







 本文深入探讨了排序算法的基础概念,包括稳定与不稳定排序、内排序与外排序、以及各种排序算法的时间复杂度与特性。重点介绍了冒泡排序、简单选择排序、简单插入排序、希尔排序、堆排序、归并排序、快速排序,并提供了相应的代码实现。同时,讨论了快速排序的优化方案和非比较排序算法如计数排序和基数排序,最后分析了排序算法的选择依据。
本文深入探讨了排序算法的基础概念,包括稳定与不稳定排序、内排序与外排序、以及各种排序算法的时间复杂度与特性。重点介绍了冒泡排序、简单选择排序、简单插入排序、希尔排序、堆排序、归并排序、快速排序,并提供了相应的代码实现。同时,讨论了快速排序的优化方案和非比较排序算法如计数排序和基数排序,最后分析了排序算法的选择依据。
排序:对一序列对象根据某个关键字进行排序;
稳定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面;
不稳定:如果a原本在b的前面,而a=b,排序之后a可能会出现在b的后面;
内排序:所有排序操作都在内存中完成;
外排序:由于数据太大,因此把数据放在磁盘中,而排序通过磁盘和内存的数据传输才能进行;
排序耗时的操作:比较、移动;
排序分类:
(1)交换类:冒泡排序、快速排序;此类的特点是通过不断的比较和交换进行排序;
(2)插入类:简单插入排序、希尔排序;此类的特点是通过插入的手段进行排序;
(3)选择类:简单选择排序、堆排序;此类的特点是看准了再移动;
(4)归并类:归并排序;此类的特点是先分割后合并;
历史进程:一开始排序算法的复杂度都在O(n^2),希尔排序的出现打破了这个僵局;
以下视频是Sapientia University创作的,用跳舞的形式演示排序步骤,这些视频就可以当作复习排序的资料~
冒泡排序视频:http://v.youku.com/v_show/id_XMzMyOTAyMzQ0.html
选择排序视频:http://v.youku.com/v_show/id_XMzMyODk5MDI0.html
插入排序视频:http://v.youku.com/v_show/id_XMzMyODk3NjI4.html
希尔排序视频:http://v.youku.com/v_show/id_XMzMyODk5MzI4.html
归并排序视频:http://v.youku.com/v_show/id_XMzMyODk5Njg4.html
快速排序视频:http://v.youku.com/v_show/id_XMzMyODk4NTQ4.html
上面介绍的排序算法都是基于排序的,还有一类算法不是基于比较的排序算法,即计数排序、基数排序;
预备:最简单的排序
此种实现方法是最简单的排序实现;
缺点是每次找最小值都是单纯的找,而没有为下一次寻找做出铺垫;
算法如下:
- public static int[] simple_sort(int[] arr) {
- for (int i = 0; i < arr.length; i++) {
- for (int j = i + 1; j < arr.length; j++) {
- if (arr[i] > arr[j]) {
- swap(arr, i, j);
- }
- }
- }
- return arr;
- }
一、冒泡排序
冒泡排序相对于最简单的排序有了改进,即每次交换都是对后续有帮助的,大数将会越来越大,小的数将会越来越小;
冒泡排序思想:两两相邻元素之间的比较,如果前者大于后者,则交换;
因此此排序属于交换排序一类,同类的还有现在最常用的排序方法:快速排序;
1.标准冒泡排序
此种方法是最一般的冒泡排序实现,思想就是两两相邻比较并交换;
算法实现如下:
- public static int[] bubble_sort2(int[] arr) {
- for (int i = 0; i < arr.length; i++) {
- for (int j = arr.length - 1; j > i; j--) {
- if (arr[j] < arr[j - 1]) {
- swap(arr, j, j - 1);
- }
- }
- }
- return arr;
- }
2.改进冒泡排序
改进在于如果出现一个序列,此序列基本是排好序的,如果是标准的冒泡排序,则还是需要进行不断的比较;
改进方法:通过一个boolean isChanged,如果一次循环中没有交换过元素,则说明已经排好序;
算法实现如下:
- // 最好:n-1次比较,不移动,因此时间复杂度为O(n),不占用辅助空间
- // 最坏:n(n-1)/2次比较和移动,因此O(n^2),占用交换的临时空间,大小为1;
- public static int[] bubble_sort3(int[] arr) {
- boolean isChanged = true;
- for (int i = 0; i < arr.length && isChanged; i++) {
- isChanged = false;
- for (int j = i + 1; j < arr.length; j++) {
- if (arr[i] > arr[j]) {
- swap(arr, i, j);
- isChanged = true;
- }
- }
- }
- return arr;
- }
二、简单选择排序
简单选择排序特点:每次循环找到最小值,并交换,因此交换次数始终为n-1次;
相对于最简单的排序,对于很多不必要的交换做了改进,每个循环不断比较后记录最小值,只做了一次交换(当然也可能不交换,当最小值已经在正确位置)
算法如下:
- //最差:n(n-1)/2次比较,n-1次交换,因此时间复杂度为O(n^2)
- //最好:n(n-1)/2次比较,不交换,因此时间复杂度为O(n^2)
- //好于冒泡排序
- public static int[] selection_sort(int[] arr) {
- for (int i = 0; i < arr.length - 1; i++) {
- int min = i;
- for (int j = i + 1; j < arr.length; j++) {
- if (arr[min] > arr[j]) {
- min = j;
- }
- }
- if (min != i)
- swap(arr, min, i);
- }
- return arr;
- }
三、简单插入排序
思想: 给定序列,存在一个分界线,分界线的左边被认为是有序的,分界线的右边还没被排序,每次取没被排序的最左边一个和已排序的做比较,并插入到正确位置;我们默认索引0的子数组有序;每次循环将分界线右边的一个元素插入有序数组中,并将分界线向右移一位;
算法如下:
- // 最好:n-1次比较,0次移动 ,时间复杂度为O(n)
- // 最差:(n+2)(n-1)/2次比较,(n+4)(n-1)/2次移动,时间复杂度为 O(n^2)
- public static int[] insertion_sort(int[] arr) {
- int j;
- for (int i = 1; i < arr.length; i++) {
- if (arr[i] < arr[i - 1]) {
- int tmp = arr[i];
- for (j = i - 1; j >= 0 && arr[j] > tmp; j--) {
- arr[j + 1] = arr[j];
- }
- arr[j + 1] = tmp;
- }
- }
- return arr;
- }
简单插入排序比选择排序和冒泡排序好!
四、希尔排序
1959年Shell发明;
第一个突破O(n^2)的排序算法;是简单插入排序的改进版;
思想:由于简单插入排序对于记录较少或基本有序时很有效,因此我们可以通过将序列进行分组排序使得每组容量变小,再进行分组排序,然后进行一次简单插入排序即可;
这里的分组是跳跃分组,即第1,4,7位置为一组,第2,5,8位置为一组,第3,6,9位置为一组;
| 索引 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
此时,如果increment=3,则i%3相等的索引为一组,比如索引1,1+3,1+3*2
一般增量公式为:increment = increment/3+1;
算法实现如下:
- // O(n^(3/2))
- //不稳定排序算法
- public static int[] shell_sort(int[] arr) {
- int j;
- int increment = arr.length;
- do {
- increment = increment / 3 + 1;
- for (int i = increment; i < arr.length; i++) { //i=increment 因为插入排序默认每组的第一个记录都是已排序的
- if (arr[i] < arr[i - increment]) {
- int tmp = arr[i];
- for (j = i - increment; j >= 0 && arr[j] > tmp; j -= increment) {
- arr[j + increment] = arr[j];
- }
- arr[j + increment] = tmp;
- }
- }
- } while (increment > 1);
- return arr;
- }
五、堆排序
Floyd和Williams在1964年发明;
大根堆:任意父节点都比子节点大;
小根堆:任意父节点都比子节点小;
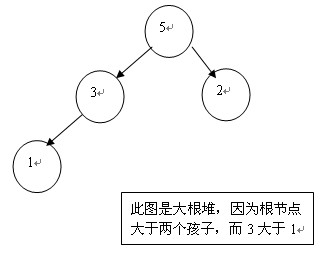
不稳定排序算法,是简单选择排序的改进版;
思想:构建一棵完全二叉树,首先构建大根堆,然后每次都把根节点即最大值移除,并用编号最后的节点替代,这时数组长度减一,然后重新构建大根堆,以此类推;
注意:此排序方法不适用于个数少的序列,因为初始构建堆需要时间;
算法实现如下:
- // 时间复杂度为O(nlogn)
- //不稳定排序算法
- //辅助空间为1
- //不适合排序个数较少的序列
- public static int[] heap_sort(int[] arr) {
- int tmp[] = new int[arr.length + 1];
- tmp[0] = -1;
- for (int i = 0; i < arr.length; i++) {
- tmp[i + 1] = arr[i];
- }
- // 构建大根堆:O(n)
- for (int i = arr.length / 2; i >= 1; i--) {
- makeMaxRootHeap(tmp, i, arr.length);
- }
- // 重建:O(nlogn)
- for (int i = arr.length; i > 1; i--) {
- swap(tmp, 1, i);
- makeMaxRootHeap(tmp, 1, i - 1);
- }
- for (int i = 1; i < tmp.length; i++) {
- arr[i - 1] = tmp[i];
- }
- return arr;
- }
- private static void makeMaxRootHeap(int[] arr, int low, int high) {
- int tmp = arr[low];
- int j;
- for (j = 2 * low; j <= high; j*=2) {
- if (j < high && arr[j] < arr[j + 1]) {
- j++;
- }
- if (tmp >= arr[j]) {
- break;
- }
- arr[low] = arr[j];
- low = j;
- }
- arr[low] = tmp;
- }
六、归并排序
稳定排序算法;
思想:利用递归进行分割和合并,分割直到长度为1为止,并在合并前保证两序列原本各自有序,合并后也有序;
实现代码如下:
- // 稳定排序;
- // 时间复杂度O(nlogn)
- // 空间复杂度:O(n+logn)
- public static int[] merge_sort(int[] arr) {
- Msort(arr, arr, 0, arr.length - 1);
- return arr;
- }
- private static void Msort(int[] sr, int[] tr, int s, int t) {
- int tr2[] = new int[sr.length];
- int m;
- if (s == t) {
- tr[s] = sr[s];
- } else {
- m = (s + t) / 2;
- Msort(sr, tr2, s, m);
- Msort(sr, tr2, m + 1, t);
- Merge(tr2, tr, s, m, t);
- }
- }
- private static void Merge(int[] tr2, int[] tr, int i, int m, int t) {
- int j, k;
- for (j = i, k = m + 1; i <= m && k <= t; j++) {
- if (tr2[i] < tr2[k]) {
- tr[j] = tr2[i++];
- } else {
- tr[j] = tr2[k++];
- }
- }
- while (i <= m) {
- tr[j++] = tr2[i++];
- }
- while (k <= t) {
- tr[j++] = tr2[k++];
- }
- }
七、快速排序
冒泡排序的升级版;现在用的最多的排序方法;
思想:选取pivot,将pivot调整到一个合理的位置,使得左边全部小于他,右边全部大于他;
注意:如果序列基本有序或序列个数较少,则可以采用简单插入排序,因为快速排序对于这些情况效率不高;
实现代码如下:
- // 不稳定排序算法
- // 时间复杂度:最好:O(nlogn) 最坏:O(n^2)
- // 空间复杂度:O(logn)
- public static int[] quick_sort(int[] arr) {
- qsort(arr, 0, arr.length - 1);
- return arr;
- }
- private static void qsort(int[] arr, int low, int high) {
- int pivot;
- if (low < high) {
- pivot = partition(arr, low, high);
- qsort(arr, low, pivot);
- qsort(arr, pivot + 1, high);
- }
- }
- private static int partition(int[] arr, int low, int high) {
- int pivotkey;
- pivotkey = arr[low];//选择pivot,此处可以优化
- while (low < high) {
- while (low < high && arr[high] >= pivotkey) {
- high--;
- }
- swap(arr, low, high);//交换,此处可以优化
- while (low < high && arr[low] <= pivotkey) {
- low++;
- }
- swap(arr, low, high);
- }
- return low;
- }
优化方案
(1)选取pivot:选取pivot的值对于快速排序至关重要,理想情况,pivot应该是序列的中间数;
而前面我们只是简单的取第一个数作为pivot,这点可以进行优化;
优化方法:抽多个数后取中位数作为pivot;
(2)对于小数组使用插入排序:因为快速排序适合大数组排序,如果是小数组,则效果可能没有简单插入排序来得好;
如果想进行优化,则可以使用以下代码:
- public static int[] quick_sort(int[] arr) {
- if(arr.length>10){
- qsort(arr, 0, arr.length - 1);
- }
- else{
- insertion_sort(arr);
- }
- return arr;
- }
八、计数排序
计数排序是典型的不是基于比较的排序算法,基于比较的排序算法最少也要O(nlogn),有没有可能创造线性时间的排序算法呢?那就是不基于比较的排序算法;
如果数组的数据范围为0~100,则很适合此算法;
复杂度: O(n+k), n为原数组长度,k为数据范围;
思想:
(1)首先找出数组中的最大值,然后创建一个计数数组(用来记录每个元素的数量),长度为max,比如数组为{1,1,2,3,4,5},则创建一个长度为6的数组count[],count[1]存放数值1出现的次数,即2;
(2)填充count数组,即遍历原数组,并且count[arr[i]-1]++;
(3)对count数组进行累加,即count[i] = count[i] + count[i-1];
(4)反向填充result数组,result[count[arr[i]]-1] = arr[i];
代码如下:
- import java.util.ArrayList;
- import java.util.Scanner;
- /**
- * 计数排序适用于:
- * (1)数据范围较小,建议在小于1000
- * (2)每个数值都要大于等于0
- * @author xiazdong
- *
- */
- public class Count_Sort {
- public static void main(String[] args) {
- int[] array = readArray();
- System.out.print("排序前数组为:");
- print(array);
- int result[] = count_sort(array);
- System.out.print("排序后数组为:");
- print(result);
- }
- //读取数组函数
- private static int[] readArray() {
- Scanner in = new Scanner(System.in);
- ArrayList<Integer> list = new ArrayList<Integer>();
- while(true){
- System.out.print("输入数字:");
- int element = in.nextInt();
- if(element==-1){
- break;
- }
- else{
- list.add(element);
- }
- }
- Integer[] arr = list.toArray(new Integer[0]);
- int[]array = new int[arr.length];
- for(int i=0;i<arr.length;i++){
- array[i] = arr[i];
- }
- return array;
- }
- //计数排序
- public static int[] count_sort(int arr[]){
- int gap = findGap(arr);
- int[] count = new int[gap];
- int[] result = new int[arr.length];
- for(int i=0;i<arr.length;i++){
- count[arr[i]]++;
- }
- for(int i=1;i<count.length;i++){
- count[i] = count[i] + count[i-1];
- }
- //反向填充结果数组
- for(int i=arr.length-1;i>=0;i--){
- result[count[arr[i]]-1] = arr[i];
- count[arr[i]]--;
- }
- return result;
- }
- public static void print(int result[]){
- for(int a:result){
- System.out.print(a+" ");
- }
- System.out.println();
- }
- /**
- * 找出数组的数据范围,即最大数的值
- * @param arr
- * @return
- */
- private static int findGap(int[] arr) {
- int max = arr[0];
- for(int i=1;i<arr.length;i++){
- if(max<arr[i]){
- max = arr[i];
- }
- }
- return (max+1);
- }
- }
九、基数排序
基数排序也是非比较的排序算法,对每一位进行排序,从最低位开始排序,复杂度为O(kn),为数组长度,k为数组中的数的最大的位数;
比如{987,789} ,先通过个位数排序:{987,789},再通过十位数排序:{987,789},再通过百位数排序:{789,987}
思想:
(1)取得数组中的最大数,并取得位数;
(2)arr为原始数组,从最低位开始取每个位组成radix数组;
(3)对radix进行计数排序(利用计数排序适用于小范围数的特点);
- import java.util.ArrayList;
- import java.util.Scanner;
- /**
- * 计数排序适用于:
- * (1)数据范围较小,建议在小于1000
- * (2)每个数值都要大于等于0
- * @author xiazdong
- *
- */
- public class Count_Sort {
- public static void main(String[] args) {
- int[] array = new int[]{1046,2084,9046,12074,56,7026,8099,17059,33,1};
- System.out.print("排序前数组为:");
- print(array);
- int result[] = radix_sort(array);
- System.out.print("排序后数组为:");
- print(result);
- }
- //基数排序 O(kn)
- public static int[] radix_sort(int[]arr){
- int radix[] = new int[arr.length];
- int count = 1;
- int n = findMaxLength(arr);
- for(int i=0;i<n;i++){
- radix = getRadix(arr,count);
- arr = count_sort(arr, radix);
- count *=10;
- }
- return arr;
- }
- private static int findMaxLength(int[] arr) {
- int max = arr[0];
- for(int i=1;i<arr.length;i++){
- if(max<arr[i]){
- max = arr[i];
- }
- }
- int count = 1;
- int mcount = 1;
- while((max / mcount)!=0){
- mcount = 1;
- count++;
- for(int i=0;i<count;i++){
- mcount *=10;
- }
- }
- return count;
- }
- //取得需要排序的位的数组
- private static int[] getRadix(int[] arr,int count) { //O(n)
- int radix[] = new int[arr.length];
- for(int i=0;i<arr.length;i++){
- radix[i] = arr[i]/count % 10;
- }
- return radix;
- }
- //类似计数排序
- //arr为原始数组
- //radix为需要排序的位的数组
- public static int[] count_sort(int arr[],int radix[]){
- int gap = findGap(radix);
- int[] count = new int[gap];
- int[] result = new int[radix.length];
- for(int i=0;i<radix.length;i++){
- count[radix[i]]++;
- }
- for(int i=1;i<count.length;i++){
- count[i] = count[i] + count[i-1];
- }
- //反向填充结果数组
- for(int i=radix.length-1;i>=0;i--){
- result[count[radix[i]]-1] = arr[i];
- count[radix[i]]--;
- }
- return result;
- }
- public static void print(int result[]){
- for(int a:result){
- System.out.print(a+" ");
- }
- System.out.println();
- }
- /**
- * 找出数组的数据范围,即最大数的值
- * @param arr
- * @return
- */
- private static int findGap(int[] arr) {
- int max = arr[0];
- for(int i=1;i<arr.length;i++){
- if(max<arr[i]){
- max = arr[i];
- }
- }
- return (max+1);
- }
- }
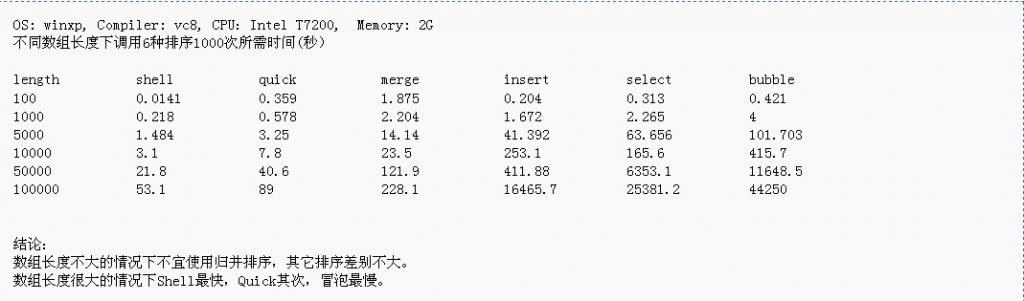
对比图
此图摘自http://www.cnblogs.com/cj723/archive/2011/04/29/2033000.html的图

总结:每个排序都有每个排序的优点,我们需要在适当的时候用适当的算法;
比如在基本有序、数组规模小时用直接插入排序;
比如在大数组时用快速排序;
比如如果要想稳定性,则使用归并排序;
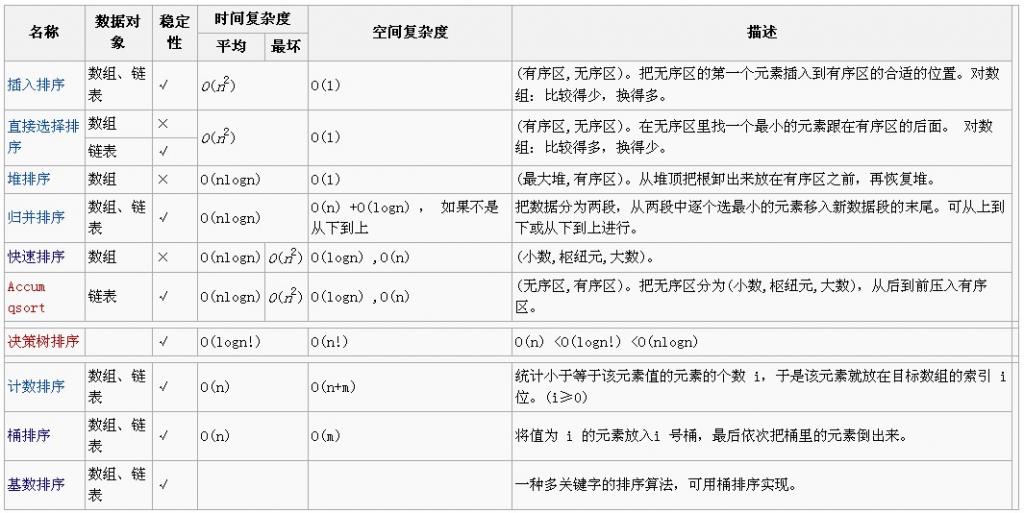
摘录维基百科图片:















 385
385

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









