







在编译原理中,把源代码翻译成机器指令,一般要经过以下几个重要步骤:
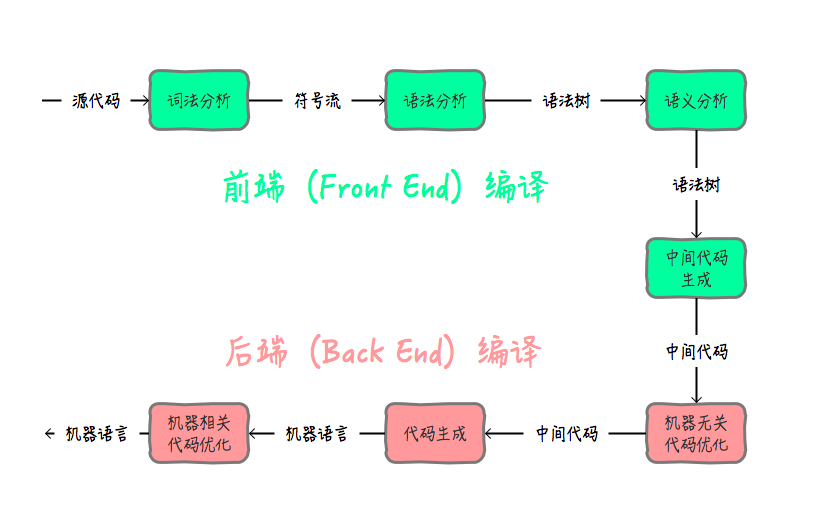
根据完成任务不同,可以将编译器的组成部分划分为前端(Front End)与后端(Back End)。对应在java 的体系中,就是我们可以把将.java文件编译成.class的编译过程称之为前端编译。把将.class文件翻译成机器指令的编译过程称之为后端编译。
前端编译
这个前端编译,老实说我这个非科班有点弄不懂,大概就是语法树的生成,将源码变成中间代码(在Java中,javac执行的结果就是得到一个字节码,而这个字节码其实就是一种中间代码。)
PS:著名的解语法糖操作,也是在javac中完成的。比如说泛型啊,switch支持string等语法题
后端编译
通常通过 javac 将程序源代码编译,转换成 java 字节码,JVM 通过解释字节码将其翻译成对应的机器指令,逐条读入,逐条解释翻译。很显然,经过解释执行,其执行速度必然会比可执行的二进制字节码程序慢很多。这就是传统的JVM的解释器(Interpreter)的功能。为了解决这种效率问题,引入了 JIT 技术。
JIT技术的思想:部分“热点代码”翻译成本地机器相关的机器码,并进行优化,然后再把翻译后的机器码缓存起来,以备下次使用。
所以是一种空间换时间的操作
HotSpot虚拟机中内置了两个JIT编译器:Client Complier和Server Complier,分别用在客户端和服务端,目前主流的HotSpot虚拟机中默认是采用解释器与其中一个编译器直接配合的方式工作(一种混合模式mixed-mode)
C:\Users\Think>java -version
java version "1.8.0_91"
Java(TM) SE Runtime Environment (build 1.8.0_91-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.91-b14, mixed mode)
个人认为:一般一开始解释器其主要作用,随着应用运行时间变长,编译器确定了热点代码,编译器开始慢慢发挥作用
JIT检查热点代码的方式:
基于采样的方式探测(Sample Based Hot Spot Detection) :周期性检测各个线程的栈顶,发现某个方法经常出险在栈顶,就认为是热点方法,好处就是简单,缺点就是无法精确确认一个方法的热度。容易受线程阻塞或别的原因干扰热点探测
基于计数器的热点探测(Counter Based Hot Spot Detection)。采用这种方法的虚拟机会为每个方法,甚至是代码块建立计数器,统计方法的执行次数,某个方法超过阀值就认为是热点方法,触发JIT编译。
在HotSpot虚拟机中使用的是第二种——基于计数器的热点探测方法,因此它为每个方法准备了两个计数器:方法调用计数器和回边计数器。
方法计数器。顾名思义,就是记录一个方法被调用次数的计数器。
回边计数器。是记录方法中的for或者while的运行次数的计数器。
java编译和反编译的工具
- Java语言中的编译一般指将java文件转换成class文件。
- Java语言中的反编译一般指将class文件转换成java文件
java反编译工具
- javap:把class反编译为字节码,字节码虽然不是java代码,但是可以帮助我们看到很多底层的东西
- jad :反编译为java代码,但是很久没更新
- cfr:比较不错,就算操作参数比较多
最后说一下eclipse中怎么使用javap 命令
- 点击Run —> External tools —> External tools Configurations
-第二步在program上双击 ,就会出现如图

需要注意的是这个Arguments 是针对maven项目的
,针对普通项目Arguments :
-classpath bin -c ${java_type_name}
使用的时候,在package explorer中选中文件,在点击Run —> External tools —>javap即可(一定先选中文件,否则报错)
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









