









基于社交网络的情绪化分析IV
By 白熊花田(http://blog.csdn.net/whiterbear) 转载需注明出处,谢谢。
前面进行了微博数据的抓取,简单的处理,相似度分析,后面两篇进行学校微博的情感分析。
微博情感分析
这里试图通过字典分析的方式计算学校微博的情感倾向,主要分为积极情感,消极情感,客观。
这里字典分析的情感分析和机器学习方式进行情感分析均参考rzcoding的博客,这里只是根据他的思路和代码改装成了微博的情感分析。
字典分析
字典分析的原理是,给定一句微博,判断这句微博中是否出现过积极或者消极的情感词,如果出现,那么寻找修饰该情感词的程度副词,然后依据定义的规则计算积极和消极情感分值。
字典分析结果
使用了matplotlib模块进行结果的显示。
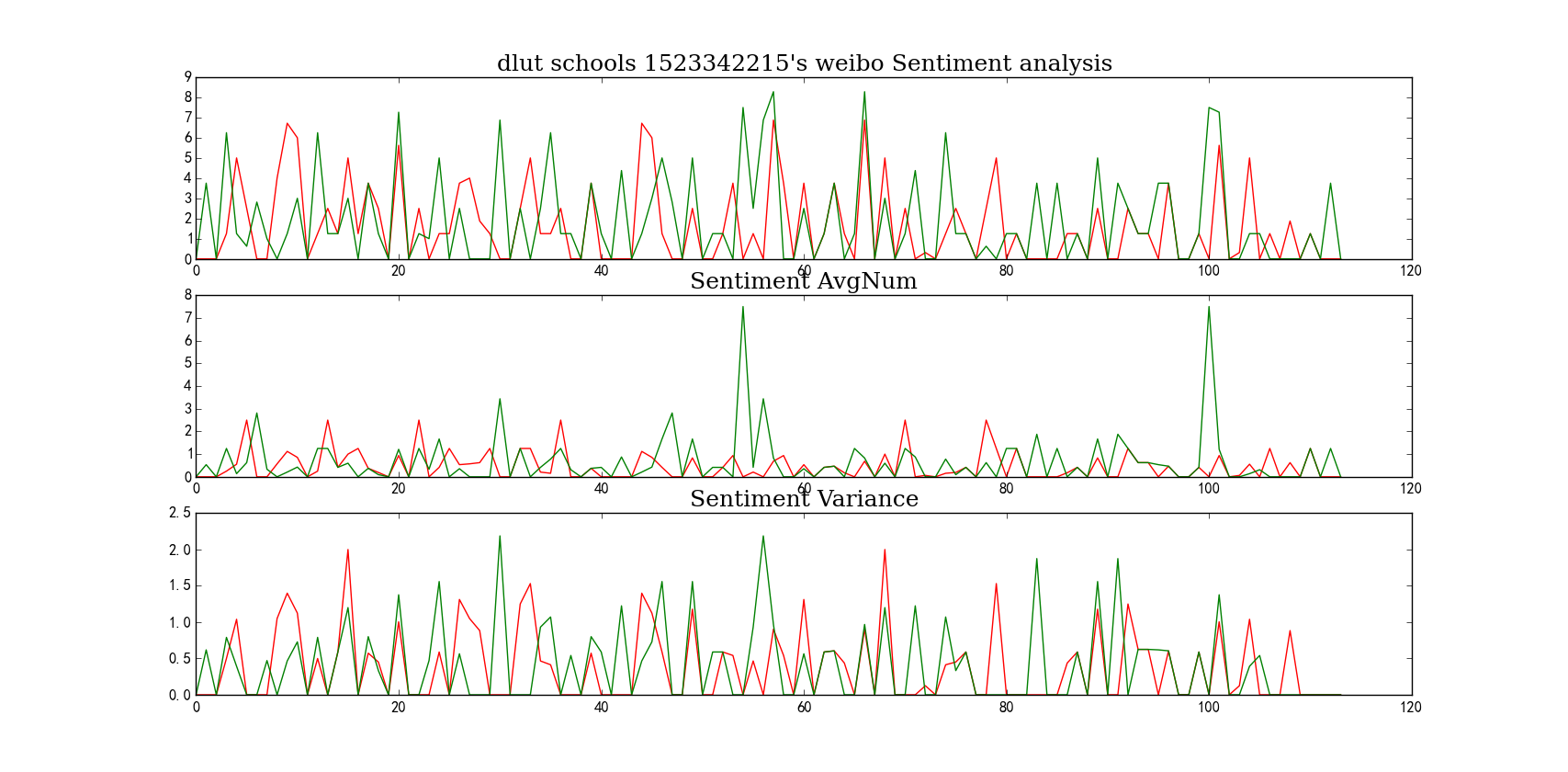
图表示字典分析dlut(大连理工大学)的一个用户的情感分析结果,其中红色表示积极的值(依次为总值,均值,方差),绿色表示消极的值(依次为总值,均值,方差)
字典分析所有学校的结果。
| 学校名称 | 积极的微博 | 消极的微博 | 客观的微博 |
|---|---|---|---|
| 大连理工大学 | 32.7% | 25.5% | 41.8% |
| 清华大学 | 32.8% | 23.6% | 43.7% |
| 北京大学 | 33.9% | 24.0% | 42.1% |
| 南京大学 | 31.2% | 25.6% | 43.3% |
| 华东政法大学 | 32.4% | 29.0% | 38.6% |
从上表可以看出,一个学校所发的微博积极的微博数目较大于消极的微博数目,积极的微博比例一般在32%左右,而消极的微博一般在24%左右。忽略掉客观的微博,那么积极的微博和消极微博数目比例大体在1:1的水平上。
机器学习
利用机器学习的方法对微博进行情感分析,即使用相关监督的学习算法,如贝叶斯算法,使用标注的情感文本进行学习,训练得到分类器,最后使用该分类器进行情感分类并进行图形化显示。
具体步骤为:首先手工标注微博,以积极,消极和客观三种状态来标识。接着,使用所有词,双词和卡方统计等方式获取词的特征,然后,使用多种机器学习模型进行训练,筛选得到最佳精度的分类器,最后,使用该分类器进行微博的情感分类,如:如果积极的情感概率则为积极微博。
机器学习分析结果
机器学习分析所有学校的结果。
| 学校名称 | 积极的微博 | 消极的微博 | 客观的微博 |
|---|---|---|---|
| 大连理工大学 | 12.6% | 28.4% | 59.0% |
| 清华大学 | 8.7% | 20.3% | 70.9% |
| 北京大学 | 8.5% | 19.0% | 72.6% |
| 南京大学 | 9.8% | 23.6% | 66.6% |
| 华东政法大学 | 11.9% | 30.6% | 57.4% |
这里的结果与用词典分析的结果不太一样,在词典分析中,用户发的积极的微博数目大于消极的微博数目,而这里,五所大学中,所有的学校所发的积极的微博比例均小于消极的微博,积极微博大概占到10%左右,消极的微博约占到22%左右,客观的微博占到65%左右。除去客观的微博,积极微博和消极的微博的比例大体相当于1:2。实验中分类器的准确度达到70%。
影响实验结果的因素:其一,该结果是基于分类器得出的结果,而分类器又是基于标注的微博数据,所以,自己标注的微博数据会对分类器的判定有着一定的影响;其二,由于中文语义丰富,在不同的语境下有着不同的含义,这样会导致分类器的判别有一定的难度从而造成相关的误差。
总结
本次毕设研究的主题为分析和了解不同的群体在社交网络上是如何表达情绪的及其表达情绪的倾向。为此,本研究设计并实施了一整套从数据抓取到分析的流程,设计了爬虫去抓取数据,设计了相应的算法去分析和统计和处理数据。最终,本研究做到了在一定层面上展现了社交网络用数据的特性,不同群体用词的差异性,也给出了在社交网络上不同的群体是如何表达情绪及其倾向这一问题的解答。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









