







RegExp对象
RegExp是一个全局JavaScript对象,保存有关正则表达式模式匹配信息的固有全局对象,它和正则表达式对象不是一回事(把RegExp当作全局静态类,正则表达式当作普通类,需要实例化就行了)。 官方文档说它没有方法 ,有以下属性:| 属性 | 简写 | 初始值 | 说明 |
|---|---|---|---|
| index | | -1 | ie专有,返回字符位置,它是查找字符串中第一个成功匹配的开始位置。只读。 |
| input | | "" | 返回执行规范表述查找的字符串。只读。 |
| lastIndex | | -1 | ie专有,返回下一次匹配动作开始的位置。(IE8中测试已不存在) |
| lastMatch | $& | "" | 返回任何正则表达式搜索过程中的最后匹配的字符。只读。 |
| lastParen | $+ | "" | 如果有的话,返回任何正则表达式查找过程中最后匹配的子匹配。只读。 |
| leftContext | | "" | 返回被查找的字符串中从字符串开始位置到最后匹配之前的位置之间的字符。只读。 |
| rightContext | | "" | 返回被搜索的字符串中从最后一个匹配位置开始到字符串结尾之间的字符。只读。 |
| $1 - $9 | $1 - $9 | "" | 返回九个在模式匹配期间找到的、最近保存的部分。只读。 |
一个例子:
这是一个显示Reg对象所有属性的方法:
function showRegExpInfo(){
var s;
s="index:<span>"+RegExp.index+"</span><br/>";//已定义了css让span显示为红色
s+="input:<span>"+RegExp.input+"</span><br/>";
s+="lastIndex:<span>"+RegExp.lasIndex+"</span><br/>";
s+="lastMatch:<span>"+RegExp.lastMatch+"</span><br/>";
s+="lastParen:<span>"+RegExp.lastParen+"</span><br/>";
s+="leftContext:<span>"+RegExp.leftContext+"</span><br/>";
s+="rightContext:<span>"+RegExp.rightContext+"</span><br/>";
s+="$1:<span>"+RegExp.$1+"</span> $2:<span>"+RegExp.$2+"</span><br/>";
s+="$3:<span>"+RegExp.$3+"</span> $4:<span>"+RegExp.$4+"</span><br/>";
return s;
}
document.write(showRegExpInfo());//注意在此之前不要使用任何正则表达式对象来检索字符串,否则RegExp中的一些属性就会被改变 不同浏览器的显示:
| firefox | IE8 |
|---|---|
| index:undefined input: lastIndex:undefined lastMatch: lastParen: leftContext: rightContext: $1: $2: $3: $4: | index:-1 input: lastIndex:undefined lastMatch: lastParen: leftContext: rightContext: $1: $2: $3: $4: |
现在我在第14行前插入一段正则表达式执行代码,形成如下样式:
function showRegExpInfo(){
var s;
s="index:<span>"+RegExp.index+"</span><br/>";//已定义了css让span显示为红色
s+="input:<span>"+RegExp.input+"</span><br/>";
s+="lastIndex:<span>"+RegExp.lasIndex+"</span><br/>";
s+="lastMatch:<span>"+RegExp.lastMatch+"</span><br/>";
s+="lastParen:<span>"+RegExp.lastParen+"</span><br/>";
s+="leftContext:<span>"+RegExp.leftContext+"</span><br/>";
s+="rightContext:<span>"+RegExp.rightContext+"</span><br/>";
s+="$1:<span>"+RegExp.$1+"</span> $2:<span>"+RegExp.$2+"</span><br/>";
s+="$3:<span>"+RegExp.$3+"</span> $4:<span>"+RegExp.$4+"</span><br/>";
return s;
}
var re=/x(y)+(\d+)/g;//检索一个x后面跟着n(n>=1)个y,再跟着一串数字的字符串
var arr1 = re.exec("a1xyxy123aab0xyyy3xyyy");
var arr2 = re.exec("a1xyxy123aab0xyyy3xyyy");
document.write(showRegExpInfo());
| firefox | IE8 |
|---|---|
| index:undefined input:a1xyxy123aab0xyyy3xyyy lastIndex:undefined lastMatch:xyyy3 lastParen:3 leftContext:a1xyxy123aab0 rightContext:xyyy $1:y $2:3 $3: $4: | index:13 input:a1xyxy123aab0xyyy3xyyy lastIndex:undefined lastMatch:xyyy3 lastParen:3 leftContext:a1xyxy123aab0 rightContext:xyyy $1:y $2:3 $3: $4: |
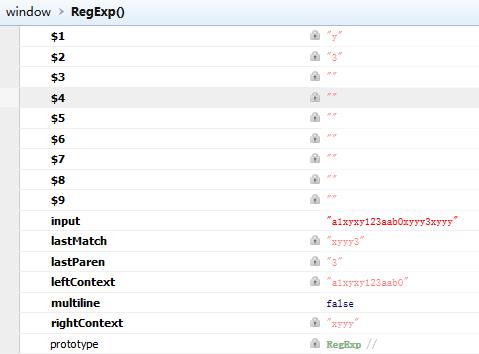
你可能开始就有疑惑,为什么我在上面的代码中声明了两个对象arr1和arr2,就是为了说明一次匹配过程中RegExp到底做了些什么:下面的分析基于执行完arr1=re.exec("a1xyxy123aab0xyyy3xyyy"),arr2还没有执行(你可以打断点自己查看)。
$1-$9:保存的是最近一次执行模式匹配中捕捕获的子模式匹配(我把正则表达式中的圆括号中间的部分称为子匹配)。在上面的代码中声明arr1时,re.exec匹配到了xy123,第一子模式(y) 捕获了xy123中的y,这个y会被保存在$1中,随后的 (\d+) 捕获了xy123中的123,同样这个$2会保存这个值。
input:保存的是上一次被执行匹配的String:a1xyxy123aab0xyyy3xyyy。
lastMatch:保存的就是xy123。
lastParen :最后匹配的子模式是(\d+)捕获的3.
leftContext :匹配的字符串是xy123,那么它的左边就是a1xy。
rightContext :同上,其右边就是aab0xyyy3xyyy。
当声明arr2=re.exec("a1xyxy123aab0xyyy3xyyy")执行完后,其匹配的字符串是xyyy3,执行完后的属性在上面的截图中,你可以自己推算对比下。
正则表达式对象
属性:
| 属性 | 初始值 | 说明 |
|---|---|---|
| lastIndex | 0 | 返回下一次匹配动作开始的位置 |
| source | "" | 返回对象的正则表达式字符串(pattern)。只读。 |
| global | false | 是否全文查找。只读。 |
| ignoreCase | false | 是否区分大小写。只读。 |
| multiline | false | 是否多行查找。只读。 |
| sticky | false | (在脚本调试时发现此属性,不清楚是代表什么,firefox) |
方法:
| 方法 | 描述 |
|---|---|
| compile | 编译正则表达式。 |
| exec | 检索字符串中指定的值。返回找到的值,并确定其位置。 |
| test | 检索字符串中指定的值。返回 true 或 false。 |
Js创建regular expression对象有两种方式:
- var re = /pattern/[flags]
- var re = RegExp( "pattern", ["flags"] )
其中,pattern为要使用的正则表达式模式。
flags为标志,有三种,可组合使用:
| 修饰符 | 描述 |
|---|---|
| i | 执行对大小写不敏感的匹配。 |
| g | 执行全局匹配(查找所有匹配而非在找到第一个匹配后停止)。 |
| m | 执行多行匹配(可以查看元字符 ^ 和 & 的说明,更好的了解m的作用)。 |
var re=/\d{1,}[a-z]+/ig;
var re=new RegExp("\d{1,}[a-z]+","ig");支持正则表达式的String对象的方法
| 方法 | 描述 |
|---|---|
| search | 检索与正则表达式相匹配的值。 |
| match | 找到一个或多个正则表达式的匹配。 |
| replace | 替换与正则表达式匹配的子串。 |
| spit | 把字符串分割为字符串数组。 |
下面的例子用来说明正则表达式对象和String对象的相关方法:
function showRegularObjInfo(re){
var _str="a1xyxy123aab0xyyy3xyyy \nxy888";
arr = re.exec(_str);
str_match=_str.match(re);
document.write("<span>"+re.source+ "</span>.exec(str):<span>" + arr+"</span>");
document.write("<br/>");
document.write("str.match("+ re.source+"):<span>"+ str_match+"</span><br/>");
}
document.write("<p style='color:blue'>global:true;multiline:false<p/><br/>")
var re=/x(y)+(\d+)/g;//检索一个x后面跟着n(n>=1)个y,再跟着一串数字的字符串
showRegularObjInfo(re);
document.write("<p style='color:blue'>global:false;multiline:false<p><br/>")
re=/x(y)+(\d+)/;//没有g标志,会默认为false,可以看上面的属性表
showRegularObjInfo(re);
document.write("<p style='color:blue'>global:true;multiline:false<p/><br/>")
re=/^x(y)+(\d+)$/g;//注意pattern,加了^和$
showRegularObjInfo(re);
document.write("<p style='color:blue'>global:true;multiline:true<p/><br/>")
re=/^x(y)+(\d+)$/mg;//开启multiline
showRegularObjInfo(re);firefox中执行结果如下:
- global:true;multiline:false
- x(y)+(\d+).exec(str):xy123,y,123
- str.match(x(y)+(\d+)):xy123,xyyy3,xy888
- global:false;multiline:false
- x(y)+(\d+).exec(str):xy123,y,123
- str.match(x(y)+(\d+)):xy123,y,123
- global:true;multiline:false
- ^x(y)+(\d+)$.exec(str):null
- str.match(^x(y)+(\d+)$):null
- global:true;multiline:true
- ^x(y)+(\d+)$.exec(str):xy888,y,888
- str.match(^x(y)+(\d+)$):xy888
这个例子主要说明正则表达式的exec和String.match,首先详细地说明这两个方法的功能:
arr = re.exec(str):用re中的模式从str中匹配(匹配从 str[re.lastIndex] 处开始,关于这一点后面会细说),返回一个string数组arr,arr[0]存放的是成功匹配出的字符串,arr[n](ps:n>=1)依次存放的是子模式的捕获,此方法执行后会更改re.lastindex的值为当前找到的字符串的最后一个字符的位置+1。这个匹配过程与globle属性无关,从输出的第2行与第5行可看出。
arr=str.match(re):用re中的模式从str中匹配(匹配从str[0]处开始),返回一个string数组arr,当globle=true时,arr[n](ps:n>=0)存放的是顺序找到的所有匹配字符串,从输出第3行可以看出;当globle=false时,返回的arr[0]是第一个匹配中的字符串,后面依次是子模式的捕获,从输出第6行可以看出,这一点同re.exec很相似,但是要注意的是str.match总是从str[0]开始检索。
m标志:例子中str="a1xyxy123aab0xyyy3xyyy\nxy888",这其中有一个换行符\n,当pattern为 “x(y)+(\d+)” (没有字符开始和结束标志:^,$)时,pattern能匹配中\n之后的字符串,因为是全文搜索,换不换行没有影响。但是当pattern为“/^x(y)+(\d+)$/”(意为匹配如下一段字符:以x开头,后面跟着多个y,再跟着多个数字,然而是结尾)时如果不打开multiline标志,从str中根本找不到这样的字符串;当打开时,str会从\n处分成两段,分别匹配。这个标志的作用可以从输出的7-12行看出。
正则表达式的lastIndex:
从前文中可知,re.exec(str)是从str[re.lastIndex]种开始检索,而str.match总是从str[0]开始。我将上面的例子稍作修改来验证这一点(只是将第三行代码执行了两遍):
function showRegularObjInfo(re){
var _str="a1xyxy123aab0xyyy3xyyy \nxy888";
arr = re.exec(_str); //re.lastIndex被修改
arr = re.exec(_str); //重复执行
str_match=_str.match(re);
document.write("<span>"+re.source+ "</span>.exec(str):<span>" + arr+"</span>");
document.write("<br/>");
document.write("str.match("+ re.source+"):<span>"+ str_match+"</span><br/>");
}
document.write("<p style='color:blue'>global:true;multiline:false<p/><br/>")
var re=/x(y)+(\d+)/g;//检索一个x后面跟着n(n>=1)个y,再跟着一串数字的字符串
showRegularObjInfo(re);
document.write("<p style='color:blue'>global:false;multiline:false<p><br/>")
re=/x(y)+(\d+)/;//没有g标志,会默认为false,可以看上面的属性表
showRegularObjInfo(re);
document.write("<p style='color:blue'>global:true;multiline:false<p/><br/>")
re=/^x(y)+(\d+)$/g;//注意pattern,加了^和$
showRegularObjInfo(re);
document.write("<p style='color:blue'>global:true;multiline:true<p/><br/>")
re=/^x(y)+(\d+)$/mg;//开启multiline
showRegularObjInfo(re);
- global:true;multiline:false
- x(y)+(\d+).exec(str):xyyy3,y,3
- str.match(x(y)+(\d+)):xy123,xyyy3,xy888
- global:false;multiline:false
- x(y)+(\d+).exec(str):xy123,y,123
- str.match(x(y)+(\d+)):xy123,y,123
- global:true;multiline:false
- ^x(y)+(\d+)$.exec(str):null
- str.match(^x(y)+(\d+)$):null
- global:true;multiline:true
- ^x(y)+(\d+)$.exec(str):null
- str.match(^x(y)+(\d+)$):xy888
对比结果match没有任何影响,exec的结果都受了影响,可以从第2、11行看出(第8行因为一直为null,没有对比意义),为什么第5行没有影响?因为re.lastIndex只有当globle=true时才会被正则表达式的exec、test方法修改(官方文档说String的match、spit、replace也会修改,但是我用firefox测试的结果是:match、spit、replace总是将lastIndex修改为0)。
子模式:
x(y)+(\d+)中的(y)和(\d+)就是子模式,它们捕获的值会存储在 $1-$9 以及 exec 和 match(只有当globle=false时)的返回数组中。如果将子模式写成 (?:y) 的形式,则该子模式不会被捕获。稍微修改上面的代码就可以测试。
(本文将会被拆分成四篇)















 1007
1007

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









