







介绍HDFS核心组件–NameNode、Secondary NameNode、DataNode
NameNode
维护着HDFS中全部数据的元数据,包括所存储的文件和目录的元数据。这些元数据主要包括文件创建/修改时间戳、访问控制列表、块的副本信息以及文件当前状态。
控制着对数据的所有操作。在HDFS上的所有操作,都需要首先通过NameNode,然后再传递到Hadoop的相关组件。
向客户端提供系统数据块信息,以及应该从哪个数据块进行读/写。
向DataNode发出一些特殊命令,如:删除损坏的数据块。
Secondary NameNode
作用:Secondary NameNode会周期性地从NameNode中获取FSImage和EditLog,将两个文件合并成新的FSImage后,替换NameNode中的原FsImage文件,以减少NameNode重启更新FsImage文件的时间。
FSImage和EidtLog创建于部署Hadoop环境过程中的NameNode格式化(命令:hadoop namenode -format)。在HDFS中,FSImage和EidtLog存储了有关NameNode的所有操作及整个集群的状态元数据,用于保持集群重启之后的状态和上次停止前的状态一致1
- FSImage文件:HDFS文件系统存于硬盘中的所有元数据(即全量),里面记录了重启前HDFS文件系统中所有目录和文件的序列化信息2
- EditLog文件:保存了重启之后所有针对HDFS文件系统的操作(即增量),如增加文件、重命名文件、删除目录等操作信息2
启动Hadoop后,当用户或客户端发出操作请求,NameNode都会将元数据写入到EditLog中,在集群重启时再将EditLog中的元数据依次写入FSImage,并清空EditLog文件。EditLog作用如下图所示。3:
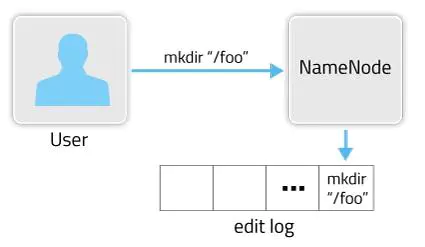
只有在NameNode重启时,EditLog才会合并到FSImage文件中,从而得到一个文件系统的最新快照。但因为集群中的NameNode很少重启,这意味着当NameNode运行了很长时间后,EditLog文件会变得很大。这将导致NameNode重启会花费很长时间;如果NameNode挂掉,那将丢失大量元数据信息。
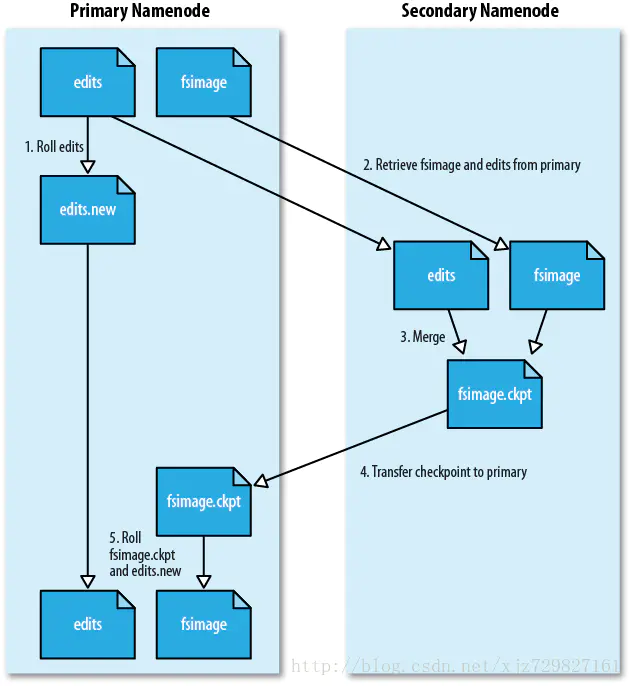
而Secondary NameNode周期性合并FSImage能很好的解决以上问题,Secondary NameNode工作流程如下图所示。
网页端口查看Hadoop启动过程,http://localhost:50070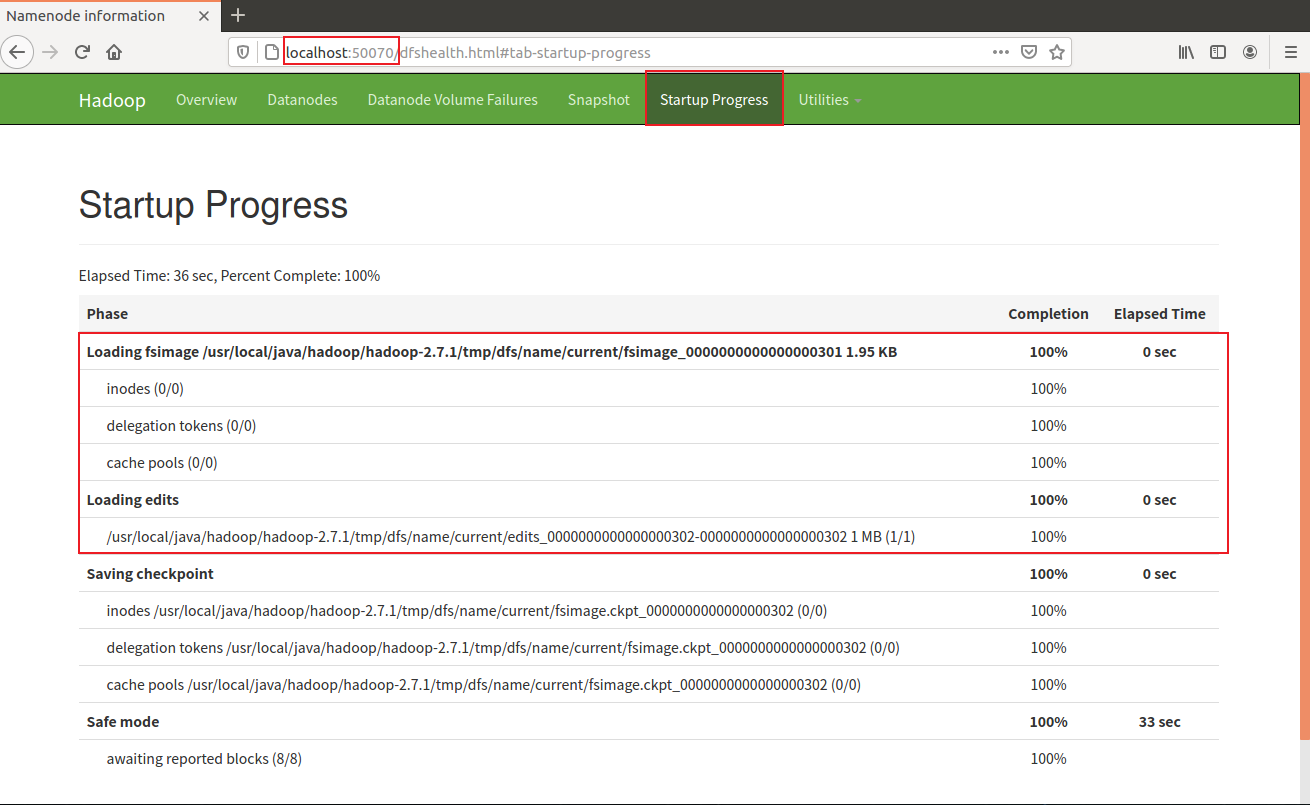
DataNode
存储数据,以块(block)为单位存储数据,每个数据块的大小默认是64M或128M、256M
处理来自客户端的读/写请求,DataNode负责数据块的创建、复制和删除。这些操作命令来自NameNode,并由DataNode执行。
和NameNode通过heartbeat机制保持连接,周期性的向NameNode上报保存的块block信息(block Report机制),若NameNode超过10分钟没有收到DataNode的heartbeat,则认为其已经Lost,并将Block的信息复制到其他DataNode上,以保证副本数。














 18万+
18万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









