






目录
https://blog.csdn.net/whm0802_/article/details/139887539
项目背景和目的
项目背景:
传统的图像分类方法依赖于手工设计的特征提取算法,存在效率低、准确率不高等问题。深度学习通过卷积神经网络(CNN)等模型自动学习图像特征,大大提升了分类的效果和精度。近年来,随着硬件性能的提升和大数据的发展,基于深度学习的图像分类技术取得了显著进展,并在多个实际应用中表现出色,如自动驾驶、医疗影像诊断、安防监控及电子商务中的商品推荐等。
项目目的:
构建一个图像分类模型:我们的主要目的是利用深度学习技术构建一个能够准确分类衣服和裤子的模型。这种模型可以作为其他更复杂任务的基础,比如多类别服装分类或者个性化推荐系统。
学习数据预处理技术:项目将涉及从原始图像数据中提取特征并进行适当的预处理,例如调整大小、转换为灰度图像或归一化处理。这些步骤对于构建高性能的图像分类器至关重要。
理解深度学习模型的搭建和优化:我们将探索如何使用卷积神经网络(CNN)来处理图像数据,通过增加卷积层、池化层和全连接层来提高模型的准确性和泛化能力。同时,我们将学习如何选择合适的损失函数、优化器和评估指标来优化模型。
可视化和解释模型结果:除了构建模型,我们还将学习如何可视化模型的预测结果和错误分类,以便对模型的表现进行分析和改进。
数据准备
加载图像文件路径
数据来源:从网络上找的
接下来,我们使用glob库来获取图像文件的路径。
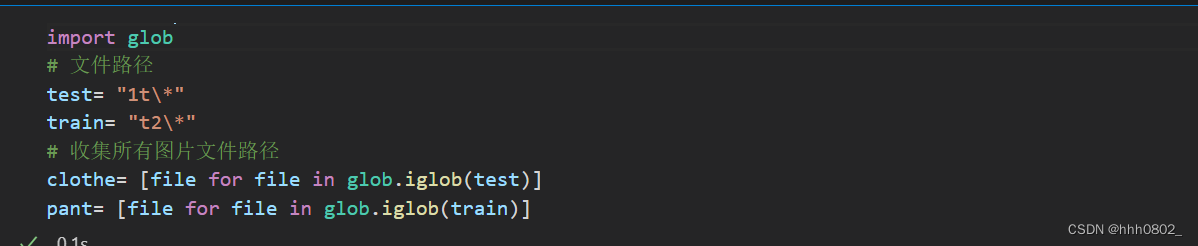
这里,我们将衣服的图片存储在目录1t中,而裤子的图片存储在目录t2中。
创建标签

np.zeros(len(clothe)) 创建了一个长度为 len(clothe) 的零数组,其中的每个元素都是 0。
np.ones(len(pant)) 创建了一个长度为 len(pant) 的全一数组,其中的每个元素都是 1。
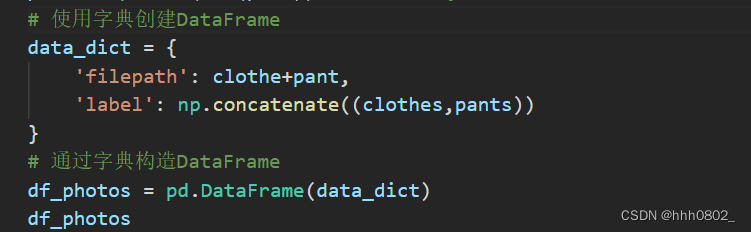
构建DataFrame
将文件路径和对应的标签存储在一个DataFrame中,以便后续处理。
数据集划分
将数据集划分为训练集和测试集。

使用 scikit-learn 库中的 train_test_split 函数将数据集 df_photos 分成训练集和测试集,其中测试集占20%。然后,对分割后的训练集和测试集重置索引。
数据预处理

.resize((128, 128)) 将图像大小调整为 128x128 像素。
.convert("L") 将图像转换为灰度图像(单通道),即将图像从彩色或RGBA模式转换为灰度模式。
/ 255.0 对图像进行归一化,将像素值缩放到 [0, 1] 的范围。
构建卷积神经网络模型
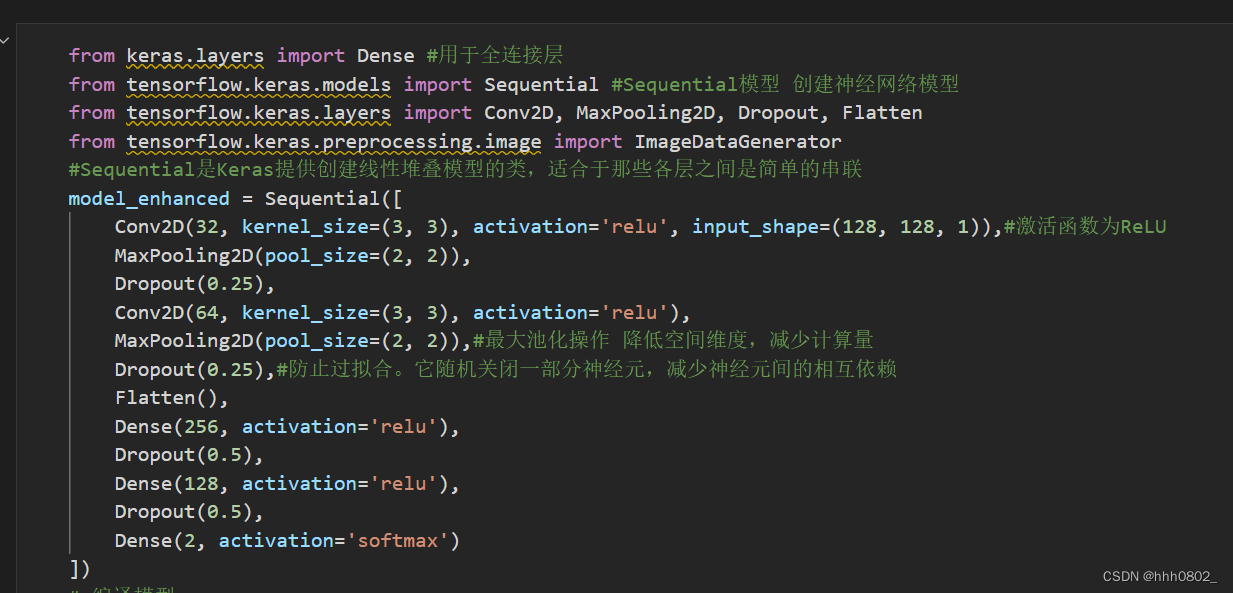
卷积层(Conv2D):提取图像特征,使用ReLU激活函数。
最大池化层(MaxPooling2D):降低空间维度和计算量。
Dropout层:防止过拟合,通过随机关闭部分神经元来减少依赖性。
Flatten层:将多维特征图展平成一维向量。
全连接层(Dense):学习特征间的关联性,使用ReLU激活函数。
输出层:使用Softmax激活函数,将结果转化为类别概率。
编译模型

Adam优化器:使用Adam优化器,并设置学习率为0.000005。
损失函数:使用稀疏类别交叉熵(SparseCategoricalCrossentropy)。这个损失函数适用于分类任务,尤其是标签为整数形式时(如0和1)。from_logits=True表示输出未经过softmax激活,需要在计算损失时自动应用softmax。
评估指标:使用准确率(accuracy)作为评估指标。
数据增强
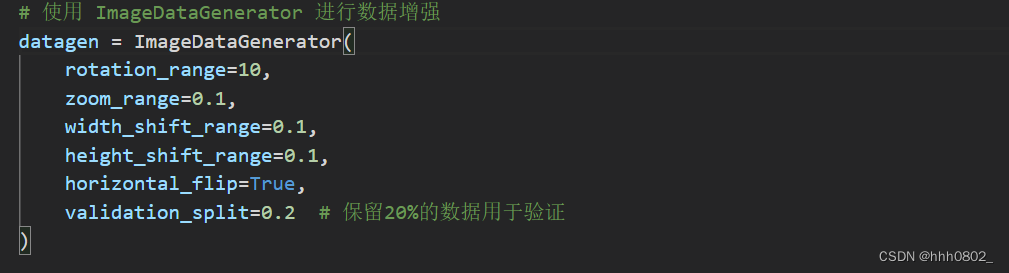
使用 ImageDataGenerator 进行数据增强,包括旋转、缩放、水平平移和垂直平移,以及水平翻转。还保留了20%的数据用于验证。
训练模型

使用提供的训练数据 train_images 和 train_labels 训练模型。
训练20个周期(epochs)。
使用20%的训练数据作为验证集,以监测模型在训练过程中的表现。
结果
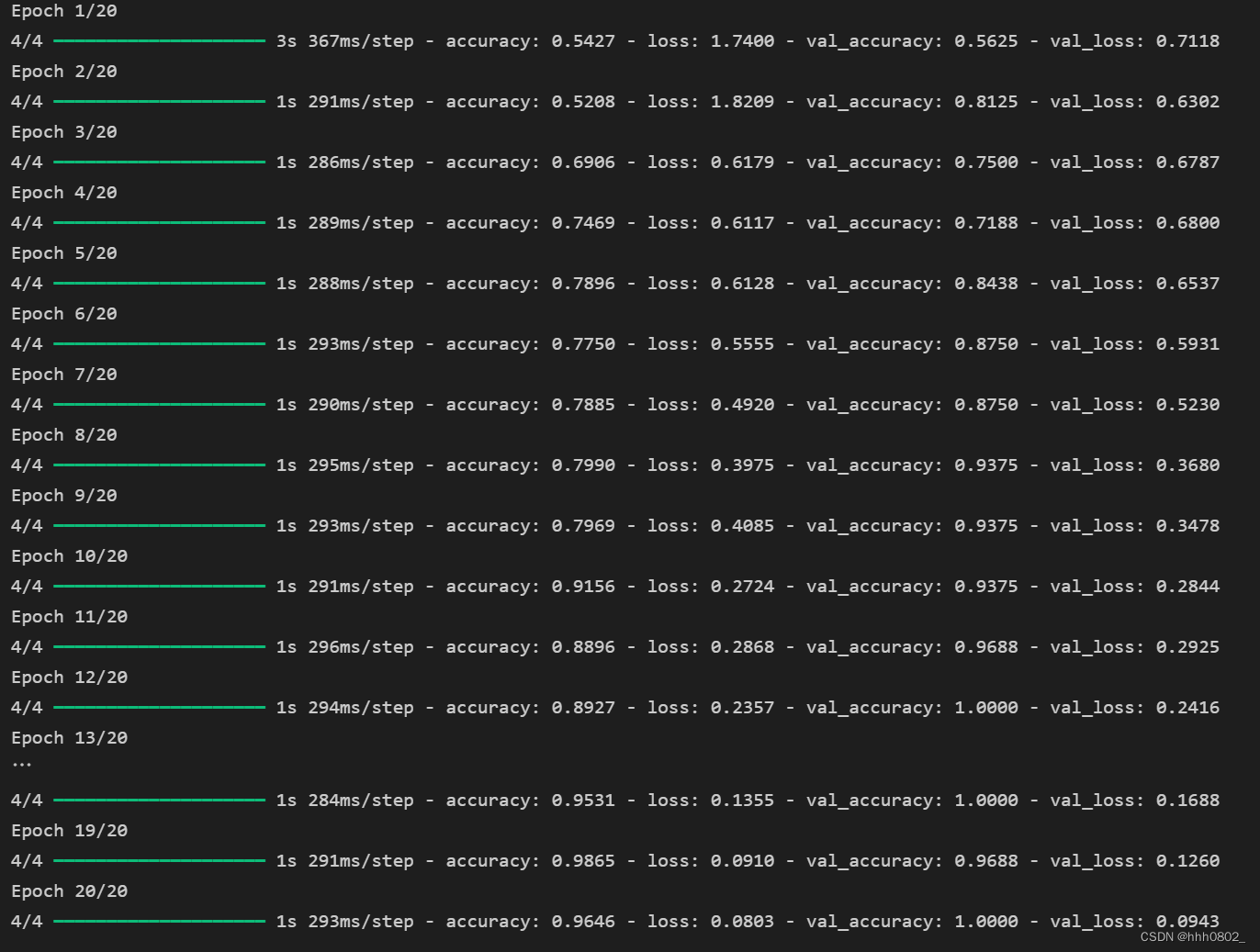
这段代码展示了模型的训练过程和结果。可以看到,随着训练的进行,模型的准确率逐渐提高,损失逐渐降低。同时,验证集上的准确率也在逐步增加,表明模型在未见过的数据上也能取得不错的表现。
结果可视化
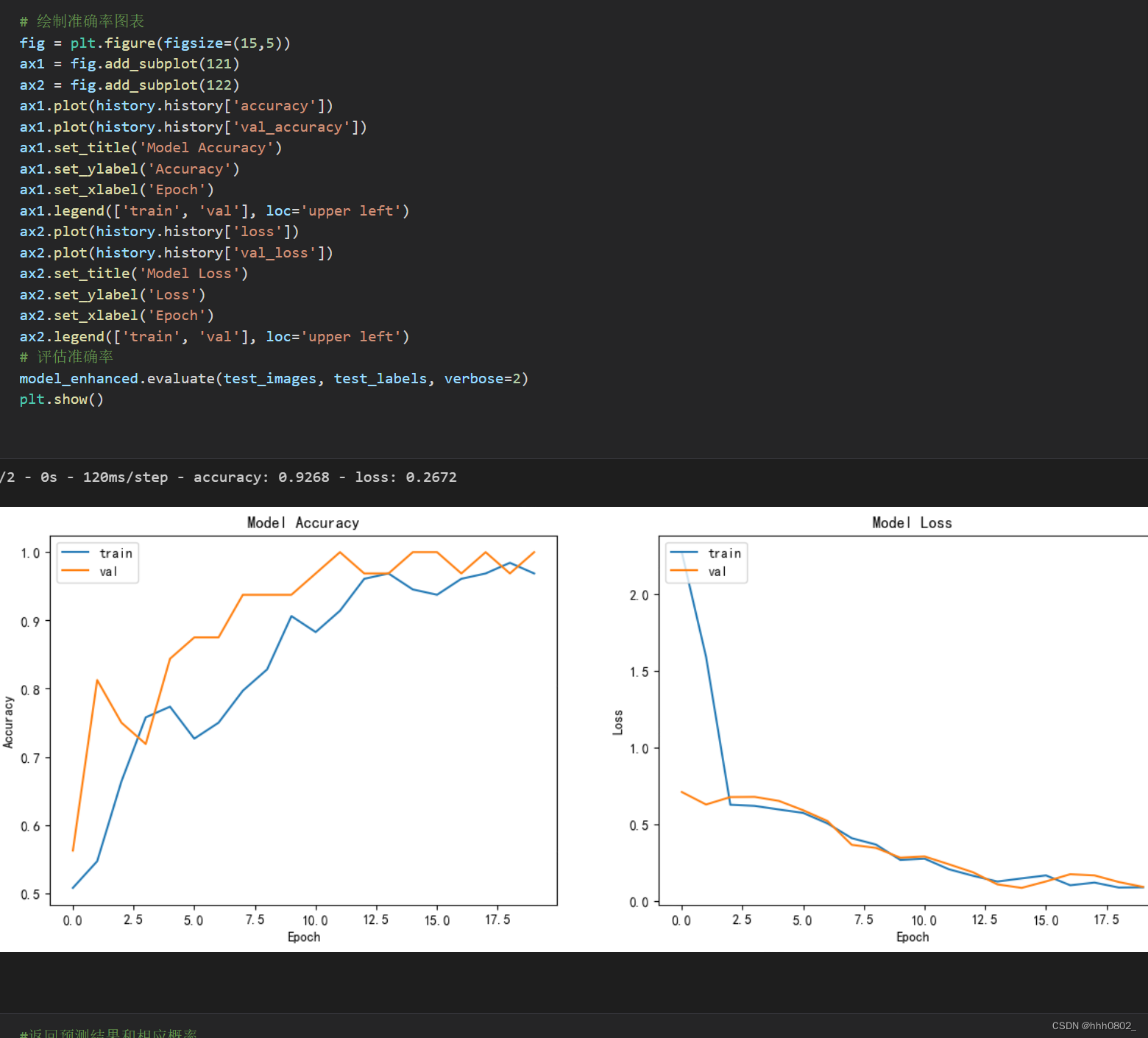
加载两张图片进行预测
保存预测结果
创建两个文件夹 predicted_clothes 和 predicted_pants 用于存放预测结果
Flask框架
代码如下:
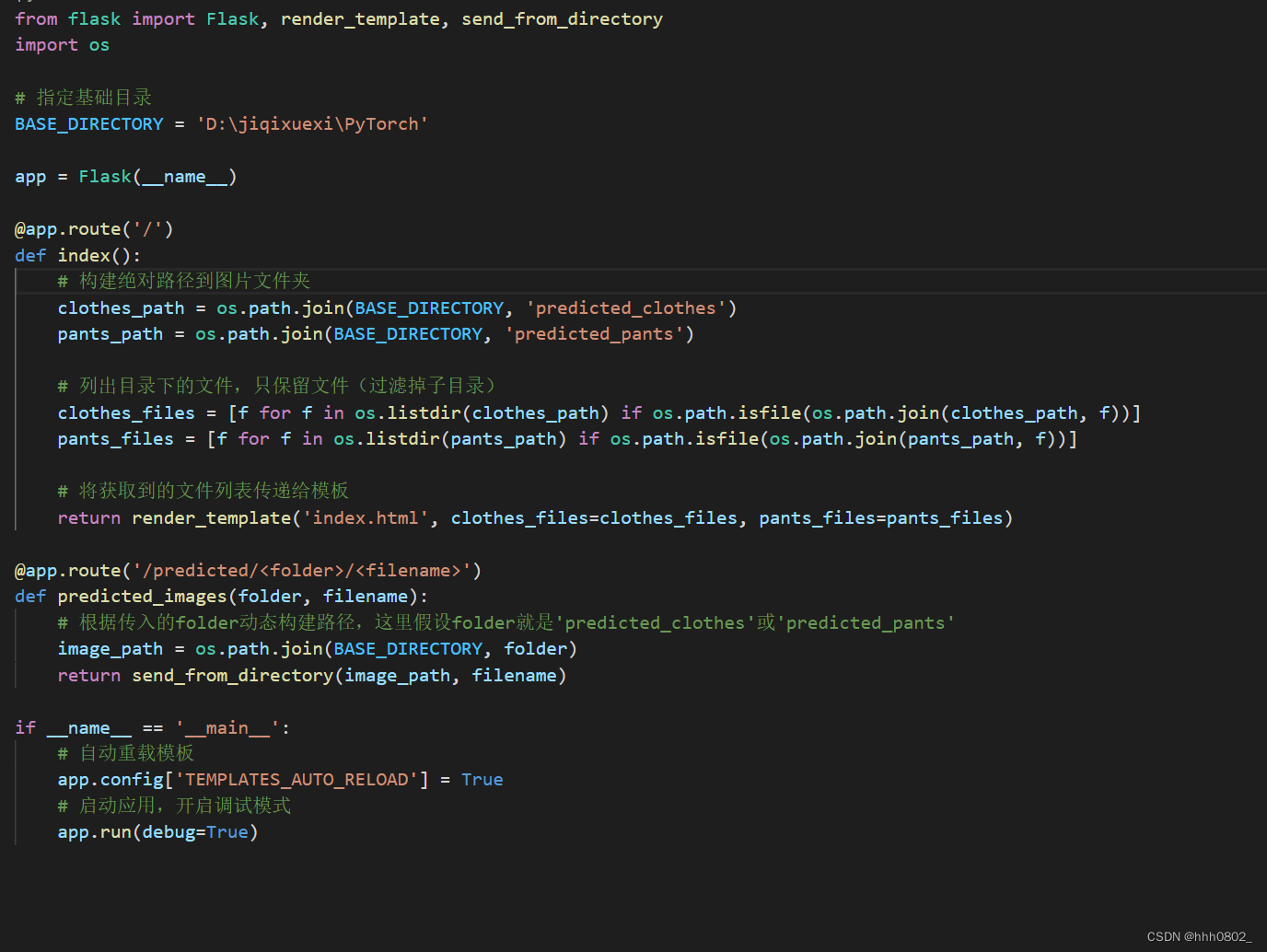 选择这个框架的原因
选择这个框架的原因
简单和轻量级:
Flask 是一个轻量级的框架,核心功能简洁而明确,没有过多的复杂性。它的设计哲学是简单易用,不会给开发者带来额外的负担。相比其他框架,Flask 的学习曲线较为平缓,容易上手。
灵活和可扩展:
Flask 提供了丰富的扩展机制,可以根据项目需求选择适合的扩展库。这些扩展库可以实现各种功能,如数据库集成、表单处理、用户认证等。你可以按需引入扩展,避免框架本身过于臃肿。
RESTful API 的优秀支持:
Flask 自然地支持构建 RESTful API,提供了方便的路由和请求处理机制,使开发者能够轻松定义和管理 API 端点。
适用于小型到中型项目:
如果你正在开发一个小型到中型的 Web 应用,Flask 是一个非常合适的选择。它提供了构建 Web 应用所需的基本功能,并且在代码组织和结构上非常自由,使你能够快速开发出高效、精简的应用程序。
对比其他框架
灵活性: Flask 的设计非常灵活,允许开发者根据项目需求选择适合的库和工具,自由度较高。
轻量级: Flask 的核心功能相对较少,但通过扩展可以轻松添加需要的功能,使得应用程序能够保持轻量级同时具备必要的扩展性。
简单易用: Flask 的设计简洁,学习曲线较平缓,对新手非常友好,使得快速上手成为可能。
HTML
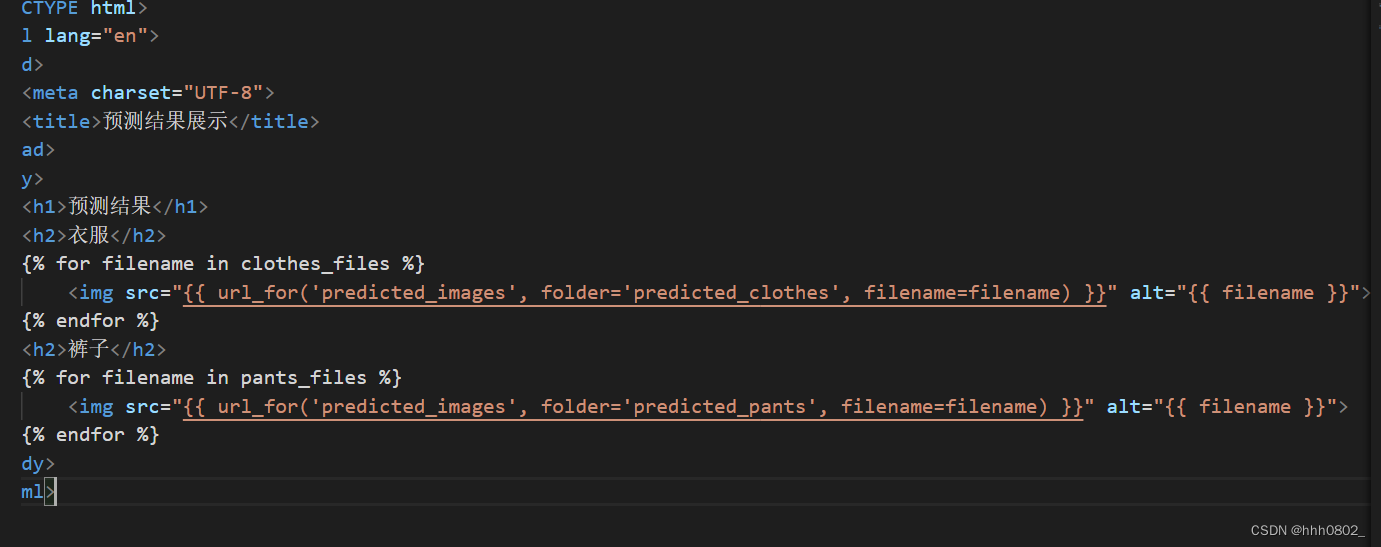
将从后端传递过来的数据呈现出来,呈现结果:

总结
导入必要的库和模块:
glob: 用于获取文件路径列表。
numpy 和 pandas: 用于数据处理和数组操作。
PIL.Image: 用于图像处理。
warnings: 用于忽略警告信息。
其他导入了深度学习相关的模块tensorflow.keras.layers、tensorflow.keras.models和tensorflow.keras.optimizers。
数据准备:
使用 glob 模块获取满足特定模式的文件路径,分别对应于衣服和裤子的图像文件。
创建包含文件路径和标签的数据字典,然后转换为pandas.DataFrame对象 df_photos。
数据预处理和加载:
定义了 process_image 函数,用于将图像加载、调整大小(128x128像素)、转换为灰度图像,并进行归一化处理。
使用 train_test_split 函数将数据集分为训练集和测试集,并进行了索引重置以确保顺序性。
模型构建:
构建了两个模型:
model_enhanced:包含卷积层、池化层、Dropout层以及全连接层的卷积神经网络模型。
使用Adam优化器,SparseCategoricalCrossentropy损失函数,并设置了准确率作为评估指标。
模型训练和评估:
对两个模型分别进行了训练,使用了 history 对象保存了训练过程中的准确率和损失值,以便后续绘图和分析。
使用 model.evaluate 方法评估了模型在测试集上的准确率。
结果可视化:
使用 matplotlib 绘制了训练过程中的准确率和损失变化曲线。
展示了一些训练集图像的示例,并标记了真实的标签(衣服或裤子)。
flask框架:
目录文件读取:读取特定目录下的文件列表。
模板渲染:通过传递文件列表数据给前端模板,展示图片文件。
动态路由:支持动态路径,处理不同目录下的文件请求。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









