







本文是读书笔记。个人比较浅显的理解,其中有一些专业词汇也是个人自己的翻译,如果有不对的希望大家指正。
来自论文《An overview of text-independent speaker recognition: From features to supervectors》的第四章节
===========================分界线================================
这篇博客主要讲解文本无关的说话人识别的常用模型。
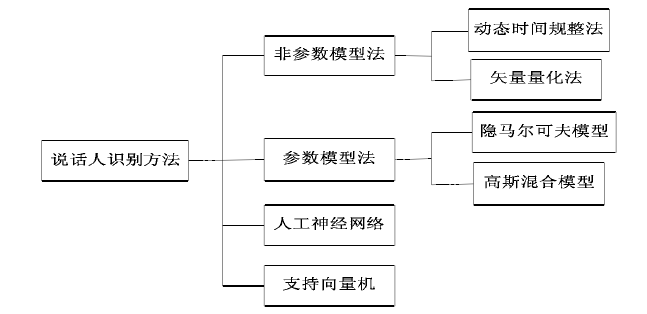
典型的说话人模型可以分为两种:template model和 stochastic model,即模板模型和随机模型。也称作非参数模型和参数模型。
模板模型(非参数模型)将训练特征参数和测试的特征参数进行比较,两者之间的失真(distortion)作为相似度。例如
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2482
2482











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









