






深度学习组成模块
输入/输出
模型
损失函数
优化器(优化参数,减小损失函数)
一、损失函数
查看:https://zhuanlan.zhihu.com/p/58883095
1、目的:用来评价模型的性能好坏,损失函数越好,通常模型的性能越好。
(表示模型的预测值和真实值不一样的程度)
2、常用的损失函数

PS:划重点
KL散度:包括熵和交叉熵
熵:
−
∑
i
=
1
n
p
i
l
o
g
p
i
-\sum_{i=1}^{n} p_ilogp_i
−∑i=1npilogpi
二分类:
−
p
i
l
o
g
p
i
−
(
1
−
p
i
)
l
o
g
(
1
−
p
i
)
-p_ilogp_i-(1-p_i)log(1-p_i)
−pilogpi−(1−pi)log(1−pi)
交叉熵:
KL散度的一部分,表示两个概率分布之间的差异,可以通过最小化交叉熵来得到目标概率分布的近似分布。
假设p是真实分布,q是拟合分布(这里的分布可以理解为标签和预测值),则
∑
i
=
1
n
p
(
x
i
)
l
o
g
p
(
x
i
)
\sum_{i=1}^{n} p(x_i)logp(x_i)
∑i=1np(xi)logp(xi)是已知的,
交叉熵公式化简后得到:
−
∑
i
=
1
n
p
(
x
i
)
l
o
g
q
(
x
i
)
-\sum_{i=1}^{n} p(x_i)logq(x_i)
−∑i=1np(xi)logq(xi)
对于二分类的交叉熵:
−
p
(
x
i
)
l
o
g
q
(
x
i
)
−
(
1
−
p
(
x
i
)
)
l
o
g
(
1
−
q
(
x
i
)
)
-p(x_i)logq(x_i)-(1-p(x_i))log(1-q(x_i))
−p(xi)logq(xi)−(1−p(xi))log(1−q(xi))
二、优化器
https://blog.csdn.net/oppo62258801/article/details/103175179
1、(Mini)SGB
原理:小批量梯度下降法(mini-batch gradient descent),使用一部分批量数据来计算梯度值更新参数
公式:
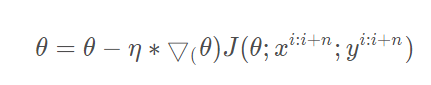
优点:
(1)可以以更小的方差来更新参数,参数收敛的过程波动更小;
(2)获得比批梯度下降法更快的运行速度。
问题:
(1)选择一个合适的学习率是困难的。学习率太小会导致收敛太慢,太大会影响模型的收敛,有可能在最小值附近不断波动甚至偏离最小值。
(2)对于不同的参数使用相同的学习率更新是不合理的。如果数据是稀疏的,就不能使用相同的学习率来更新了,对于出现次数少的特征,我们对其执行更大的学习率;
(3)高度非凸误差函数普遍出现在神经网络中,在优化这类函数时,另一个关键的挑战是使函数避免陷入无数次优的局部最小值。Dauphin等人指出出现这种困难实际上并不是来自局部最小值,而是来自鞍点,即那些在一个维度上是递增的,而在另一个维度上是递减的。这些鞍点通常被具有相同误差的点包围,因为在任意维度上的梯度都近似为0,所以SGD很难从这些鞍点中逃开。
Exponential moving average
2、Momentum
原理:动量法,帮助SGD在相关方向上加速并抑制摇摆的方法,利于处理非平稳梯度。即将上一次更新量的一个分量γ增加到当前的更新量中。
公式:

动量项γ通常可以设置成0.9。
上面公式(1)等号后面,γ表示使用上次更新量的权重,决定了动量的大小,η部分跟前面SGD参数更新量完全相同;
公式(2)中,不再像前面SGD公式中直接将学习率大小体现出来了,而是整个的包含在νt中了。在后面的其他改进SGD的优化算法中也是类似的做法。
理解:
从山坡上往下推一个球,在往下滚动的过程中累积动量,速度越来越快,如果有空气阻力,则γ<1。对于参数更新也是如此,对于在当前梯度点处有相同方向的维度,动量项增加,对于在梯度点处改变方向的维度,其动量项减小,因此我们可以获得更快的收敛速度,同时可以减小频繁的波动。
3、Adagrad-自适应梯度
Adagrad是一种适应参数的梯度下降优化算法,其自适应性可以个性化到特征级别,出现次数较少的特征的,会使用更大的学习率,出现次数较多的特征,会使用较小的学习率,因此Adagrad适合于稀疏数据的深度神经网络模型。
公式:
在t时刻,基于对不同参数计算过的历史梯度,Adagrad修正了每一个参数的学习率
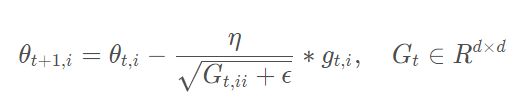
其中,Gt是一个对角矩阵,对角线上的元素ii是从开始截止到t时刻为止,所有关于θi的梯度的平方和:
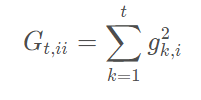
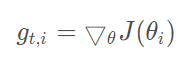
优点:
无需手动调整学习率,基本上采用 0.01 即可
缺点:
由于其在分母中累加梯度的平方,每次增加一个正项,随着训练过程积累,会导致学习率越来越小,当学习率变得无限小时Adagrad算法将无法获得额外的信息更新。
4、Adadelta
解决Adagrad学习速率单调递减的缺点,Adadelta算法完全移除了学习率,不再需要人工设置学习率参数。
公式:
将梯度的平方递归地表示成所有历史梯度的均值,因此在t时刻的均值只取决于先前的均值和当前的梯度:
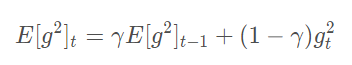
参数更新:

5、RMSprop
解决Adagrad的学习率下降太快的问题(Adadelta特例)

RMSprop也是将学习率分解成平方梯度的指数衰减的平均,对于学习率η,建议选择 0.001。
6、Adam-自适应矩估计
会对每一个参数会计算出自适应学习率的算法,Momentum和RMSprop的结合。
公式:
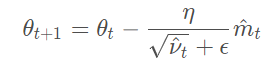
Adam中是通过计算偏差矫正的一阶矩估计和二阶矩估计来抵消偏差的:
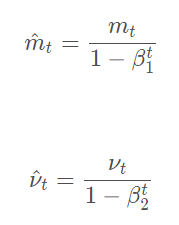
Adam也会计算出来一个指数衰减的历史平方梯度的平均vt ,Adam同时还计算一个指数衰减的历史梯度的平均mt,类似于动量:
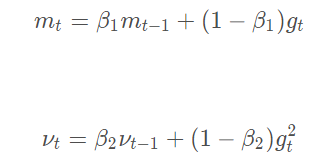
Adam作者建议β1、β2分别取默认值0.9、0.999就好,ϵ为10−8。
优点:相较于其他优化器,表现较好
缺点:不容易收敛
三、Normalization
https://zhuanlan.zhihu.com/p/33173246
https://blog.csdn.net/ft_sunshine/article/details/99203548
(在激活函数之前使用)
1、为什么需要Normalization
共识:独立同分布的数据可以简化常规机器学习的训练,提升模型预测能力。
目的:
独立 --> 去除特征间的相关性;
同分布 --> 使得所有特征具有相同的均值和方差
公式:
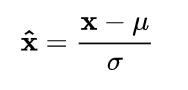
图像:

Batch Normalization
计算时对batch分别进行。将数据按特征(按列进行)减去其均值,并除以其方差。得到的结果是,对于每个特征来说所有数据都聚集在0附近,方差为1。
Layer Normalization
计算时对每个特征分别进行。将数据按特征(按列进行)减去其均值,并除以其方差。得到的结果是,对于每个特征来说所有数据都聚集在0附近,方差为1。
四、激活函数
https://zhuanlan.zhihu.com/p/122267172
1、sigmoid
公式:
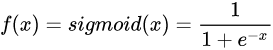
图像:

导数:
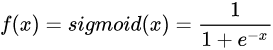
导函数图像为:

优点:sigmoid函数可以将实数映射到(0,1) 区间内。平滑、易于求导。
缺点:
- 激活函数含有幂运算和除法,计算量大;
- 反向传播时,很容易就会出现梯度消失的情况,从而无法完成深层网络的训练;
- sigmoid的输出不是0均值的,这会导致后一层的神经元将得到上一层输出的非0均值的信号作为输入,不便于计算。
2、tanh
定义:
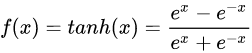
图像:

导数:
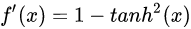
导数图像:

tanh激活函数是0均值的,相比sigmoid函数更’陡峭’了,对于有差异的特征区分得更开了,tanh也不能避免梯度消失问题。
3、ReLU
公式:
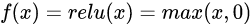
图像:

优点:
1.计算量小;
2.激活函数值为正数时,导数维持在1,可以有效缓解梯度消失和梯度爆炸问题;
3.使用Relu会使部分神经元为0,这样就造成了网络的稀疏性,并且减少了参数之间的相互依赖关系,缓解了过拟合问题的发生。
缺点:
输入激活函数值为负数的时候,会使得输出为0,那么这个神经元在后面的训练迭代的梯度就永远是0了(由反向传播公式推导可得),参数w得不到更新,也就是这个神经元死掉了。这种情况在你将学习率设得较大时(网络训练刚开始时)很容易发生(波浪线一不小心就拐到负数区域了,然后就拐不回来了)。
解决办法:一些对Relu的改进,如ELU、PRelu、Leaky ReLU等,给负数区域一个很小的输出,不让其置0,从某种程度上避免了使部分神经元死掉的问题。
4、LeakyReLU
公式:
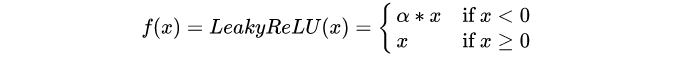
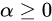
图像:

LeakyReLU在神经元未激活时,它仍允许赋予一个很小的梯度,避免ReLU死掉的问题。值得注意的是LeakyReLU是确定的标量,不可学习。
5、PReLU
公式:
可学习参数:
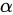
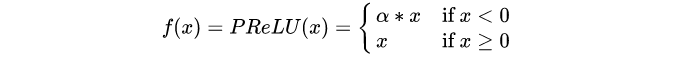
注意区分PReLU和LeakyReLU,PReLU的 [公式] 是一个可学习的数组,尺寸与 x 相同。
PReLU是针对ReLU的一个改进型,在负数区域内,PReLU有一个很小的斜率,这样也可以避免ReLU死掉的问题。相比于ELU,PReLU在负数区域内是线性运算,斜率虽然小,但是不会趋于0,这算是一定的优势。
6、ELU(指数线性单元)
公式:
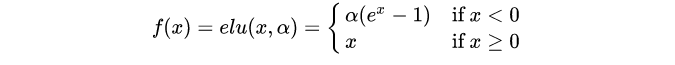
图像:

优点:右侧线性部分使得elu能够缓解梯度消失,而左侧软饱部分能够让ELU对输入变化或噪声更鲁棒。elu的输出均值接近于零。
五、评价指标
https://codewithzichao.github.io/2020/05/12/NLP-%E5%88%86%E7%B1%BB%E4%B8%8E%E5%8C%B9%E9%85%8D%E7%9A%84%E5%90%84%E7%B1%BB%E8%AF%84%E4%BB%B7%E6%8C%87%E6%A0%87/
符号介绍:
TP(true positive)、FP(false positive)、FN(false nergative)、TN(true negative)。表格如下:

accuracy与error rate:

二分类评价指标:
precision/recall/F1 score
















 2453
2453











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









