







一、数据库系统基础
-
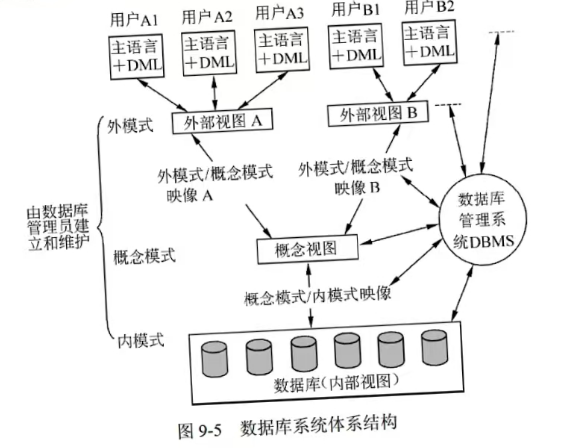
数据库系统三级模式结构
-
模式(基本表):也称概念模式,全局逻辑结构,描述数据的整体逻辑。
-
外模式(视图):用户视图,描述局部逻辑。
-
内模式(存储文件):物理存储结构,如索引、存储方式。
-
两级映像:外模式-模式映像(逻辑独立性)、模式-内模式映像(物理独立性)。
-
-
数据模型
模型是对现实世界的模拟和抽象,在数据库技术中,表示实体类型及实体类型间联系的模型称为数据模型。
1.数据模型的组成元素
数据模型是描述数据、数据关系及数据约束的抽象框架,通常包含以下核心组成部分:
1. 数据结构(Data Structure)
-
定义:描述数据的逻辑组织形式及数据间的静态关系。
-
示例:在关系模型中,数据结构表现为二维表(关系模式)。
2. 数据操作(Data Manipulation)
-
定义:对数据执行的操作(增删改查)及操作规则。
-
示例:关系模型通过关系代数(选择、投影、连接)定义操作。
3. 数据约束(Data Constraints)
-
定义:保证数据正确性、有效性和一致性的规则。
-
示例:在关系模型中,通过
PRIMARY KEY、FOREIGN KEY实现约束。
2.数据模型的分类
1. 概念数据模型(Conceptual Data Model)
- 实体:客观存在且可相互区别的事物,如单位、职工、部门等。
- 属性:描述实体的特性。一个实体可由多个属性刻画(如学生实体的学号、姓名、性别等)。属性的具体取值为属性值。
- 码:唯一标识实体的属性集(如学号是学生实体的码)。
- 域:属性的取值范围(如性别域为 {男,女})。
- 实体型:用实体名及其属性名集合抽象刻画同类实体(如学生(学号,姓名,性别,班号))。
- 实体集:同型实体的集合(如全体学生)。
- 联系:实体(型)之间的对应关系,包括实体内部各属性间的联系和实体之间的联系。
2.结构数据模型
| 模型类型 | 数据结构 | 查询灵活性 | 适用场景 | 典型系统 |
|---|---|---|---|---|
| 关系模型 | 二维表 | 高(SQL支持) | 复杂事务处理、结构化数据 | MySQL, Oracle |
| 层次模型 | 树形结构 | 低(路径固定) | 树形数据(如目录) | IBM IMS, XML |
| 网状模型 | 图结构 | 中(指针导航) | 复杂网络关系 | CODASYL |
| 面向对象模型 | 对象 | 中(方法调用) | 复杂数据类型、OOP映射 | MongoDB(部分特性) |
1. 关系模型(Relational Model)
-
数据结构:二维表(关系),由行(记录)和列(属性)组成
| 术语 | 定义 | 示例 | 关键点 |
|---|---|---|---|
| 关系(Relation) | 二维表,由行(元组)和列(属性)组成。 | 学生(学号, 姓名, 年龄) | 表名唯一,行无序,列有序。 |
| 属性(Attribute) | 表中的列,表示实体的特征。 | 学号、姓名、年龄 | 属性名唯一,具有数据类型(如整数、字符串)。 |
| 元组(Tuple) | 表中的一行数据,表示一个具体实例。 | (001, 张三, 20) | 所有元组的属性个数和类型一致。 |
| 域(Domain) | 属性的取值范围(数据类型+约束)。 | 年龄域为1~150的整数。 | 保证数据有效性(如年龄不能为负数)。 |
| 候选键(Candidate Key) | 唯一标识元组的最小属性集合。 | 学号或身份证号可唯一标识学生。 | 最小性、唯一性;一个表可有多个候选键。 |
| 主键(Primary Key) | 从候选键中选定的唯一标识符。 | 选定学号作为主键。 | 非空且唯一,用于关联其他表。 |
| 外键(Foreign Key) | 本表中的属性,引用其他表的主键。 | 选课表.学号引用学生表.学号。 | 维护参照完整性(如外键值必须存在或为NULL)。 |
| 超键(Super Key) | 能唯一标识元组的属性集合(可能含冗余属性)。 | (学号, 姓名)可唯一标识学生。 | 非最小性,候选键是极小的超键。 |
| 全码(All-Key) | 所有属性联合才能唯一标识元组(即整个属性集为候选键)。 | (课程号, 教师, 时间)唯一标识课程安排。 | 无单一属性能唯一标识元组,需联合全部属性。 |
| 关系模式(Relation Schema) | 关系的逻辑结构描述,包括属性、域及约束。 | 学生(学号:CHAR(6), 姓名:VARCHAR(20)) | 定义表的“蓝图”,不包含具体数据。 |
- 完整性约束
1. 实体完整性(Entity Integrity)
-
定义:主键(Primary Key)的值必须唯一且非空。
-
作用:保证每个实体的唯一可标识性。
2. 参照完整性(Referential Integrity)
-
定义:外键(Foreign Key)的值必须是被引用表主键的有效值或为
NULL。 -
作用:维护表间关联的正确性。
3. 用户定义完整性(User-Defined Integrity)
定义:用户根据业务需求自定义的约束(如取值范围、逻辑规则)。
- 连接
| 连接类型 | 定义 | SQL语法 |
|---|---|---|
| 自然连接(Natural Join) | 自动匹配同名属性,消除重复列。 | SELECT * FROM R NATURAL JOIN S |
| θ连接(Theta Join) | 根据条件θ连接(如R.A > S.B)。 | SELECT * FROM R JOIN S ON R.A = S.B |
| 等值连接(Equi-Join) | θ连接的特例,条件为相等比较(如R.A = S.A)。 | SELECT * FROM R JOIN S ON R.A = S.A |
| 外连接(Outer Join) | 保留未匹配的元组,分为左外、右外、全外连接。 | SELECT * FROM R LEFT JOIN S ON R.A = S.A |
操作示例:
-
数据表:
-
R(A, B):(1, 2), (3, 4) -
S(B, C):(2, 5), (6, 7)
-
| 操作 | 结果 |
|---|---|
| 自然连接 R ⋈ S | (A, B, C) = (1, 2, 5) |
| 左外连接 R ⟕ S | (1,2,5), (3,4,NULL) |
| 全外连接 R ⟗ S | (1,2,5), (3,4,NULL), (NULL,6,7) |
- 基本关系操作
Codd定义的五种基本操作,其他操作均可由这些操作组合派生。
| 操作名称 | 符号 | 定义 | 示例 | SQL对应 |
|---|---|---|---|---|
| 选择(Select) | σₚ(R) | 从关系R中筛选满足条件P的元组。 | σ_{年龄>20}(学生) → 筛选年龄大于20的学生。 | SELECT * FROM 学生 WHERE 年龄>20 |
| 投影(Project) | πₐ(R) | 从关系R中提取指定属性集A的列,并去重。 | π_{姓名,年龄}(学生) → 仅显示姓名和年龄。 | SELECT 姓名, 年龄 FROM 学生 |
| 并(Union) | R ∪ S | 合并R和S的元组,自动去重(要求R和S属性相同)。 | 学生 ∪ 教师 → 合并学生和教师表中的人员。 | SELECT * FROM 学生 UNION SELECT * FROM 教师 |
| 差(Difference) | R − S | 返回属于R但不属于S的元组(要求R和S属性相同)。 | 学生 − 选课学生 → 找出未选课的学生。 | SELECT * FROM 学生 EXCEPT SELECT * FROM 选课学生 |
| 笛卡尔积(Cartesian Product) | R × S | R和S的元组两两组合,生成新关系。 | 学生 × 课程 → 每位学生与所有课程的组合。 | SELECT * FROM 学生 CROSS JOIN 课程 |
- 扩展关系操作(Derived Operations)
由基本操作组合而成的常用操作。
| 操作名称 | 符号 | 定义 | 示例 | SQL对应 |
|---|---|---|---|---|
| 交(Intersection) | R ∩ S | 返回同时属于R和S的元组(要求R和S属性相同)。 | 男生 ∩ 团员 → 既是男生又是团员的学生。 | SELECT * FROM 男生 INTERSECT SELECT * FROM 团员 |
| 除(Division) | R ÷ S | 返回R中满足“与S所有元组组合均存在”的元组。 | 选课(学号,课程号) ÷ 课程(课程号) → 选修了所有课程的学生。 | 需通过NOT EXISTS嵌套查询实现。 |
| 重命名(Rename) | ρₐ(R) | 将关系R重命名为A,或修改属性名。 | ρ_{员工(工号,姓名)}(原表) → 将原表重命名为“员工”,属性名改为工号、姓名。 | SELECT 工号 AS 员工编号 FROM 员工 |
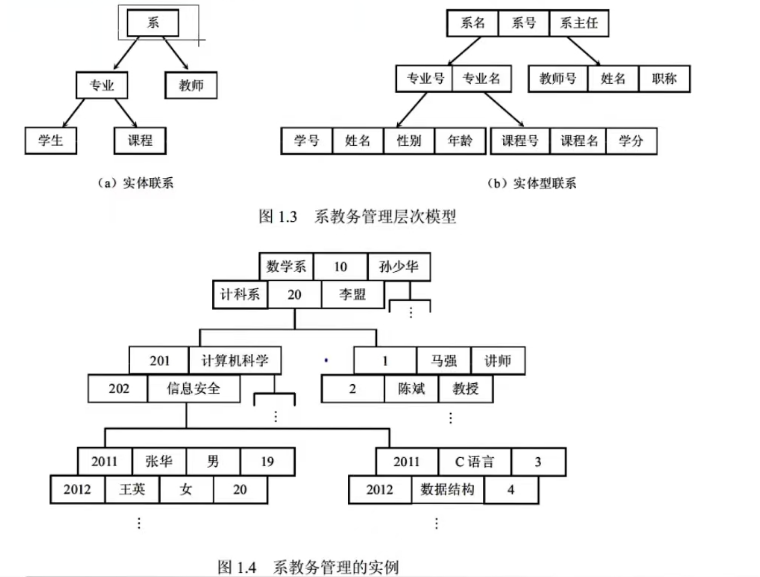
2. 层次模型(Hierarchical Model)
层次模型是用“树结构”来表示数据之间的联系,是数据库系统最早使用的一种模型,它的数据结构是一棵“有向树”。层次模型的特征是:
- 有且仅有一个结点没有父结点,它就是根结点:
- 其他结点有且仅有一个父结点。
层次模型常见的存储结构有邻接法和链接法。采用层次模型的数据库管理系统有IMS(Information Management System)系统。
3. 网状模型(Network Model)
-
数据结构:图结构,允许记录多对多关系,通过“系(Set)”连接
-
数据操作:
-
通过指针链实现快速导航。
-
支持复杂关系,但操作繁琐。
-
-
应用场景:早期复杂网络关系系统(如电信网络)。
-
示例:CODASYL数据库。
4. 面向对象模型(Object-Oriented Model)
-
数据结构:对象(类实例),包含属性(数据)和方法(操作)。
-
继承:类层次结构(如
Employee→Manager)。 -
聚合:对象嵌套(如
Order包含多个OrderItem)。
-
-
数据操作:
-
通过对象方法(如
save(),delete())操作数据。 -
支持复杂数据类型(数组、列表)。
-
-
应用场景:CAD/CAM系统、多媒体数据库。
-
示例:MongoDB(文档型数据库,部分支持面向对象)。
二、SQL语言
1. 数据定义语言(DDL)
用于定义数据库对象(表、视图、索引等)。
| 命令 | 功能 | 示例 |
|---|---|---|
| CREATE | 创建数据库对象 | CREATE TABLE 学生 (学号 INT PRIMARY KEY, 姓名 VARCHAR(20)); |
| ALTER | 修改数据库对象结构 | ALTER TABLE 学生 ADD 年龄 INT; |
| DROP | 删除数据库对象 | DROP TABLE 学生; |
| TRUNCATE | 清空表数据(保留结构) | TRUNCATE TABLE 学生; |
2. 数据操作语言(DML)
用于操作表中的数据(增删改)。
| 命令 | 功能 | 示例 |
|---|---|---|
| INSERT | 插入数据 | INSERT INTO 学生 VALUES (1, '张三', 20); |
| UPDATE | 更新数据 | UPDATE 学生 SET 年龄=21 WHERE 学号=1; |
| DELETE | 删除数据 | DELETE FROM 学生 WHERE 学号=1; |
3. 数据控制语言(DCL)
用于权限管理与事务控制。
| 命令 | 功能 | 示例 |
|---|---|---|
| GRANT | 授予用户权限 | GRANT SELECT ON 学生 TO user1; |
| REVOKE | 撤销用户权限 | REVOKE DELETE ON 学生 FROM user1; |
| COMMIT | 提交事务 | COMMIT; |
| ROLLBACK | 回滚事务 | ROLLBACK; |
4. 数据查询语言(DQL)
用于查询数据(以 SELECT 为核心)。
SELECT [DISTINCT] 列名1, 列名2, ...
FROM 表名
[WHERE 条件]
[GROUP BY 分组列]
[HAVING 分组后条件]
[ORDER BY 排序列 [ASC|DESC]] //ASC升序排列,DESC降序排列
[LIMIT 行数]; 5.多表连接
| 连接类型 | 语法 | 说明 |
|---|---|---|
| INNER JOIN | SELECT * FROM A INNER JOIN B ON A.k=B.k | 返回匹配的记录 |
| LEFT JOIN | SELECT * FROM A LEFT JOIN B ON A.k=B.k | 保留左表全部记录,右表不匹配则为NULL |
| RIGHT JOIN | SELECT * FROM A RIGHT JOIN B ON A.k=B.k | 保留右表全部记录,左表不匹配则为NULL |
| FULL JOIN | SELECT * FROM A FULL JOIN B ON A.k=B.k | 保留两表所有记录 |
6. 子查询(嵌套查询)
-
标量子查询:返回单个值。
SELECT 姓名 FROM 学生 WHERE 学号 = (SELECT MAX(学号) FROM 学生); -
IN/NOT IN 子查询:返回集合。
SELECT 姓名 FROM 学生 WHERE 学号 IN (SELECT 学号 FROM 选课 WHERE 课程号='C01'); -
EXISTS/NOT EXISTS 子查询:检查存在性。
SELECT 课程名 FROM 课程 C WHERE EXISTS (SELECT * FROM 选课 WHERE 课程号=C.课程号);7. 聚合函数与分组
函数 功能 示例 COUNT 统计行数 SELECT COUNT(*) FROM 学生SUM 求和 SELECT SUM(成绩) FROM 选课AVG 平均值 SELECT AVG(年龄) FROM 学生MAX/MIN 最大值/最小值 SELECT MAX(成绩) FROM 选课
8.约束类型
| 约束 | 说明 | 示例 |
|---|---|---|
| PRIMARY KEY | 主键(唯一且非空) | 学号 INT PRIMARY KEY |
| FOREIGN KEY | 外键(引用其他表的主键) | FOREIGN KEY (课程号) REFERENCES 课程(课程号) |
| UNIQUE | 唯一约束(允许NULL) | 邮箱 VARCHAR(50) UNIQUE |
| NOT NULL | 非空约束 | 姓名 VARCHAR(20) NOT NULL |
| CHECK | 自定义条件 | 年龄 INT CHECK (年龄 >= 0) |
三、数据库设计
1.设计流程
数据库设计通常分为四个阶段,逐步细化数据模型:
| 阶段 | 目标 | 核心输出 | 工具/方法 |
|---|---|---|---|
| 需求分析 | 明确业务需求与数据范围 | 数据流图(DFD)、数据字典 | 用户访谈、文档分析 |
| 概念结构设计 | 抽象实体与关系,建立概念模型 | ER图(实体-联系图) | ER建模工具(如Lucidchart) |
| 逻辑结构设计 | 将概念模型转为逻辑数据模型 | 关系模式、范式化后的表结构 | 关系代数、范式理论 |
| 物理结构设计 | 优化存储结构与性能 | 表空间、索引、分区策略 | SQL脚本、性能测试工具 |
2.需求分析阶段
-
收集需求:与业务方沟通,明确数据范围、处理流程及约束条件。
-
输出文档:
-
数据流图(DFD):描述数据流动与处理过程(外部实体、处理、数据存储、数据流)。
-
数据字典:定义数据项的名称、类型、长度、约束等
-
3.概念结构设计(ER模型)
1. ER图要素
2. 联系类型
-
1:1(一对一):如“用户”与“身份证”。
-
1:N(一对多):如“部门”与“员工”。
-
M:N(多对多):如“学生”与“课程”,需通过关联实体(如“选课记录”)分解。
3. 设计原则
-
高内聚:实体属性紧密相关(如“订单”包含金额、时间,而非“用户地址”)。
-
低冗余:避免重复存储相同数据。
-
明确主键:每个实体必须有唯一标识符。
4.逻辑结构设计(关系模型)
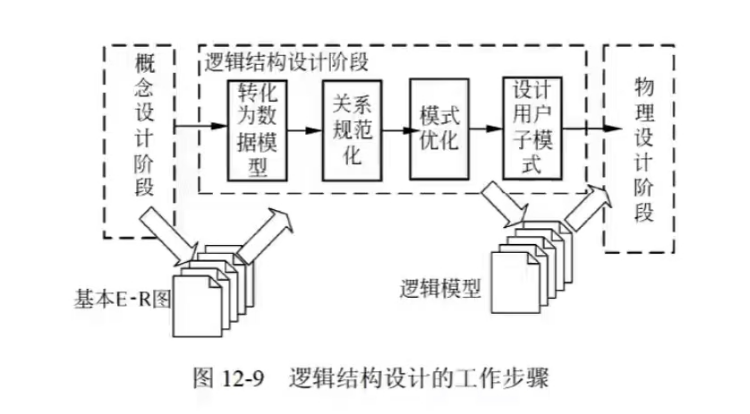
1. ER图转关系模式
-
实体转为表:
-
读者 →
读者表(读者ID, 姓名, 联系方式) -
图书 →
图书表(ISBN, 书名, 作者)
-
-
联系转为表:
-
M:N联系“借阅” →
借阅表(读者ID, ISBN, 借阅日期, 归还日期)
-
2. 范式化(Normalization)
| 范式 | 要求 | 示例问题与解决 |
|---|---|---|
| 1NF | 属性不可再分(原子性) | 将“地址”拆分为省、市、街道。 |
| 2NF | 消除非主属性对候选键的部分依赖 | 订单表拆分为“订单头”和“订单明细”。 |
| 3NF | 消除非主属性对候选键的传递依赖 | 移除“部门名称”对“员工”的传递依赖。 |
| BCNF | 消除主属性对候选键的部分/传递依赖 | 拆分“课程-教师”表,避免教师决定课程。 |
3. 反规范化(Denormalization)
-
目的:提升查询性能,适当冗余数据。
-
场景:
-
频繁JOIN操作的表(如添加“订单总金额”到订单头表)。
-
统计字段(如“用户订单数”预计算存储)。
-
5.物理结构设计
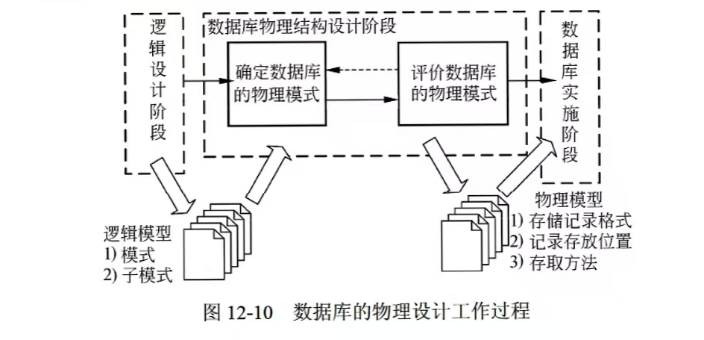
1.存储结构优化
-
索引设计:
-
B+树索引:适合范围查询(如日期范围)。
-
哈希索引:适合等值查询(如主键查找)。
-
-
分区策略:
-
水平分区:按行分片(如按时间分表)。
-
垂直分区:按列分表(如分离频繁查询字段)。
-
2. 性能调优
-
查询优化:避免全表扫描,使用覆盖索引。
-
硬件配置:合理分配表空间、日志文件存储位置。
3. 安全性设计
-
权限控制:通过角色(Role)限制用户访问权限。
-
数据加密:传输加密(SSL)、存储加密(AES)。
6.数据库的实施与维护
数据库正式投入运行之前,还需要完成很多工作。例如,在模式和子模式中加入数据库安全性、完整性的描述,完成应用程序和加载程序的设计,数据库系统的试运行,并在试运行中对系统进行评价。如果评价结果不能满足要求,还需要对数据库进行修正设计,直到满意为止。数据库正式投入使用,也并不意味着数据库设计生命周期的结束,而是数据库维护阶段的
开始。
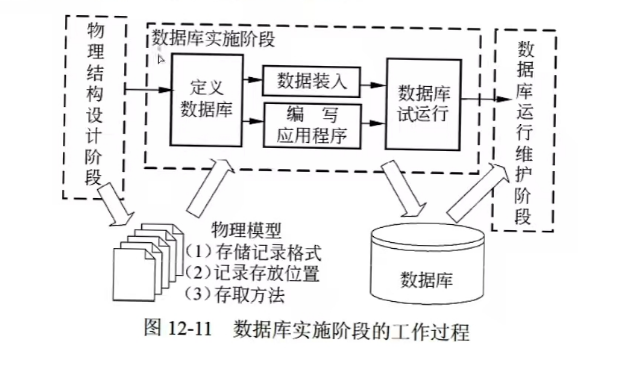
7.分布式数据库
| 术语 | 说明 |
|---|---|
| 分片透明 | 用户或应用程序无需知道逻辑上访问的表具体如何分块存储。 |
| 复制透明 | 用户无需知道数据被复制到哪些节点或如何复制。 |
| 位置透明 | 用户无需知道数据存放的物理位置。 |
| 逻辑透明 | 用户或应用程序无需知道局部场地使用的数据模型(如关系型、文档型等)。 |
| 共享性 | 数据存储在不同节点,但可被全局共享。 |
| 自治性 | 每个节点对本地数据具有独立管理能力(如独立的事务处理、权限控制)。 |
| 可用性 | 当某一场地故障时,系统可自动使用其他场地的副本,保证服务不中断。 |
| 分布性 | 数据物理上存储在不同地理位置的节点上,支持分布式存储与访问。 |
四、关系数据库规范化理论
1.规范化理论的目标
-
消除数据冗余:避免重复存储相同数据。
-
减少数据异常:
-
插入异常:无法插入部分数据(如未选课的学生无法单独存在)。
-
删除异常:删除数据时丢失必要信息(如删除最后一门课程导致教师信息丢失)。
-
更新异常:修改数据需更新多处(如修改部门名称需更新所有员工记录)。
-
2.函数依赖与键
1. 函数依赖(Functional Dependency, FD)
-
定义:若属性集X唯一确定属性集Y的值,则称 Y函数依赖于X,记作 X → Y。
-
示例:
学号 → 姓名,课程号 → 课程名。
2. 候选键(Candidate Key)
-
定义:能唯一标识关系中所有属性的最小属性集合。
-
求法:通过属性闭包(X⁺)验证是否可推导出全部属性。
3. 主键(Primary Key)
-
定义:从候选键中选择一个作为唯一标识符。
3.范式(Normal Form)详解
1. 第一范式(1NF)
-
要求:所有属性都是原子值(不可再分)。
-
示例:
原表(不满足1NF):订单号 产品信息(产品ID, 数量) 1001 (P001, 2), (P002, 1) 规范化后:
订单号 产品ID 数量 1001 P001 2 1001 P002 1
2. 第二范式(2NF)
-
要求:满足1NF,且非主属性完全依赖于候选键(消除部分依赖)。
-
示例:
原表(存在部分依赖):学号 课程号 姓名 成绩 -
候选键:
(学号, 课程号) -
问题:
姓名仅依赖学号,存在部分依赖。
规范化后:
-
学生表:
学生(学号, 姓名) -
选课表:
选课(学号, 课程号, 成绩)
-
3. 第三范式(3NF)
-
要求:满足2NF,且非主属性不传递依赖于候选键(消除传递依赖)。
-
示例:
原表(存在传递依赖):员工ID 姓名 部门ID 部门名称 -
候选键:
员工ID -
问题:
部门名称通过部门ID传递依赖于员工ID。
规范化后:
-
员工表:
员工(员工ID, 姓名, 部门ID) -
部门表:
部门(部门ID, 部门名称)
-
4. BCNF(Boyce-Codd范式)
-
要求:满足3NF,且所有非平凡函数依赖的决定因素都是候选键。
-
示例:
原表(不符合BCNF):学生 课程 教师 -
函数依赖:
教师 → 课程(教师决定课程,但教师不是候选键)。
规范化后:
-
教师课程表:
教师课程(教师, 课程) -
学生选课表:
学生选课(学生, 课程)
-
5. 第四范式(4NF)
-
要求:消除多值依赖(即属性间独立多值关系)。
-
示例:
原表(存在多值依赖):员工 技能 语言 张三 编程 中文 张三 设计 英文 -
问题:技能与语言独立多值依赖员工。
规范化后:
-
员工技能表:
员工技能(员工, 技能) -
员工语言表:
员工语言(员工, 语言)
-
4.规范化分解方法
1. 分解原则
-
无损连接性:分解后的关系通过自然连接可恢复原关系。
-
保持函数依赖:分解后的函数依赖集与原集等价。
2. 分解步骤
-
确定候选键:通过函数依赖集推导候选键。
-
分析范式级别:检查部分依赖、传递依赖等。
-
分解关系模式:按范式要求拆分表。
-
验证无损连接与依赖保持:确保分解正确性。
3. 示例:分解到3NF
-
原关系:
订单(订单号, 客户号, 客户名, 商品号, 数量) -
函数依赖:
-
订单号 → 客户号 -
客户号 → 客户名
-
-
分解:
-
订单(订单号, 客户号, 商品号, 数量) -
客户(客户号, 客户名)
-
五、事务与并发控制
-
事务特性(ACID)
-
原子性(Atomicity):事务要么全执行,要么全不执行。
-
一致性(Consistency):事务执行后数据库保持一致状态。
-
隔离性(Isolation):事务间互不干扰。
-
持久性(Durability):事务提交后结果永久保存。
-
-
并发问题
问题 描述 示例 脏读(Dirty Read) 事务A读取了事务B未提交的数据,事务B回滚导致数据不一致。 事务B修改余额未提交,事务A读取到未提交的余额(后B回滚,A读到错误数据)。 不可重复读(Non-repeatable Read) 事务A多次读取同一数据,期间事务B修改了该数据,导致A两次读取结果不同。 事务A第一次读取库存为10,事务B修改为5后提交,事务A再次读取库存为5。 幻读(Phantom Read) 事务A按条件查询数据,期间事务B插入或删除了符合条件的数据,导致A两次结果行数不同。 事务A查询年龄>20的学生有5人,事务B插入一条新记录后,事务A再查得到6人。 -
封锁协议
锁类型 描述 兼容性 共享锁(S锁) 读锁,允许多事务并发读同一资源。 与S锁兼容,与X锁不兼容。 排他锁(X锁) 写锁,事务独占资源,其他事务不可读写。 与所有锁(包括自身)不兼容。 锁协议:两阶段锁协议(2PL):
-
加锁阶段:事务可申请锁,但不能释放锁。
-
解锁阶段:事务可释放锁,但不能申请新锁。
-
作用:保证可串行化调度,但可能导致死锁。
-
-
隔离级别
| 级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| READ UNCOMMITTED | ✔ | ✔ | ✔ |
| READ COMMITTED | ✘ | ✔ | ✔ |
| REPEATABLE READ | ✘ | ✘ | ✔ |
| SERIALIZABLE | ✘ | ✘ | ✘ |
5.死锁处理
1. 死锁产生条件
-
互斥:资源只能被一个事务独占。
-
占有且等待:事务持有资源并等待其他资源。
-
不可抢占:资源只能由持有者释放。
-
循环等待:事务间形成环形等待链。
2. 死锁解决方案
-
预防:
-
一次封锁法:事务一次性申请所有所需资源。
-
顺序封锁法:按固定顺序申请资源。
-
-
检测与恢复:
-
超时机制:事务等待超时后回滚。
-
等待图检测:定期检测等待环路,选择牺牲者回滚。
-
六、数据库安全与恢复
-
安全性
-
用户权限管理:角色(Role)与授权(GRANT/REVOKE)。
-
加密技术:传输加密(SSL)、存储加密(AES)。
-
-
故障类型与恢复策略
故障类型 恢复策略 工具/技术 事务故障 单个事务执行错误(如死锁、超时) 回滚事务(UNDO日志)。 系统故障 数据库崩溃(如断电、软件错误) 重做已提交事务(REDO日志)。 介质故障 存储设备损坏(如磁盘故障) 从备份恢复,结合日志重做。
3.备份与恢复技术
| 备份类型 | 说明 | 优缺点 |
|---|---|---|
| 完全备份 | 备份整个数据库 | 恢复快,但占用存储大,耗时。 |
| 增量备份 | 仅备份自上次备份后的变化数据 | 存储小,但恢复需逐级合并增量。 |
| 差异备份 | 备份自上次完全备份后的变化数据 | 恢复速度介于完全与增量之间。 |
4.日志与检查点
-
日志文件(Log File):
-
UNDO日志:记录事务修改前的数据,用于回滚。
-
REDO日志:记录事务修改后的数据,用于重做。
-
-
检查点(Checkpoint):
-
定期将内存中的脏页(Dirty Page)写入磁盘,缩短恢复时间。
-
示例:MySQL的
innodb_fast_shutdown参数控制检查点行为。
-
5.高可用与容灾技术
| 技术 | 原理 | 应用场景 |
|---|---|---|
| 主从复制 | 主库同步数据到从库,从库提供读服务。 | 读写分离,负载均衡。 |
| 双机热备 | 主备服务器实时同步,故障时自动切换。 | 金融、医疗等高可用需求系统。 |
| 分布式数据库 | 数据分片存储,多副本容灾。 | 海量数据、高并发场景(如电商大促)。 |
七、数据库优化
-
查询优化
-
执行计划分析:通过EXPLAIN查看SQL执行路径。
-
索引优化:B+树索引、哈希索引的适用场景。
-
-
表结构优化
-
反规范化:适当冗余减少连接操作。
-
垂直/水平分表:拆分大表提升性能。
-
八、新技术与扩展
-
NoSQL数据库
-
类型:键值存储(Redis)、文档型(MongoDB)、列存储(HBase)、图数据库(Neo4j)。
-
CAP理论:一致性(Consistency)、可用性(Availability)、分区容错性(Partition Tolerance)。
-
-
大数据与分布式数据库
-
Hadoop生态系统:HDFS、MapReduce。
-
NewSQL:TiDB、Spanner,兼顾关系模型与分布式扩展。
-


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









