







卷积神经网络
图像处理中,往往会将图像看成是一个或者多个二维向量,传统的神经网络采用全联接的方式,即输入层到隐藏层的神经元都是全部连接的,这样做将导致参数量巨大,使得网络训练耗时甚至难以训练,而CNN则通过局部链接、权值共享等方法避免这一困难。
局部连接(Sparse Connectivity)与权值共享(Shared Weights)
下图是一个很经典的图示,左边是全连接,右边是局部连接。

卷积神经网络
Lenet-5是Lecun大神在1998年提出的卷积网络模型,共有7层(除输入层)。本文主要详细介绍卷积层与池化层,及其在caffe中的网络描述,最后介绍Lenet-5网络在数字识别方面的应用。
Lenet网络结构:

预处理
去均值:把输入数据各个维度都中心化到0
归一化:幅度归一化到同一范围

卷积操作
卷积特征提取的过程
卷积核为3x3,则 3×3 的数据作为输入,且假设这个隐藏层有 k 个单元(每个单元也被称为一个卷积核 - Convolution Kernel,由对应的权值向量 W 和 b 来体现)。
每个隐藏单元的输入是用自己的权值向量 W 与 3×3 的小图做内积,再与偏置相加得到的:
![]()
假如深度网络的输入是 5×5 的大图,SAE 要从中提取特征,必须将 5×5 的大图分解成若干 3×3 的小图并分别提取它们的特征。分解方法就是:从大图的 (1, 1)、(1, 2)、(1, 3)、... 、(3, 3)等 9 个点开始分别作为小图的左上角起点,依次截取 9 张带有重合区域的小图,然后分别提取这 9 张小图的特征:
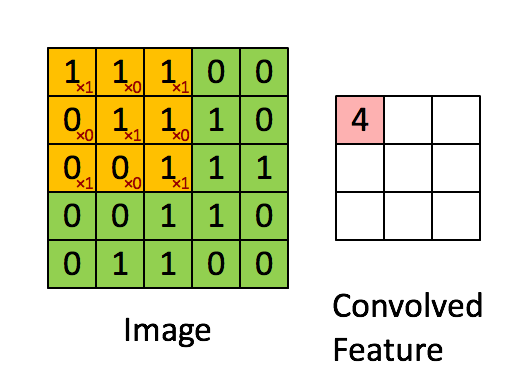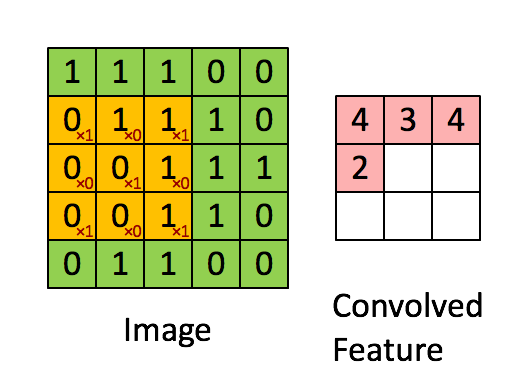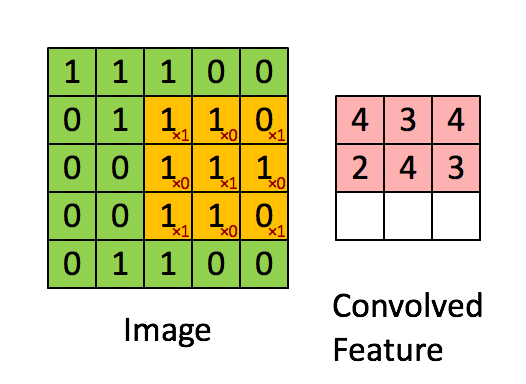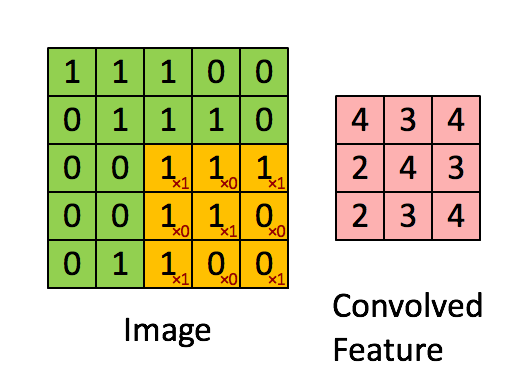
所以,每个隐藏单元将有 9 个输入,不同于之前的 1 个。然后将所有输入分别导入激活函数计算相应的输出,卷积特征提取的工作就完成了。
池化(Pooling)
池化过程
在隐藏层这个矩阵上划分出几个不重合的区域,然后在每个区域上计算该区域内特征的均值或最大值,然后用这些均值或最大值参与后续的训练,这个过程就是【池化】。

池化的优点
- 显著减少了参数数量
- 池化单元具有平移不变性 (translation invariant)
有一个 12×12 的 feature map (隐藏层的一个单元提取到的卷积特征矩阵),池化区域的大小为 6×6,那么池化后,feature map 的维度变为 2×2。
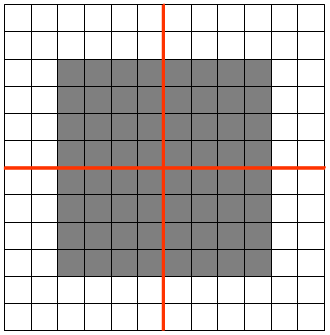
假设原 feature map 中灰色元素的值为 1,白色元素的值为 0。如果采用 max pooling,那么池化后左上角窗口的值为 1。如果将图像向右平移一个像素:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 785
785











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









