







BLIP3-o 的核心特点
BLIP3-o 是一个统一的多模态模型,结合了自回归模型和扩散模型的优势,实现了图像理解与生成的双 SOTA(State-of-the-Art)。其核心特点包括:
-
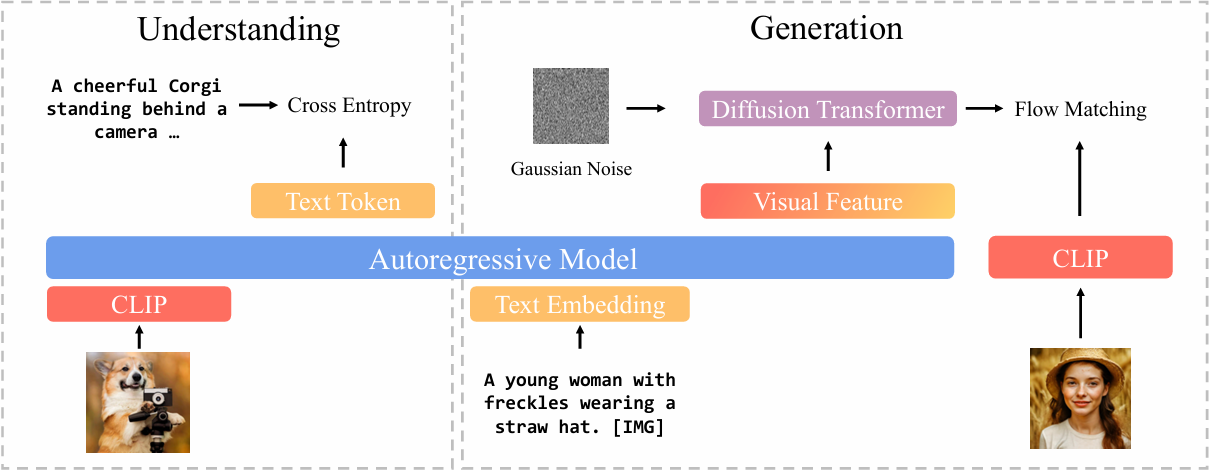
自回归模型与扩散模型的结合:自回归模型生成中间视觉特征,捕捉文本描述中的语义信息,而扩散模型则生成最终的图像。这种结合使得模型在生成高质量图像的同时,能够准确理解图像内容。
-
CLIP 特征扩散:BLIP3-o 使用 CLIP 模型对图像进行编码,生成语义丰富的特征向量。这些特征向量比传统的 VAE 特征更紧凑且信息量更大,扩散模型基于这些特征生成与目标图像相似的特征向量,从而实现高质量的图像生成。
-
顺序预训练策略:模型首先进行图像理解任务的预训练,确保具备强大的图像理解能力。在此基础上,冻结自回归模型的权重,仅对扩散模型进行训练,实现高效的图像生成。
-
流匹配损失函数:BLIP3-o 使用流匹配损失函数训练扩散模型,该损失函数能更好地捕捉图像特征的分布,生成更高质量的图像。同时,流匹配损失函数引入随机性,使模型能够生成多样化的图像。
-
指令调整数据集:基于 GPT-4o 生成的多样化提示,团队创建了一个包含 60k 高质量提示图像对的数据集,用于微调模型,提高指令遵循能力和视觉审美质量。
-
主要功能
BLIP3-o 支持多种多模态任务,包括:
- 文本到文本:生成与图像相关的描述性文本。
- 图像到文本:对输入的图像进行理解并生成描述性文本,支持多种图像理解任务,如视觉问答(VQA)和图像分类。
- 文本到图像:根据输入的文本描述生成高质量的图像。
- 图像到图像:对输入的图像进行编辑和修改,生成新的图像。
- 混合训练:支持图像生成和理解任务的混合训练,提高模型的综合性能。

开源与资源
为了推动图像理解和生成领域的进一步发展,BLIP3-o 的代码、模型权重和数据集已全部开源。这一开源举措为广大研究者提供了宝贵的资源,有助于加速相关领域的研究进程,激发更多创新想法的产生。

体验与展望
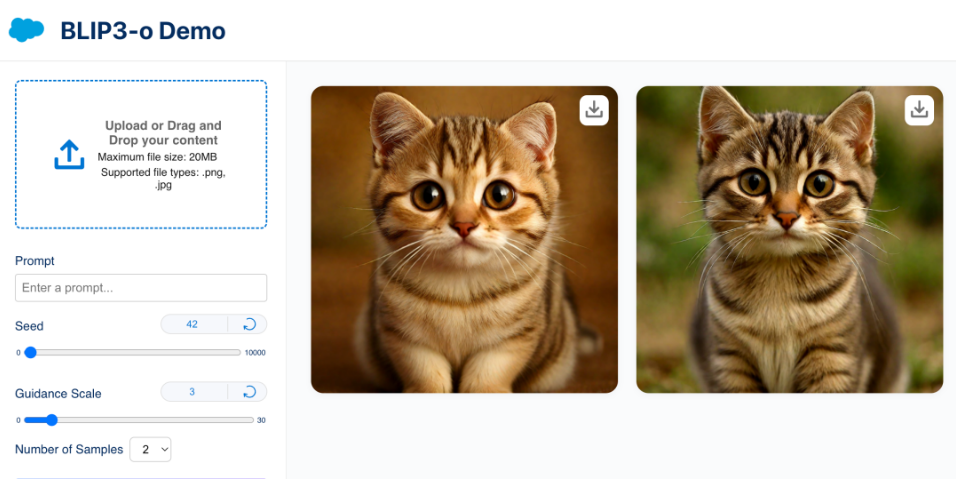
BLIP3-o 的 Demo 体验网站已上线,用户可以免费体验其强大的图像理解和生成能力。随着 BLIP3-o 的不断应用和发展,它将在多模态模型领域带来更多惊喜,推动该领域的进一步发展。
BLIP3-o 的成功不仅展示了多模态模型的巨大潜力,也为未来的研究提供了新的方向和工具。期待更多研究者利用这一开源资源,推动多模态模型技术的创新与突破。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











