








Kafka协议
Kafka是linkedin开源的一个数据传输框架,主要的定位是解决一个数据源多个消费者的应用场景,支持和Storm、Spark、Flume对接,提供负载均衡和容错的集群,用来传输各种数据日志。
Links
关于Kafka的介绍,请参考kafka doc。
关于Kafaka的协议,请参考kafka protocol。
关于Kafka的设计理念,参考kafka log。
本文主要是记录kafka协议中的重点。
Introduction
The protocol used in 0.7 and earlier is similar to this, but we chose to make a one time (we hope) break in compatibility to be able to clean up cruft
and generalize things.这个协议是0.8的,0.7以及更早的协议和这个类似,但是0.8的协议和之前的是不兼容的,希望0.8重新设计后能做一次彻底了断,并且以后都保持兼容性。
Overview
Metadata - Describes the currently available brokers, their host and port information, and gives information about which broker hosts
which partitions.这个api是从broker获取metadata,包含可用的brokers,它们的host和port信息,以及broker和partition的对应关系。
Network
Kafka uses a binary protocol over TCP. The protocol defines all apis as request response message pairs.Kafka使用基于TCP的字节协议(像RTMP那种,而不像HTTP那种文本协议),API就是由Request和Response实现的。
The client initiates a socket connection and then writes a sequence of request messages and reads back the corresponding response message.
No handshake is required on connection or disconnection.客户端和broker建立连接后,就可以发一些Request,然后读取对应的Respone。没有必要握手,直接连接上就可以发。
The client will likely need to maintain a connection to multiple brokers, as data is partitioned and the clients will need to talk to the server that has
their data. However it should not generally be necessary to maintain multiple connections to a single broker from a single client instance (i.e.
connection pooling).客户端对每个broker都需要维护一个connection,因为数据是分区的(partitioned),客户端需要和拥有这个分区的服务器交流。但是一个客户端对一个broker没有必要使用多个连接,譬如没有必要用连接池。
Partitioning and bootstrapping
Kafka is a partitioned system so not all servers have the complete data set. Kafka是个分区的(partitioned)系统,因此broker不一定有完整的数据集。
All systems of this nature have the question of how a particular piece of data is assigned to a particular partition. Kafka clients directly control this
assignment, the brokers themselves enforce no particular semantics of which messages should be published to a particular partition. 类似的系统都有一个问题:消息如何分配到某个分区。Kafka是交给客户端处理的这个,也就是Kafka的客户端发送消息时指定发送到哪个分区。Broker并不关心消息发送到哪个分区。
These requests to publish or fetch data must be sent to the broker that is currently acting as the leader for a given partition. This condition is
enforced by the broker, so a request for a particular partition to the wrong broker will result in an the NotLeaderForPartition error code.客户端发布或获取数据时,必须向角色为Leader的broker发送,非leader的broker会返回NotLeaderForPartition的错误码。
How can the client find out which topics exist, what partitions they have, and which brokers currently host those partitions so that it can direct its
requests to the right hosts? This information is dynamic, so you can't just configure each client with some static mapping file. Instead all Kafka
brokers can answer a metadata request that describes the current state of the cluster: what topics there are, which partitions those topics have,
which broker is the leader for those partitions, and the host and port information for these brokers.客户端如何知道topic是否存在,topic有哪些分区,哪个broker有这个分区?这个信息是动态的,所有的broker都能提供当前集群的状态:有哪些topic?topic分成了哪些分区?Leader broker是谁?Broker的host和port是多少?
In other words, the client needs to somehow find one broker and that broker will tell the client about all the other brokers that exist and what
partitions they host. This first broker may itself go down so the best practice for a client implementation is to take a list of two or three urls to
bootstrap from. 也就是说,客户端需要连接到某个broker,然后通过这个broker找到能提供服务的broker。可以先给客户端一个broker的列表,不至于一个broker挂掉就无法工作了。
The client does not need to keep polling to see if the cluster has changed; it can fetch metadata once when it is instantiated cache that metadata
until it receives an error indicating that the metadata is out of date. 客户端不需要一直去请求元数据,来判断集群是否改变了状态,它只需要在启动时取一次元数据就好了。如果集群状态改变了,譬如topic的broker迁移了,或者新增了分区之类的,客户端会收到一个错误码指出元数据过期了。
Partitioning Strategies
Partitioning really serves two purposes in Kafka:
1. It balances data and request load over brokers
2. It serves as a way to divvy up processing among consumer processes while allowing local state and preserving order within the partition.
We call this semantic partitioning.分区可以有两个重要的用途:
- 分区是broker负载均衡的实现,即一个负载很高消息很多的topic可以分区,由多个broker来处理这些分区,每个broker只处理一个或几个分区。
- 语义分区。客户端可以根据某种语义进行分区,譬如按照客户端的uuid作为key,这样一个客户端肯定会到一个分区,这个客户端也肯定会被consumer group的某个consumer处理。
Batching
Both our API to send
messages and our API to fetch messages always work with a sequence of messages not a single message to encourage this.为了提高性能,可以一次发送多个Request;当然也可以一次一个。
Versioning and Compatibility
Our versioning is on a per-api basis, each version
consisting of a request and response pair.
The intention is that clients would implement a particular version of the protocol, and indicate this version in their requests. Our goal is primarily to
allow API evolution in an environment where downtime is not allowed and clients and servers cannot all be changed at once.我们的版本是基于API的,也就是每个Request中都会指定版本信息,Response会根据Request的版本给出对应的响应。
客户端可以实现协议的某个版本,我们主要的目标是支持不能停机更新的业务场景,客户端可以部分升级而不用全部升级。(这个指的是客户端可以混着用不同的版本,升级的时候可以新版本和老版本共存,不用一升级到新版本就导致老版本客户端无法工作)
The server will reject requests with a version it does not support, and will always respond to the client with exactly the protocol format it expects
based on the version it included in its request.如果服务器版本过低,或者客户端发起了更高版本的请求。服务器会返回错误,并且指出它能支持的最高版本。
ConsumerGroup
其实Kafka的ConsumerGroup和Consumer本身没有什么关系。我一直以为Consumer必须在一个Group中,所以一直难以理解这块的结构,看了Kafka的客户端API以及协议,发现其实Consumer和ConsumerGroup一毛钱关系都没有。
Kafka自己提供了两种Consumer的API:high level和low level;而Consumer的API协议是在fetch,ConsumerGroup是在offset commit。
从low level consumer的实例example,例子中的findLeader是查找某个分区的Leader,然后获取offset是getLastOffset也是指定的分区的,而读取消息是发送的FetchRequest消息读取Response。从中可以看出,和Producer一样,Consumer也是拿到分区后读的,这个和ConsumerGroup没有什么关系,是可以的。
为什么要ConsumerGroup呢?因为Consumer会拿到这个分区的所有消息。因此Kafka在这儿基础上,再加了一层结构,就是ConsumerGroup。既然是要多个Consumer之间负载均衡,那么就必须要共享信息;早期Kafka是用的zookeeper,而0.8之后就是用的broker,可以看协议:
Consumer Metadata Request
The offsets for a given consumer group are maintained by a specific broker called the offset coordinator. 或者说,high level consumer的实现中,实际上用到了zookeeper,貌似还没有迁移过来,可以参考实例,指定zookeeper和group后调用createMessageStreams获取KafkaStream,其实就是获取能读取的分区了。
Consumer的实现,大致分为以下几步:
ConsumerGroup的实现,大致分为以下几步:
- 连接Broker获取元数据,和Consumer一样。
- 向offset管理者发起请求,拿到自己负责的分区,参考协议
- 读取消息,和Consumer一样。
- 同时不断维护offset,和offset管理者通信,参考协议
对照Kafka的结构图:
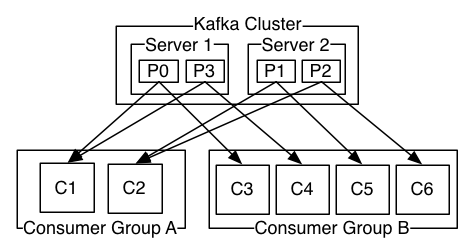
实际上ConsumerGroup是由Consumer和Broker里面的offset管理者(或者zookeeper)维护的概念,目标就是找到自己负责的那个分区。
这就是说,最终一个分区的消息,默认是分配到所有的Consumer上的,或者说所有的Consumer是可以读取的。但是ConsumerGroup是让Consumer知道哪些应该读,而不是Broker将消息不发送给某些Consumer。
这个就是为何Kafka一个ConsumerGroup的Consumer数目,不能比分区多,多出来的Consumer是拿不到消息的。因为多出来的Consumer去向offset管理者请求自己负责的分区时,没有了,已经被别的Consumer分担完了。参考Kafka的说明:
Note however that there cannot be more consumer instances than partitions.因此Kafka的负载均衡核心就是分区,一个Consumer至少会收到一个分区的消息,如果一个分区的消息太多了,那没有办法,只能再新开分区来降低Consumer的负载。
回过头来说,其实Consumer实现很简单的,直接发消息了读就可以。而ConsumerGroup却很复杂,涉及到了信息同步,共享,提交之类的。可以有一个简单的在应用层的方法,就是Consumer自己协调,不同的Consumer来负责不同的分区,或者通过配置(这种就是扩展不方便,更简单),譬如topic有4个分区,可以起2个Consumer每个负责2个分区,这种对于能重启的Consumer是个可行的办法。














 1779
1779











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









