| 说到ASCII,Unicode和UTF-8,可能大家都知道是字符编码, 但具体含义,以及其中差异,可能很多人都不知道!! 文档
utf8编码为什么这么普遍,优势在哪里?_其他_大数据知识库
编码原理理解之「UTF-8」 - 简书
从ASCII码->Unicode->UTF-8历史变迁,及其差异
GitHub - chrisYooh/CYEncoding: 通过Demo理解不同的编码方式(utf-8, base64...)
https://blog.csdn.net/william_n/article/details/98991881 // Unicode 和 UTF-8 有什么区别
ASCII编码 - 学习/实践_william_n的博客-CSDN博客
PHP页面中文乱码[文件编码] - 学习/实践_william_n的博客-CSDN博客
36 | unicode与字符编码-极客时间 -- 推荐
一、名称解释
ASCII:American Standard Code for Information Interchange,美国信息互换标准代码。
Unicode:统一码、万国码、单一码,是计算机科学领域里的一项业界标准,包括字符集、编码方案等。
UTF-8:8-bit Unicode Transformation Format,是一种针对Unicode的可变长度字符编码。
二、历史变迁
先给大家看一张变迁图:

很久以前,有一群人,他们决定用8个可以开合的晶体管来组合成不同的状态,以表示世界上的万物。
他们看到8个开关状态是好的,于是他们把这称为“字节”。
再后来,他们又做了一些可以处理这些字节的机器,机器开动了,可以用字节来组合出很多状态,状态开始变来变去。他们看到这样是好的,于是它们就这机器称为”计算机“。
开始计算机只在美国使用,八位的字节一共可以组合出256种不同的状态。
他们把其中的编号从0开始的32种状态分别规定了特殊的用途,一但终端、打印机遇上约定好的这些字节被传过来时,就要做一些约定的动作。
遇上0×10, 终端就换行,遇上0×07, 终端就向人们嘟嘟叫。他们看到这样很好,于是就把这些0×20以下的字节状态称为“控制码”。
他们又把所有的空格、标点符号、数字、大小写字母分别用连续的字节状态表示,一直编到了第127号,这样计算机就可以用不同字节来存储英语的文字了。大家看到这样,都感觉很好,于是大家都把这个方案叫做 ANSI 。
补充
在实际应用中接触比较多的文本编码有3种:ASCII、ANSI和UNICODE,其中ASCII码是后两种也是大多数常用编码的基础。
ANSI:美国国家标准学会(AMERICAN NATIONAL STANDARDS INSTITUTE: ANSI)成立于1918年。当时,美国的许多企业和专业技术团体,已开始了标准化工作,但因彼此间没有协调,存在不少矛盾和问题。为了进一步提高效率,数百个科技学会、协会组织和团体,均认为有必要成立一个专门的标准化机构,并制订统一的通用标准。
后来,世界各地都开始使用计算机了,但是很多国家用的不是英文,他们的字母里有许多是ASCII里没有的,为了可以在计算机 保存他们的文字,他们决定采用 127号之后的空位来表示这些新的字母、符号,还加入了很多画表格时需要用到的横线、竖线、交叉等形状,一直把序号编到了最后一个状态255。从128 到255这一页的字符集被称“扩展字符集”。
等中国人们得到计算机时,已经没有可以利用的字节状态来表示汉字,而且常用汉字有六七千个,这个时候,中国人民就使用了一套汉字方案叫做GB2312”。随着发展,又发现了一些局限,所以就有了GBK,再继续往后增加了一些字符(如少数民族字体),GBK扩成了 GB18030。

因为当时各个国家都像中国这样搞出一套自己的编码标准,结果互相之间谁也不懂谁的编码,谁也不支持别人的编码,连大陆和台湾这样只相隔了150海里也使用不同编码。
这个时候,出现了一个叫 ISO 组织(国际标准化组织)决定着手解决这个问题。
他们采用的方法很简单:
废了所有的地区性编码方案,重新搞一个包括了地球上所有文化、所有字母和符号 的编码!
-- 自然是要包含兼容所有的文化符号~,都要录入~
他们打算叫它 Universal Multiple-Octet Coded Character Set,简称 UCS, 俗称 Unicode。
但是Unicode同样也有2个问题:
1. 计算机怎么知道两个字节为一个字符,如何识别两个字节为什么一个字符?
2. 针对英文字符,如果使用大于1个字节来表示,那么低位的前面几个字节全是0。
很奢侈浪费空间,因为现在计算机大部分内容还是英文。
Unicode在很长一段时间内无法推广,直到互联网的出现,为解决Unicode如何在网络上传输的问题,于是面向传输的众多 UTF(UCS Transfer Format)标准出现了。
顾名思义,UTF-8就是每次8个位传输数据,而UTF-16就是每次16个位。
--- 问题:涉及到网络传输,每次的网络传输大小是有限制的,难道跟文件具体编码还有关系?TBD
UTF-8就是在互联网上使用最广的一种Unicode的实现方式,这是为传输而设计的编码,并使编码无国界,这样就可以显示全世界上所有文化的字符了。 -- 理解参见3. 问题/补充 第2点
三、Charset and Encoding -- 字符集与编码

1. 什么是字符集
Charset (Character set) 字符集:是对字符抽象表示的集合。包括世界上各种文字、符号和字符。
字符集只是一个规则集合的名字,对应到真实生活中,字符集就是对某种语言的称呼。
例如:
英语,汉语,日语。
2. 什么是字符编码
对于一个字符集来说, 要正确编码 / 转码一个字符。
需要三个关键元素:
字库表(character repertoire)、编码字符集(coded character set)、字符编码(character encoding)。
备注:
这三者之间的关系, 建议多读几遍, 理清楚.
字库表,是一个相当于所有可读或者可显示字符的数据库。
字库表决定了整个字符集能够展现表示的所有字符的范围。
编码字符集,即用一个编码值code point来表示一个字符在字库中的位置,这个编码值的集合。
字符编码,将编码字符集和实际存储数值之间的转换关系。--- 这个没理解? 意思应是即便通过编码值在字库表中找到了某个字符,也是不能直接可展示的,还需要进行转换才行~
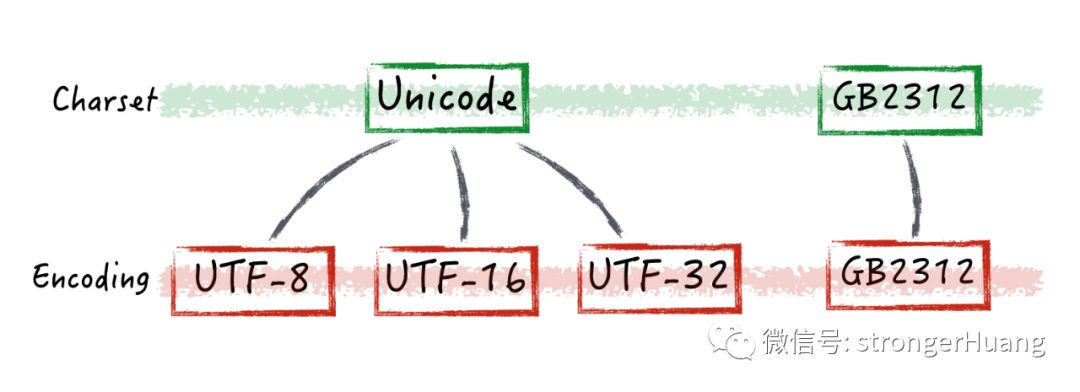
四、UTF-8和Unicode的关系
看完上面两个概念解释,相信你应该明白其中关系了。
Unicode就是上文中提到的编码字符集,而UTF-8就是字符编码,即Unicode规则字库的一种实现形式。
随着互联网的发展,对同一字库集的要求越来越迫切,Unicode标准也就自然而然的出现。
它几乎涵盖了各个国家语言可能出现的符号和文字,并将为他们编号。
五、进一步理解UTF-8编码
UTF-8编码为变长编码。
最小编码单位(code unit)为一个字节。
一个字节的前1-3个bit为描述性部分,后面为实际序号部分。
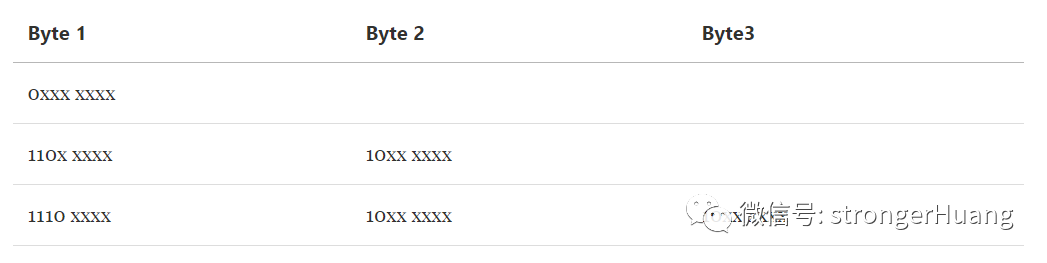
1. 如果一个字节的第一位为0,那么代表当前字符为单字节字符,占用一个字节的空间。
0之后的所有部分(7个bit)代表在Unicode中的序号。
2. 如果一个字节以110开头,那么代表当前字符为双字节字符,占用2个字节的空间。
110之后的所有部分(5个bit)加上后一个字节的除10外的部分(6个[ 8-2 ]bit)代表在Unicode中的序号。且第二个字节以10开头。
3. 如果一个字节以1110开头,那么代表当前字符为三字节字符,占用3个字节的空间。
1110之后的所有部分(4个bit)加上后两个字节的除10外的部分(12 [ 8-2 + 8-2 ]个bit)代表在Unicode中的序号。且第二、第三个字节以10开头[第三个字节开头在上图中看不清楚]
总结下来,针对UTF8,编码规则其实只有两条:
1)单字节规则: 对于 单字节 的符号,字节的第一位(最高位)设为 0,后面 7 位为这个符号的 unicode 码。
2)n字节规则: 对于 n 字节的符号(n>1),第一个字节的前 n 位都设为 1,第 n+1 位设为 0,后面字节的前两位一律设为 10。剩下的没有提及的二进制位,全部为这个符号的 unicode 码。
来看一个UTF-8编码例子:

发现其中规律:
1个字节的UTF-8十六进制编码, 是以比8小的数字开头的
2个字节的UTF-8十六进制编码, 是以C或D开头的
3个字节的UTF-8十六进制编码, 是以E开头的
后续补充 ... | 


























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









