







很多网站或应用会提供各样的排行榜,如热门查询、热门应用、最佳文章、论坛评论/文章列表展示等。前段时间做游戏的搜索热词就看了几篇文章,总结记录下。先介绍下流传比较广的算法,再说下我的算法。
Hacker News热门新闻
Hacker News是一个新闻聚合网站,用户可以submit/up vote新闻,网站需要根据新闻的质量、提交时间排序,以期望把新鲜热门文章找出来。
- v 是文章获得up vote数,减一的目的是去除提交者自己的vote
- t是文章已存在已经发布的时间,当前时间-submit时间
- G是一个调节参数,用于调节时间的比重
该算法受时间影响很大,随着时间流逝,score会骤然下降。G越大,下降越快。如下图:
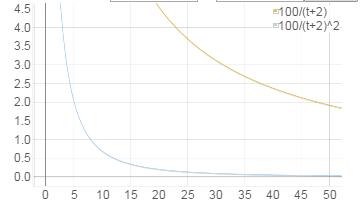
Reddit最新受欢迎新闻
Reddit也是一个类似的社交新闻网站,用户可以submit、up vote、down vote新闻。看下它的热门文章是如何算出来的。
-
ts=A−B
A:文章提交的时间;B是一个固定时间,2005/12/8:07:46:43 - x=U−D , U: up votes; D: down votes
- y=⎧⎩⎨10−1if x > 0ifx==0ifx<0
- z=min(|x|,1)
score
的第二个加数部分是个常量,
ts
在新闻提交的时候就确定了,45000是12.5小时的秒数。
score
的主体是第一个加数
log
函数,
log
使早期投票更有影响。
log1010=1
,
log10100=2
,10以后的90个投票才使
score+1
。下图也反映了越往后
score
越平缓。
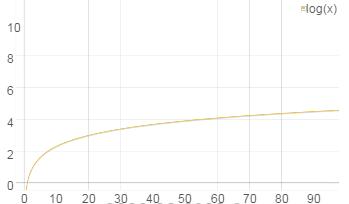
2015/11/04:20:00:00新增的新闻截止到2015/11/05:20:00:00,经过一天获得5000个up vote,算下得分:
那么今天2015/11/05:20:00:00新增的新闻获得100个vote,得分:
可以看出时间对 score 的影响很大,1天的时间就抵掉了5000个vote,很大的稀释了vote的影响。随着时间流逝vote影响迅速减小,保证了最新的新闻会出现在排行榜前面。反对票多的新闻,也会被打压下去,基本没有出来的机会。
Reddit评论
在某文章下,显示出最好的评论。评论是不需要考虑时间,只考虑up vote/down vote。Reddit采用了Wilson Score Confidence Interval算法。
- n是总采样数,up + down;
- p^ 是支持率, up/n;
- z 是置信水平对应的标准正态分布的分位数,可以查正态分布表获得,如0.95置信水平对应的z-score是1.65。
该算法考虑了支持率和数据采样规模,相当于在一个置信水平和采用规模下,找支持率
A:up=1,down=0,z=1.65:score=11+1.652=0.2686B:up=10,down=1,z=1.65:score=0.64C:up=40,down=20,z=1.65:score=0.53
如上排名顺序为B、C、A。A场景虽然支持率是100%,但是投票数太少,排到了最后。B虽然只有10个支持票,但推断下当获得40个支持票时,反对票可能是4个,少于C的20个反对票。所以B优于C。
游戏搜索热词
搜索词没有vote数,也很难获得第一次出现的时间。可以考虑的有单位时间内出现的次数、变化趋势。时间单位设为天,搜索词次数是在下载日志中,输入该搜索词的唯一用户数。
- c1 : 昨天的下载日志中,搜该词的唯一用户数,一天内一个用户最多输入该词一次
- c2 : 同${c_1},但来自于前天的下载日志
- s : 昨天下载日志中,唯一用户总数
- N: 固定域值,如超过100才能进入热门词候选
α : 固定值,用于调节绝对值和变化趋势间的比重
该算法使用下载日志,避免出现无搜索结果的情况;出现次数采用唯一用户数,避免单用户多刷情况;加数第一部分考虑的是绝对值,加数第二部分考虑的是变化趋势; log10c1 稀释绝对数,除以 log10s 是为了归一化;算法突出了变化趋势。
参考
http://www.evanmiller.org/how-not-to-sort-by-average-rating.html
https://moz.com/blog/reddit-stumbleupon-delicious-and-hacker-news-algorithms-exposed
http://www.redditblog.com/2009/10/reddits-new-comment-sorting-system.html

















 3174
3174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









