







认识Lucene
Lucene是一款高性能的、可扩展的信息检索(IR)工具库。它是一款以JAVA实现的成熟、自由、开源的软件项目,是Apache软件基金会的一个项目,并且基于Apache软件许可协议授权。
1.Lucene能做什么?
Lucene只是一个软件类库,可以理解为是一个工具箱,而并不是一套完整的搜索程序,当然如果你找一个比Lucene封装的更完整的搜索程序,可以去了解Lucene姊妹开源软件solr。Lucen只专注于建立索引和搜索功能,Lucene帮你实现了较为复杂的索引建立过程和搜索过程,使用者只需要调用Lucene封装好的API,即可以是自己的程序立刻拥有搜索功能。此外Lucene也不关心原始内容的获取,这个需要使用者自己想办法解决,再次强调一下,Lucene只关心建立索引和实现搜索这两个部分。如果大家对爬取内容和网络爬虫感兴趣,可以研究一下最后一节“附加”部分提到的开源软件。
2.Lucene的历史
- Lucene最初是由Doug Cutting编写的,开源在SourceForge。
- 2001年9月,Lucene加入Apache软件基金会的Jakarta家族,Jakarta大家应该很眼熟吧,想想经典的JAVA web容器Tomcat。
- 2005年该项目一跃成为顶级的Apache项目。
- 2010年,Lucene的里程碑版本3.0面世。
- 至今为止,Lucene已布了7.x版本。
3.Lucene在搜索程序中担任的角色
Lucene只负责索引和搜索两个部分,其他的如:文本的获取,则由使用者自己解决。

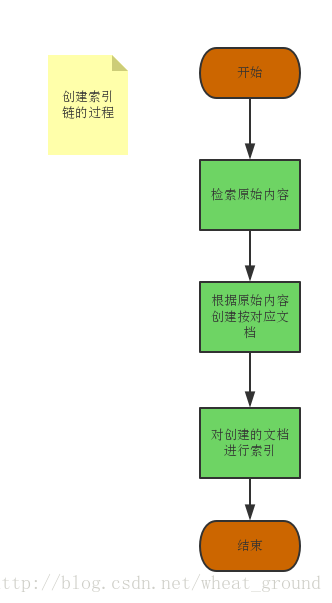
4.建立索引的过程
建立索引的过程如下:
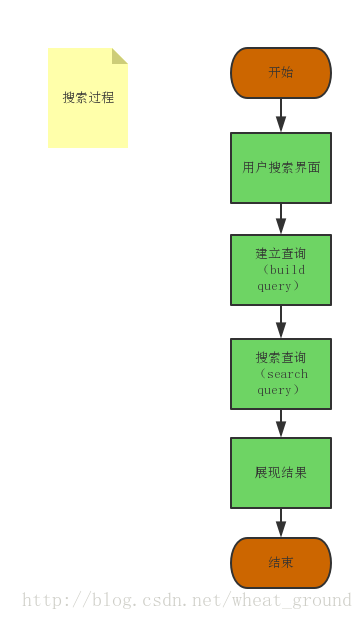
5.搜索索引的过程
搜索的过程如下:
6.实战
- 准备文本内容
- 编写索引程序

package com.lucene._1_1;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
import java.io.*;
import java.lang.annotation.Documented;
/**
* Created by xun.zhang on 2017/10/26.
*/
public class Indexer {
public static void main(String[] args) throws IOException {
if (args.length != 2) {
throw new IllegalArgumentException("Usage: Java " + Indexer.class.getName() + " <index dir> <data dir>");
}
String indexDir = args[0];
String dataDir = args[1];
long start = System.currentTimeMillis();
Indexer indexer = new Indexer(indexDir);
int numIndexed;
try{
numIndexed = indexer.index(dataDir, new TextFilesFilter());
}finally {
indexer.close();
}
}
private IndexWriter writer;
public Indexer(String indexerDir) throws IOException {
Directory dir = FSDirectory.open(new File(indexerDir));
writer = new IndexWriter(dir, new StandardAnalyzer(Version.LUCENE_30), true, IndexWriter.MaxFieldLength.UNLIMITED);
}
public void close() throws IOException {
writer.close();
}
public int index(String dataDir, FileFilter filter) throws IOException {
File[] files = new File(dataDir).listFiles();
for (File f : files) {
if(!f.isDirectory() && !f.isHidden() && f.exists() && f.canRead() && (filter == null || filter.accept(f))) {
indexFile(f);
}
}
return writer.numDocs();
}
private static class TextFilesFilter implements FileFilter {
public boolean accept(File path) {
return path.getName().toLowerCase().endsWith(".txt");
}
}
protected Document getDocument(File f) throws IOException {
Document doc = new Document();
doc.add(new Field("contents", new FileReader(f)));
doc.add(new Field("filename", f.getName(), Field.Store.YES, Field.Index.NOT_ANALYZED));
doc.add(new Field("fullpath", f.getCanonicalPath(), Field.Store.YES, Field.Index.NOT_ANALYZED));
return doc;
}
private void indexFile(File f) throws IOException {
System.out.println("Indexing " + f.getCanonicalPath());
Document doc = getDocument(f);
writer.addDocument(doc);
}
}
- 索引核心类及流程
- 建立搜索程序
package com.lucene._1_1;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.queryParser.ParseException;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
import java.io.File;
import java.io.IOException;
/**
* Created by xun.zhang on 2017/10/26.
*/
public class Searcher {
public static void main(String[] args) throws IOException, ParseException {
if (args.length != 2) {
throw new IllegalArgumentException("Usage: Java " + Indexer.class.getName() + " <index dir> <data dir>");
}
String indexDir = args[0];
String q = args[1];
search(indexDir, q);
}
public static void search(String indexDir, String q) throws IOException, ParseException {
Directory dir = FSDirectory.open(new File(indexDir));
IndexSearcher is = new IndexSearcher(dir);
QueryParser parser = new QueryParser(Version.LUCENE_30, "contents", new StandardAnalyzer(Version.LUCENE_30));
Query query = parser.parse(q);
// System.out.println(query.getClass());
long start = System.currentTimeMillis();
TopDocs hits = is.search(query, 10);
long end = System.currentTimeMillis();
System.err.println("Found " + hits.totalHits + " document(s) (in " + (end - start) + " milliseconds) that matched query '" + q + "':");
for (ScoreDoc scoreDoc:hits.scoreDocs
) {
Document doc = is.doc(scoreDoc.doc);
System.out.println(doc.get("fullpath"));
}
}
}
- 搜索核心类及流程
- 常见的搜索理论模型
- 纯布尔模型(Pure Boolean model),文档不管是否匹配查询请求,都不会被评分,在该模型下,匹配文档与评分无关,也无序。一条查询语句仅获取所有匹配文档集合的一个子集。
- 向量空间模型(Vector space model),查询语句和文档都是高维空间的向量模型,每一个独立的项都是一个维度。查询语句和文档之间的相关性和相似性由各自的向量之间的距离计算获得。
- 概率模型(Probabilistic model),在该模型中,采用全概率方法来计算文档和查询语句的匹配概率。
Lucene在实现上使用了向量空间模型和纯布尔模型,并能针对具体搜索采用什么模型。
7.附加:目前开源爬虫软件
- Solr,Apache Lucene项目的子项目,支持从关系数据库和xml文档中提取原始数据,以及能够通过集成Tika来处理复杂文档。
- Nutch,另外一个Apache Lucene的子项目,它包含大规模的爬虫工具,能够抓取和分辨Web站点数据。
- Grub,比较流行的开源Web爬虫工具。
- Heritrix,是一款开源的Internet文档搜索程序。
- Aperture,他支持从Web站点、文件系统和邮箱中抓取,并解析和索引其中的文本数据。
- 谷歌企业连接管理工程,提供大量针对非Web形式的内容连接方案。
参考:
Lucene实战(第2版)著:Michael McCandles、Erik Hatcher、Otis Gospodnetic 译:牛长流、肖宇














 113
113











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









