









1、 首先给出表结构:
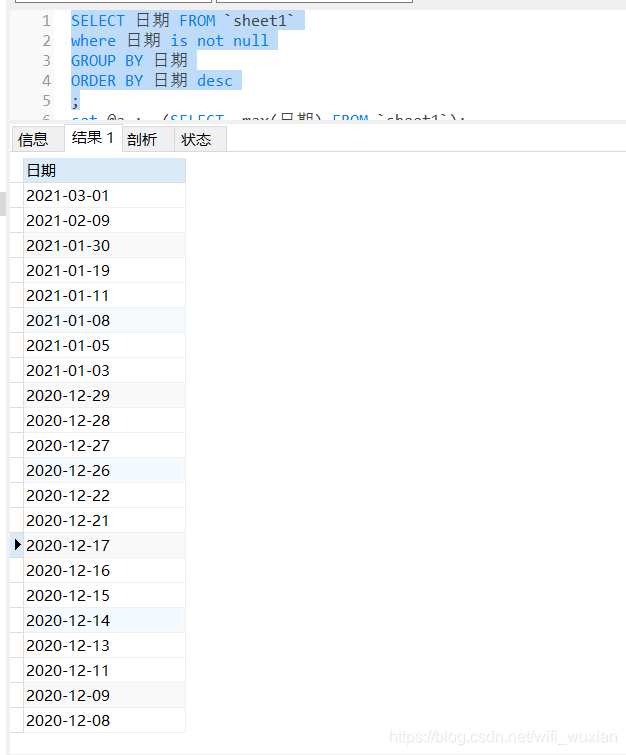
给出两种处理方法:
第一种利用参数解决:
set @a := (SELECT max(日期) FROM `sheet1`);
set @b :=1;
set @c :=1;
SELECT riqi 区间最小日期,DATE_ADD(riqi,INTERVAL rank-1 day) 区间最大日期,rank '连续区间的天数' from
(
SELECT @b :=if(DATEDIFF(@a,日期)=1,@b+1,1) as rank,@a:=日期 as 'riqi'
from
(SELECT 日期 FROM `sheet1`
where 日期 is not null
GROUP BY 日期
ORDER BY 日期 desc
)a
)aa
ORDER BY rank desc
limit 1
;
运行sql,结果如下: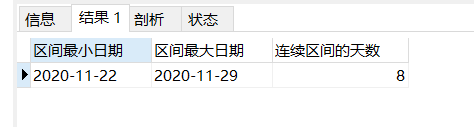
运行子查询的sql,得到区间的连续天数以及区间的最小日期:
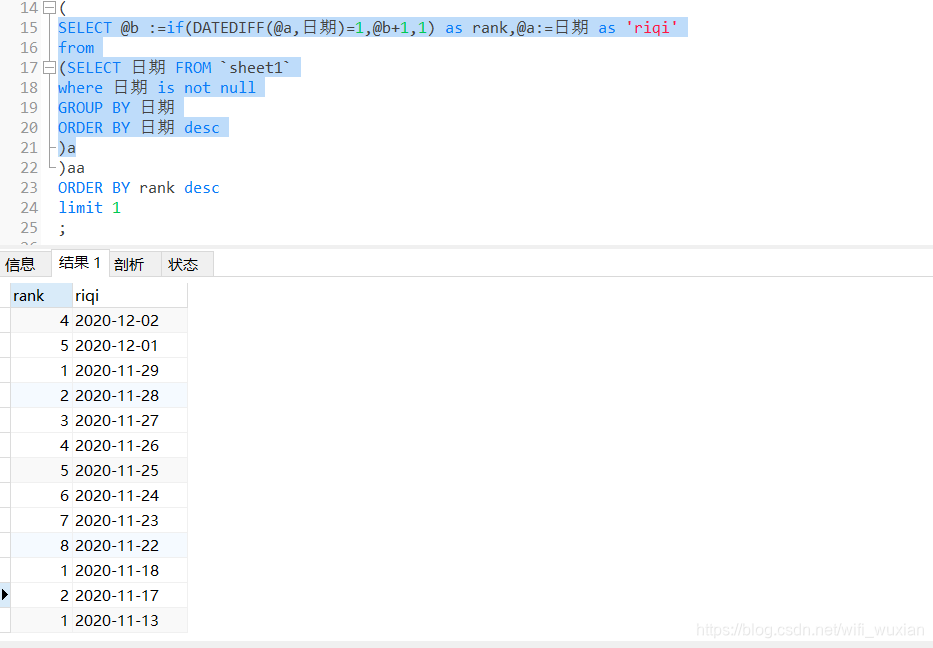
第二种利用连表解决:
SELECT DATE_SUB(max_riqi,interval continue_days-1 day) min_riqi,max_riqi,`continue_days`
from
(
SELECT max(ariqi) max_riqi,count(1) `continue_days`
from
(
SELECT ariqi,
riqigeshu,maxriqi,DATEDIFF(ariqi,maxriqi) days,DATE_SUB(ariqi,INTERVAL riqigeshu day) minriqi
from
(
SELECT a.`日期` ariqi
,(SELECT count(1) from sheet1 b where a.`日期`>=b.`日期`) riqigeshu
,(SELECT max(b.日期) from sheet1 b where a.`日期`>b.`日期`) maxriqi
from sheet1 a
where a.`日期` is not null
order by a.`日期`
)aa
)tt
GROUP BY minriqi
)ww
ORDER BY `continue_days` desc
;
运行结果如下:
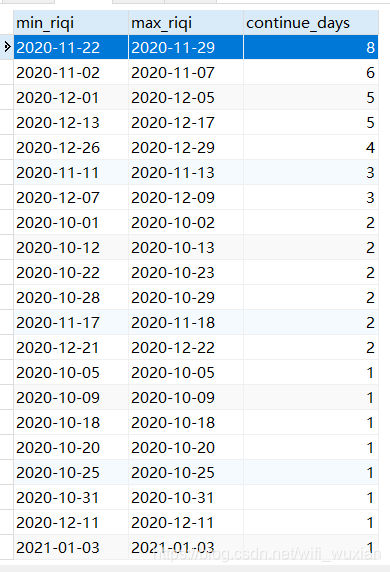
接下来我们用python实现
import pandas as pd
import datetime
df = pd.read_excel(r'C:\Users\wuxian\Desktop\target\date.xlsx')
df = df.sort_values(by=['日期'],ascending=True)
df.index=range(df.shape[0])
df['日期']
def deltadate(end_date,start_date):
pattern="%Y-%m-%d"
deltadays = (datetime.datetime.strptime(end_date,pattern)-datetime.datetime.strptime(start_date,pattern)).days
return deltadays
df['日期'][0]
deltadate(df['日期'][1],df['日期'][0])
df['days_delta']=1
for i in range(df.shape[0]):
try:
if deltadate(df['日期'][i+1],df['日期'][i])==1:
df['days_delta'][i+1]=df['days_delta'][i]+1
else:
df['days_delta'][i]==1
except Exception as e:
print(e)
df['min_date']=''
for i in range(df.shape[0]):
tt=(datetime.datetime.strptime(df['日期'][i],"%Y-%m-%d")+datetime.timedelta(days=int(df['days_delta'][i]))).strftime("%Y-%m-%d")
print(tt)
datetime.timedelta(days=1)
datetime.datetime.strptime(df['日期'][0],"%Y-%m-%d")+datetime.timedelta(days=int(df['days_delta'][0]))
df['min_date'] = df.apply(lambda x :(datetime.datetime.strptime(x['日期'],"%Y-%m-%d")+datetime.timedelta(days=int(-x['days_delta']+1))).strftime("%Y-%m-%d"),axis=1)
df.to_excel(r'C:\Users\wuxian\Desktop\test.xlsx',index=False)














 2211
2211











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









