







DataVault是一个BI系统,包括建模、方法论、架构和实施四个方面。DataVault的组件包括以下四个:
- DataVault建模(对模型性能和可扩展性的更改)
- DataVault方法论(遵循Scrum和敏捷最佳实践)
- DataVault架构(包含NoSQL系统和大数据系统)
- DataVault实施(基于模式、自动化生成能力成熟度模型集成——CMMI第五层及)
DataVault有很多特殊之处,在面向企业数据仓库建模方法中吸收了软件开发最佳实践中的一些经验常识,包括CMMI、六西格玛管理、全面质量管理、精益管理、缩短周期等,并且应用这些理念来解决重复型、一致性、自动化和减少错误方面的问题。DataVault建模主要关注如何建立灵活、可扩展的模型,让模型间协同工作,按照业务键为起义额数据仓库集成原始数据。DataVault建模引入了一些细微变化以确保其建模范例可应用于大数据、非结构化数据、多结构化数据和NoSQL等多种场合。DataVault建模改变了散列键的顺序编号。这样的散列键就能够保持稳定,提供并行装载方法,并且能够对记录的父键值进行解耦计算。DataVault方法论需要集中时间对可重复的数据仓库任务进行适应和优化。DataVault的架构包含了NoSQL、实施馈送、以及用于处理非机构化数据和大数据集成的大数据系统,整合托管式自助服务BI、业务回写、自然语言处理结果集集成等。DataVault实施通过专注于自动化和生成模式以便节省时间、减少错误和快速提升数据仓库团队的生产效率。商业系统和数据仓库系统的成熟需要具备以下关键要素:
- 可重复的模式
- 冗余架构和容错系统
- 高可扩展性
- 极度的灵活性
- 可控制一致的变更吸收成本
- 可度量的关键过程区域
- 缺口分析
- 大数据和非结构化数据的集成
DataVault解决了对大数据、非结构化数据、多结构化数据、NoSQL和托管式自助服务BI的需求。DataVault的目标是采用一种可重复的、一致的和可伸缩的形式,使企业创建BI系统的过程变得成熟,同时提供对新技术的无缝集成。DataVault的商业效益包括:
- 降低了EDW/BI项目的总拥有成本
- 提高了整个团队的敏捷性
- 增加了整个项目的透明度
DataVault的商业优点可以分为:
- 敏捷方法论的优点
1. 驱动敏捷交付周期(2~3周)
2. 包括CMMI、六西格玛、TQM
3. 管理风险、治理和版本控制
4. 定义自动化、生成
5. 设计可重复的优化过程
6. 整合面向BI的最佳实践
- 模型的优点
1. 遵循自由扩展架构
2. 基于轮轴-辐条式设计
3. 由集合逻辑和大规模并行处理数学方法支持
4. 包括NoSQL数据集的无缝集成
5. 支持100%的并行异构装载环境
6. 限制了对局部区域的变更影响
- 架构的优点
1. 提高了解耦能力
2. 确保了低影响的变更
3. 提供了托管式自助服务BI
4. 包含了无缝的NoSQL平台
5. 支持团队敏捷开发
- 方法论的优点
1. 提高了自动化
2. 确保了可扩展性
3. 提供了一致性
4. 具备容错能力
5. 提供了经过验证的标准
DataVault模型是一种中心辐射式模型,其设计重点围绕着业务键的集成模型。DataVault模型是一个面向细节的、历史追溯的并且唯一链接的规范化表集,能够支持一个或者多个业务功能区。在建模风格上,DataVault采用了第三范式与维度模型方法结合的方式(无标度网络设计)。
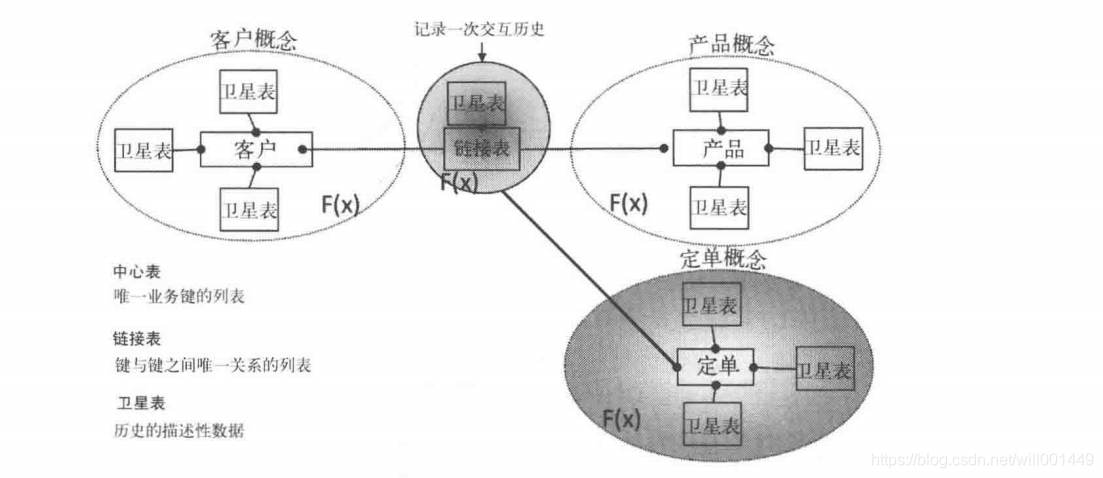
DataVault模型中有三种基本的实体:中心表、链接表和卫星表。中心表表示以横向方式贯穿企业的实际业务键或者主密钥集合;链接表表示企业中存在于业务键之间的关系和联系;真正的数据仓库组件充当卫星表,其中存储了随时间推移的非易失数据。业务键(中心表)是业务中的驱动因素,业务键将数据集与业务过程联系起来,将业务过程与业务需求联系起来。业务键是追踪经过业务过程和跨业务范围数据的唯一源头。正确设计和实现DataVault数据仓库可以辅助完成降低成本开支、提高交付产品的质量、缩短交付产品或服务时间等。跟踪和追寻跨多个业务范围的数据是一种能力,它是创造价值或者将数据作为有案可查的资产的一个重要组成部分。业务中的关键路径分析和建立对多个业务范围的追踪意味着业务工作可以缩短周期,并且可以使业务人员能够识别关键路径,同时消减那些不能增值而智慧减缓产品或者服务的生产和交付的我业务过程。通过业务键组织数据,进而跟踪业务过程,不仅更容易为数据赋予价值,而且更便于理解业务感知与在多源系统之上进行捕获与执行操作的现实性之间的差距。DataVault采用的另一种表结构叫作链接表,链接表结构保存了来自手工过程的输入。DataVault模型不仅提供了直接的业务价值,而且能够随时间的推移跟踪所有的关系,它还展示了可能装载到数据仓库的数据之间不同层次结构。DataVault模型不仅提供了直接的业务价值,而且能够随时间的推移跟踪所有的关系。
在集结区对数据进行重构,可以将跨多个系统的集成工作集中到目标数据仓库的一个单独区域完成,而不需要改变数据本身,这被称为被动集成。DataVault建模需要遵循一些基本原则,其中一些规则包括:
- 业务键是按照粒度和语义内涵进行分割的。这就意味着企业客户键和个人客户键都必须存在,或者用两个不同的中心表结构进行记录
- 关系、事件和跨两个或者多个业务键的交叉关系都要存在链接结构中
- 链接结构没有开始或者结束日期,他们只是对数据到达数据仓库那一时刻的关系的一种表达
- 卫星表是按照数据类型以及变更的类别和速度进行分割的,数据类型一般都是单一的源系统
多对多链接结构允许DataVault模型在未来进行扩展。源系统中表达的关系通常都是对业务规则或者当日业务执行情况反的反应。关系定义会随着事件推移而变化,而且会不断变化,采用这种方式可以解释关系随时间的推移而变化的模式。由于需要连接异构数据环境,散列键对于DataVault很重要,要在装载DataVault结构时消除依赖性。当处理高吞吐量数据或者大数据时,装载程序不需要依赖性,采用顺序方式会迫使负载堆叠。DataVault选用的散列功能时MD5,MD5产生了一个预先计算好的128位的数值,该数值基于业务键的值和业务键的组合情况进行计算,其保持唯一性的概率可达99.8%。
DataVault架构基于三层数据仓库,这三个层次通常确定为集结区、数据仓库和数据集市。
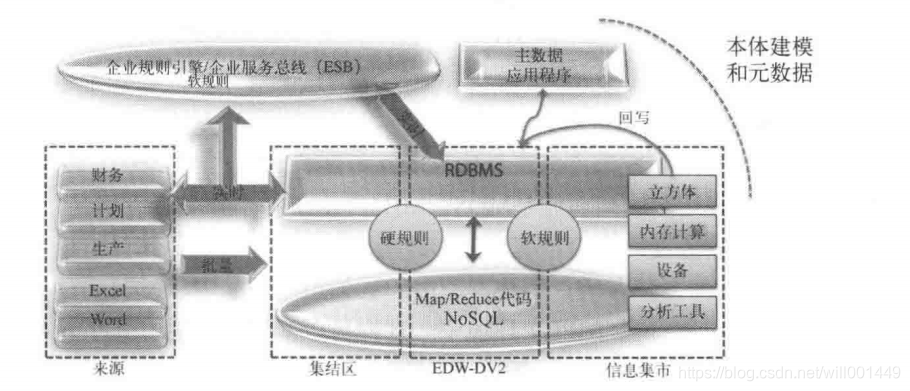
除了以上三个层次,DataVault还规定了一下几个不同的组件:
- 用于处理大数据的Hadoop或NoSQL
- 流入流出BI生态的实时信息流;随着时间的推移,这也会将EDW演化成为一个作业型的数据仓库
- 从回写功能到数据功能的流程采用了托管式SSBI,支持TQM
- 分离了软硬业务规则,使得企业数据仓库成为一个面向原始事实的记录系统,随时间推移不断装载原始事实
NoSQL平台实现有很多种,有的包含类似SQL的接口,有的则将RDBMS技术和非关系型技术结合。很多情况下,NoSQL平台核心都是基于Hadoop的。为了管理不同目录下的文件,这些平台还包括HDFS和元数据管理等功能,各种SQL访问层的实现和内存计算技术则位于HDFS上。对于Hadoop这样的平台来说,当前对他的定位是将其作为一个对所有可能进入数据仓库的数据的摄入和集结数据的区域。这其中包括结构化数据集、多结构化数据集、非结构化数据集等。Hadoop的第二种用途是作为一个执行数据挖掘任务的平台,使用SAS、R或者文本挖掘工具进行数据挖掘。DataVault架构具有以下四个目标:
- 无缝衔接已有的RDBMS和新的NoSQL平台
- 使业务用户参与进来,并且为托管式SSBI提供空间
- 为了实现数据直接实时到达数据仓库环境,不再强制要求数据先进入集结区数据表
- 为了支持敏捷开发,将经常变更的业务规则从静态的数据对准规则中分离
面向BI的DataVault系统提供了实施指南、规则和推荐标准,标准指导着以下实施过程:
- 数据模型、查找业务键、设计实体、应用键结构
- ETL/ELT装载过程
- 实时消息传送
- 信息集市交付过程
- 信息集市的虚拟化
- 自动化最佳实践
- 业务规则
- 托管式自助服务BI的回写功能
DataVault从建模、方法论、架构到实时都有一套独特的方式,因此,从企业实际应用角度出发选择适合的方式才是王道。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









