一主二 从!
测试场景
环境配置
只配置从库,不配置主库!
# 启动一个redis,查看信息
127.0.0.1:6379> info replication
# Replication
role:master # 角色
connected_slaves:0 # 从机数量
master_replid:fa0e795a3e369ed7e46a40ee8818a51255ab6df3
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
复制一个配置文件,修改一下端口号、日志保存的文件名、rdb文件名、pid文件 ,在启动2个redis
[root@yunmx bin]# redis-server redis-conf/redis.conf1 # 6380
6038:C 12 Dec 2021 13:06:38.166 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
6038:C 12 Dec 2021 13:06:38.166 # Redis version=6.0.6, bits=64, commit=00000000, modified=0, pid=6038, just started
6038:C 12 Dec 2021 13:06:38.166 # Configuration loaded
[root@yunmx bin]# redis-server redis-conf/redis.conf2 # 6381
6045:C 12 Dec 2021 13:06:39.640 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
6045:C 12 Dec 2021 13:06:39.641 # Redis version=6.0.6, bits=64, commit=00000000, modified=0, pid=6045, just started
6045:C 12 Dec 2021 13:06:39.641 # Configuration loaded




未配置主从之前,三个节点都是主节点



认老大
一主(79)二从(80,81)
# 6380配置
127.0.0.1:6380> SLAVEOF 127.0.0.1 6379 # 认本机的6379端口服务的redis做老大
OK
127.0.0.1:6380> info replication
# Replication
role:slave # 变成了从节点
master_host:127.0.0.1 # 主节点的信息
master_port:6379
master_link_status:up
master_last_io_seconds_ago:8
master_sync_in_progress:0
slave_repl_offset:0
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:55c3146a93d180ad5aa89e4d64ff894a451e77e5
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:0
# 查看主机的信息
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6380,state=online,offset=168,lag=0 # 从机的信息
slave1:ip=127.0.0.1,port=6381,state=online,offset=168,lag=0
master_replid:55c3146a93d180ad5aa89e4d64ff894a451e77e5
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:168
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:168
真实的主从配置应该在配置文件中配置,这样的话是永久的,上述使用的是命令,只是暂时的
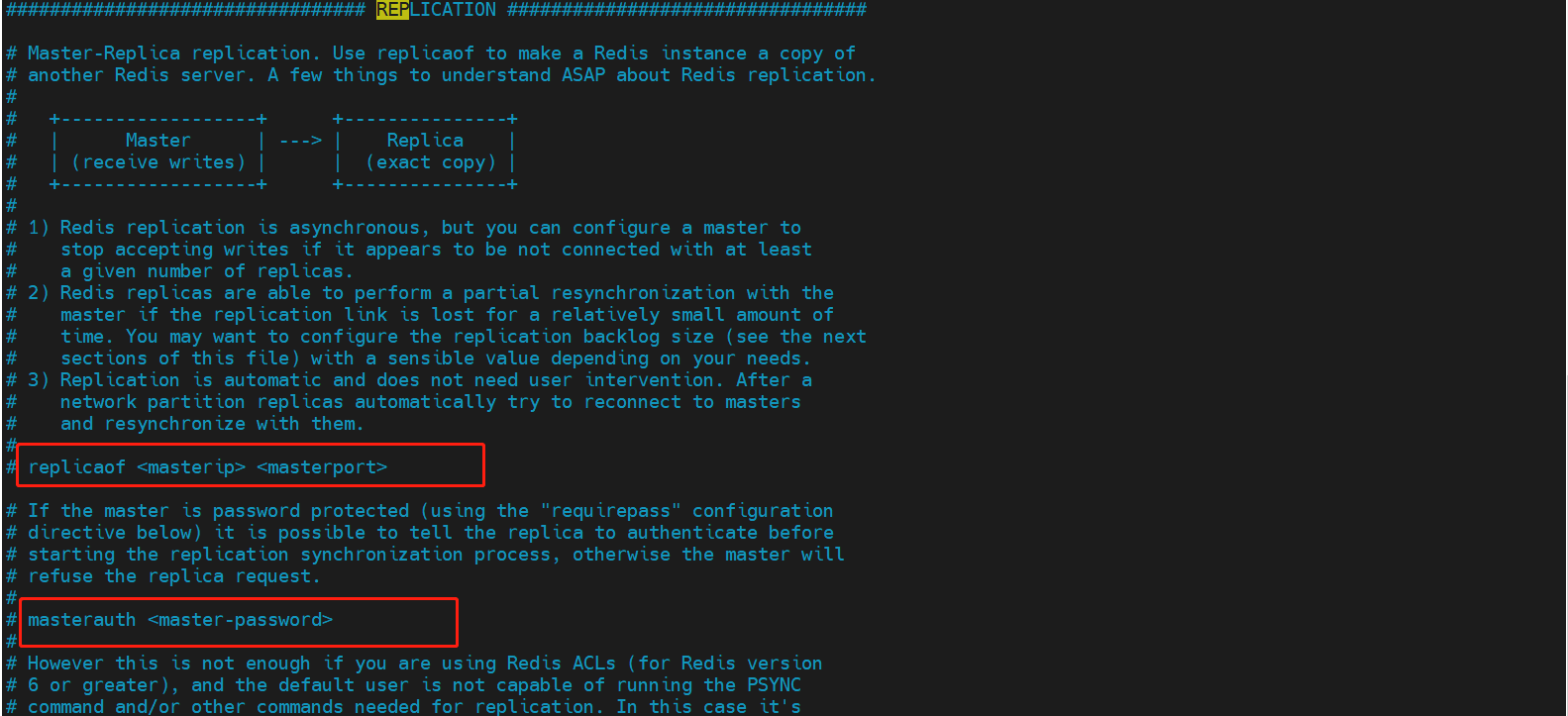
replicaof <masterip> <masterport> # 主机的IP地址和端口号
masterauth <master-password> # 如果设定有密码,配置密码即可
2.0.3 特性验证
主机可以设置值,从机不能写,主机中所有信息和数据,从机都会保存
# 主机设置一个key
127.0.0.1:6379> set key1 yunmx
OK
127.0.0.1:6379>
# 从机中也会有,从机无法设置key
127.0.0.1:6380> keys *
1) "key1"
127.0.0.1:6380> get key1
"yunmx"
127.0.0.1:6380> set key2 yunmx2
(error) READONLY You can't write against a read only replica.
127.0.0.1:6380>
老大宕机后,从机还是从机,只是会显示主机状态不正常;主机恢复,从机依旧可以直接获取到主机写入的信息,保证了一定的高可用性
如果使用的是我们命令行配置的主从,如果从机宕机后,从机就会脱离主从了,需要再次命令行配置从机,变成从机以后,就能获取到key的值了
# 停掉6379主机服务,查看从机集群状态
127.0.0.1:6380> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:down
master_last_io_seconds_ago:-1
master_sync_in_progress:0
slave_repl_offset:1065
master_link_down_since_seconds:10
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:55c3146a93d180ad5aa89e4d64ff894a451e77e5
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:1065
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:1065
# 恢复6379主机服务,验证是否还会同步数据
[root@yunmx ~]# redis-cli -p 6379
127.0.0.1:6379> set key2 yunmx2 # 恢复主节点,设置一个key
OK
127.0.0.1:6379>
# 从节点读取主机恢复后设置的key
127.0.0.1:6380> get key2 # 能够正常读取
"yunmx2"
# 停止从机服务,主机设定一个key,在恢复从机,进行验证
127.0.0.1:6379> set key3 yunmx3
OK
127.0.0.1:6380> get key3 # 从机无法获得key3的数据
(nil)
127.0.0.1:6381> get key3
"yunmx3"
2.0.4 复制原理
Slave启动成功连接到master后会发送一个sync同步命令
Master接到命令后,确定后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行完毕之后,master将传送整个数据文件到slave,并完成一次完全同步
全量复制:slave服务将接收到数据库文件数据后,将其存盘并加载到内存中
增量复制:Mster继续将新的所有收集到的修改命令依次传给slave,完成同步
但是只要重新连接master,一次完全同步将被自动执行!我们的数据一定可以在从机中看到!
2.0.5 层层链路
上一个M链接下一个S!
可以完成主从复制!
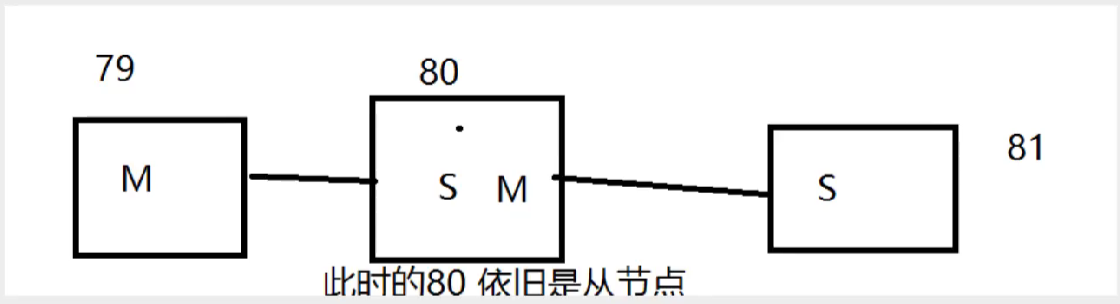
如果没有79,这个时候能不能选择一个老大出来呢,这个时候需要手动去配置!
谋朝篡位:slaveof no one 使自己变成主机!如果老大回来了,也是需要手动配置
2.1 Redis哨兵模式
自动版选老大的模式
2.1.1 概述
-
主从切换技术的方式是:当主服务器宕机后,需要手动把一台服务器切换为主服务,这就需要人工干预,费时费力,还会造成一段时间内服务不能使用。这不是一种推荐的方式,更多的是我们考虑哨兵模式,Redis从2.8开始正式提供Sentinel(哨兵)架构来解决这个问题。
-
能够后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库
-
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,是一个独立的进程,作为进程,它会独立运行。原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例。
2.1.2 基本架构
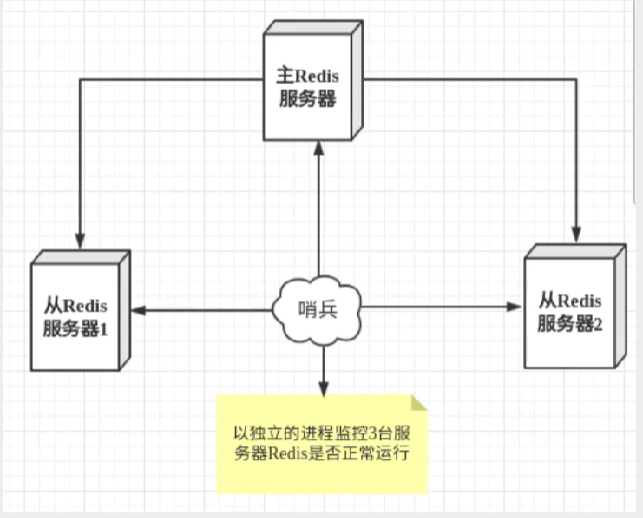
哨兵模式的作用:

- 通过发送命令,让Redis服务器返回监控运行状态,包括主服务和从服务
- 当哨兵检测到master宕机后,会自动将slave切换成master,然后通过发布订阅模式通过其他的从服务器,修改配置文件,让他们切换主机
一个哨兵进程对redis服务器进行监控,可能会出现问题,为此,我们可以使用多个哨兵进行监控,各个哨兵之间还会进行监控,这样就形成了多哨兵模式

使用哨兵模式,至少都会启动6个进程
假设主服务宕机,哨兵1先检测到这个结果,系统并不会马上进行failover过程,仅仅是哨兵1主观的认为主服务不可用,这个现场叫主观下线。当后面的哨兵也检测到主服务不可用,并且数量达到一定值后,那么哨兵就会进行一次投票,投票的结果由一个哨兵发起,进行failover故障转移操作。切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务实现切换主机,这个过程被称为客观下线
2.1.3 场景测试
我们目前测试的架构是一主二从
配置哨兵模式的配置文件
# 新建配置文件并编辑以下内容
sentinel monitor myredis 127.0.0.1 6379 1# 语法:sentinel monitor 被监控的名称 host port 1(1代表主机宕机后,从机投票让谁来接替成为主机,)
启动哨兵
[root@yunmx bin]# redis-sentinel redis-conf/sentinel.conf # 启动一个哨兵
12680:X 12 Dec 2021 15:13:42.570 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
12680:X 12 Dec 2021 15:13:42.570 # Redis version=6.0.6, bits=64, commit=00000000, modified=0, pid=12680, just started
12680:X 12 Dec 2021 15:13:42.570 # Configuration loaded
_._
_.-``__ ''-._
_.-`` `. `_. ''-._ Redis 6.0.6 (00000000/0) 64 bit
.-`` .-```. ```\/ _.,_ ''-._
( ' , .-` | `, ) Running in sentinel mode
|`-._`-...-` __...-.``-._|'` _.-'| Port: 26379
| `-._ `._ / _.-' | PID: 12680
`-._ `-._ `-./ _.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' | http://redis.io
`-._ `-._`-.__.-'_.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' |
`-._ `-._`-.__.-'_.-' _.-'
`-._ `-.__.-' _.-'
`-._ _.-'
`-.__.-'
12680:X 12 Dec 2021 15:13:42.571 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
12680:X 12 Dec 2021 15:13:42.575 # Sentinel ID is ea7ccf0119a4cf2873cf3bb108da5c7af86d36bd
12680:X 12 Dec 2021 15:13:42.575 # +monitor master myredis 127.0.0.1 6379 quorum 1
12680:X 12 Dec 2021 15:13:42.575 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ myredis 127.0.0.1 6379
12680:X 12 Dec 2021 15:13:42.580 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ myredis 127.0.0.1 6379
手动宕机测试
# 关掉主机
127.0.0.1:6379> SHUTDOWN
not connected>
# 哨兵监控的一些信息
12680:X 12 Dec 2021 15:16:49.174 # +failover-state-select-slave master myredis 127.0.0.1 6379
12680:X 12 Dec 2021 15:16:49.241 # +selected-slave slave 127.0.0.1:6381 127.0.0.1 6381 @ myredis 127.0.0.1 6379
12680:X 12 Dec 2021 15:16:49.241 * +failover-state-send-slaveof-noone slave 127.0.0.1:6381 127.0.0.1 6381 @ myredis 127.0.0.1 6379
12680:X 12 Dec 2021 15:16:49.324 * +failover-state-wait-promotion slave 127.0.0.1:6381 127.0.0.1 6381 @ myredis 127.0.0.1 6379
12680:X 12 Dec 2021 15:16:50.181 # +promoted-slave slave 127.0.0.1:6381 127.0.0.1 6381 @ myredis 127.0.0.1 6379
12680:X 12 Dec 2021 15:16:50.181 # +failover-state-reconf-slaves master myredis 127.0.0.1 6379
12680:X 12 Dec 2021 15:16:50.237 * +slave-reconf-sent slave 127.0.0.1:6380 127.0.0.1 6380 @ myredis 127.0.0.1 6379
12680:X 12 Dec 2021 15:16:51.182 * +slave-reconf-inprog slave 127.0.0.1:6380 127.0.0.1 6380 @ myredis 127.0.0.1 6379
12680:X 12 Dec 2021 15:16:51.182 * +slave-reconf-done slave 127.0.0.1:6380 127.0.0.1 6380 @ myredis 127.0.0.1 6379
12680:X 12 Dec 2021 15:16:51.234 # +failover-end master myredis 127.0.0.1 6379
12680:X 12 Dec 2021 15:16:51.234 # +switch-master myredis 127.0.0.1 6379 127.0.0.1 6381 # 哨兵显示主机自动切换到了6381
12680:X 12 Dec 2021 15:16:51.234 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ myredis 127.0.0.1 6381
12680:X 12 Dec 2021 15:16:51.234 * +slave slave 127.0.0.1:6379 127.0.0.1 6379 @ myredis 127.0.0.1 6381
12680:X 12 Dec 2021 15:17:21.244 # +sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ myredis 127.0.0.1 6381
# 检查6381主机的信息
127.0.0.1:6381> info replication
# Replication
role:master # 变成了master
connected_slaves:1
slave0:ip=127.0.0.1,port=6380,state=online,offset=21944,lag=0
master_replid:a4719b795f6c088ed1a11408a2bc52cc48ece215
master_replid2:367d9493cb151b433bd535ad9e49603d1fa35013
master_repl_offset:21944
second_repl_offset:11812
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:21944
如果master宕机以后,这个时候就会从从机中随机选择一个服务器(有一个自己的投票算法)作为主机
主机恢复
# 重新开启之前宕机的主机。观察哨兵的反应
12680:X 12 Dec 2021 15:23:41.461 * +convert-to-slave slave 127.0.0.1:6379 127.0.0.1 6379 @ myredis 127.0.0.1 6381
# 查看先前主机的信息
127.0.0.1:6379> info replication
# Replication
role:slave # 变成从机
master_host:127.0.0.1
master_port:6381
master_link_status:up
master_last_io_seconds_ago:1
master_sync_in_progress:0
slave_repl_offset:41645
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:a4719b795f6c088ed1a11408a2bc52cc48ece215
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:41645
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:39205
repl_backlog_histlen:2441
# 只能归并到新的主机下,当作从机,这就是哨兵模式的规则!
优缺点
-
哨兵集群,基于主从复制模式,所有的主从配置优点它多有
-
主从可以切换,故障可以转移,系统的可用性会更好
-
就是主从模式的升级,手动到自动,更加健壮!
-
不好在线扩容,集群容量一旦达到上线,在线扩容就十分麻烦!
-
实现哨兵模式的配置其实很麻烦的,里面有很多选择!
哨兵模式的全部配置
<后续进行详细学习>
# Example sentinel.conf
# port <sentinel-port>
# The port that this sentinel instance will run on
# sentinel实例运行的端口
port 26379 # 哨兵进程运行的端口号
# sentinel announce-ip <ip>
# sentinel announce-port <port>
#
# The above two configuration directives are useful in environments where,
# because of NAT, Sentinel is reachable from outside via a non-local address.
#
# When announce-ip is provided, the Sentinel will claim the specified IP address
# in HELLO messages used to gossip its presence, instead of auto-detecting the
# local address as it usually does.
#
# Similarly when announce-port is provided and is valid and non-zero, Sentinel
# will announce the specified TCP port.
#
# The two options don't need to be used together, if only announce-ip is
# provided, the Sentinel will announce the specified IP and the server port
# as specified by the "port" option. If only announce-port is provided, the
# Sentinel will announce the auto-detected local IP and the specified port.
#
# Example:
#
# sentinel announce-ip 1.2.3.4
# dir <working-directory>
# Every long running process should have a well-defined working directory.
# For Redis Sentinel to chdir to /tmp at startup is the simplest thing
# for the process to don't interferer with administrative tasks such as
# unmounting filesystems.
dir /tmp
# sentinel monitor <master-name> <ip> <redis-port> <quorum>
# master-name : master Redis Server名称
# ip : master Redis Server的IP地址
# redis-port : master Redis Server的端口号
# quorum : 主实例判断为失效至少需要 quorum 个 Sentinel 进程的同意,只要同意 Sentinel 的数量不达标,自动failover就不会执行
#
# Tells Sentinel to monitor this master, and to consider it in O_DOWN
# (Objectively Down) state only if at least <quorum> sentinels agree.
#
# Note that whatever is the ODOWN quorum, a Sentinel will require to
# be elected by the majority of the known Sentinels in order to
# start a failover, so no failover can be performed in minority.
#
# Slaves are auto-discovered, so you don't need to specify slaves in
# any way. Sentinel itself will rewrite this configuration file adding
# the slaves using additional configuration options.
# Also note that the configuration file is rewritten when a
# slave is promoted to master.
#
# Note: master name should not include special characters or spaces.
# The valid charset is A-z 0-9 and the three characters ".-_".
#
sentinel monitor mymaster 127.0.0.1 6379 2
# sentinel auth-pass <master-name> <password>
#
# Set the password to use to authenticate with the master and slaves.
# Useful if there is a password set in the Redis instances to monitor.
#
# Note that the master password is also used for slaves, so it is not
# possible to set a different password in masters and slaves instances
# if you want to be able to monitor these instances with Sentinel.
#
# However you can have Redis instances without the authentication enabled
# mixed with Redis instances requiring the authentication (as long as the
# password set is the same for all the instances requiring the password) as
# the AUTH command will have no effect in Redis instances with authentication
# switched off.
#
# Example:
#
# sentinel auth-pass mymaster MySUPER--secret-0123passw0rd
# sentinel down-after-milliseconds <master-name> <milliseconds>
#
# Number of milliseconds the master (or any attached slave or sentinel) should
# be unreachable (as in, not acceptable reply to PING, continuously, for the
# specified period) in order to consider it in S_DOWN state (Subjectively
# Down).
# 选项指定了 Sentinel 认为Redis实例已经失效所需的毫秒数。当实例超过该时间没有返回PING,或者直接返回错误, 那么 Sentinel 将这个实例标记为主观下线(subjectively down,简称 SDOWN )
#
# Default is 30 seconds.
sentinel down-after-milliseconds mymaster 30000
# sentinel parallel-syncs <master-name> <numslaves>
#
# How many slaves we can reconfigure to point to the new slave simultaneously
# during the failover. Use a low number if you use the slaves to serve query
# to avoid that all the slaves will be unreachable at about the same
# time while performing the synchronization with the master.
# 选项指定了在执行故障转移时, 最多可以有多少个从Redis实例在同步新的主实例, 在从Redis实例较多的情况下这个数字越小,同步的时间越长,完成故障转移所需的时间就越长。
sentinel parallel-syncs mymaster 1
# sentinel failover-timeout <master-name> <milliseconds>
#
# Specifies the failover timeout in milliseconds. It is used in many ways:
#
# - The time needed to re-start a failover after a previous failover was
# already tried against the same master by a given Sentinel, is two
# times the failover timeout.
#
# - The time needed for a slave replicating to a wrong master according
# to a Sentinel current configuration, to be forced to replicate
# with the right master, is exactly the failover timeout (counting since
# the moment a Sentinel detected the misconfiguration).
#
# - The time needed to cancel a failover that is already in progress but
# did not produced any configuration change (SLAVEOF NO ONE yet not
# acknowledged by the promoted slave).
#
# - The maximum time a failover in progress waits for all the slaves to be
# reconfigured as slaves of the new master. However even after this time
# the slaves will be reconfigured by the Sentinels anyway, but not with
# the exact parallel-syncs progression as specified.
# 如果在该时间(ms)内未能完成failover操作,则认为该failover失败
#
# Default is 3 minutes.
sentinel failover-timeout mymaster 180000
# SCRIPTS EXECUTION
#
# sentinel notification-script and sentinel reconfig-script are used in order
# to configure scripts that are called to notify the system administrator
# or to reconfigure clients after a failover. The scripts are executed
# with the following rules for error handling:
#
# If script exits with "1" the execution is retried later (up to a maximum
# number of times currently set to 10).
#
# If script exits with "2" (or an higher value) the script execution is
# not retried.
#
# If script terminates because it receives a signal the behavior is the same
# as exit code 1.
#
# A script has a maximum running time of 60 seconds. After this limit is
# reached the script is terminated with a SIGKILL and the execution retried.
# NOTIFICATION SCRIPT
#
# sentinel notification-script <master-name> <script-path>
#
# Call the specified notification script for any sentinel event that is
# generated in the WARNING level (for instance -sdown, -odown, and so forth).
# This script should notify the system administrator via email, SMS, or any
# other messaging system, that there is something wrong with the monitored
# Redis systems.
#
# The script is called with just two arguments: the first is the event type
# and the second the event description.
#
# The script must exist and be executable in order for sentinel to start if
# this option is provided.
# 指定sentinel检测到该监控的redis实例指向的实例异常时,调用的报警脚本。该配置项可选,但是很常用。
#
# Example:
#
# sentinel notification-script mymaster /var/redis/notify.sh
# CLIENTS RECONFIGURATION SCRIPT
#
# sentinel client-reconfig-script <master-name> <script-path>
#
# When the master changed because of a failover a script can be called in
# order to perform application-specific tasks to notify the clients that the
# configuration has changed and the master is at a different address.
#
# The following arguments are passed to the script:
#
# <master-name> <role> <state> <from-ip> <from-port> <to-ip> <to-port>
#
# <state> is currently always "failover"
# <role> is either "leader" or "observer"
#
# The arguments from-ip, from-port, to-ip, to-port are used to communicate
# the old address of the master and the new address of the elected slave
# (now a master).
#
# This script should be resistant to multiple invocations.
#
# Example:
#
# sentinel client-reconfig-script mymaster /var/redis/reconfig.sh















 255
255











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









