







kafka更新matadata的总体流程
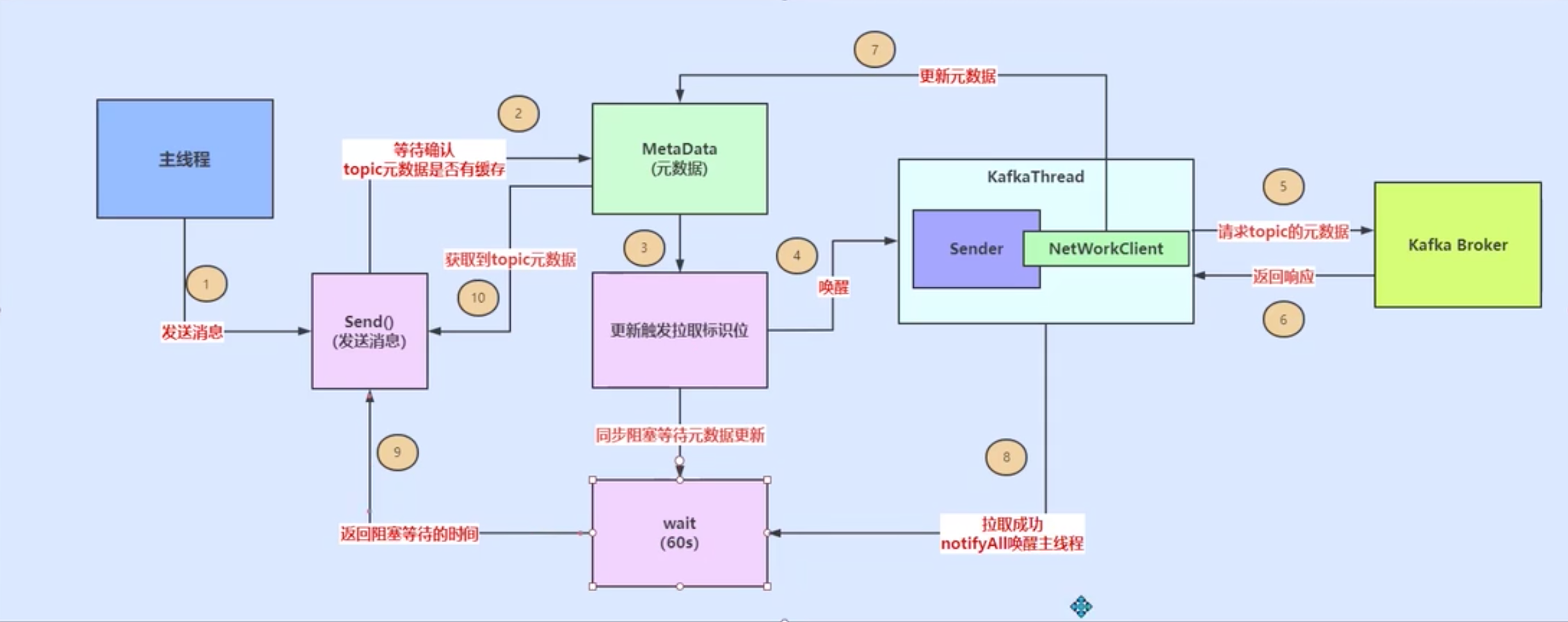
Kafka集群元数据
Kafka每个Topic中有多个分区,这些分区的Leader副本可以分配在集群中不同的Broker上。我们站在生产者的角度来看,分区的数量以及Leader副本的分布是动态变化的。通过简单的示例说明这种动态变化:在运行过程中,Leader副本随时都有可能出现故障进而导致Leader副本的重新选举,新的Leader副本会在其他Broker上继续对外提供服务。当需要提高某Topic的并行处理消息的能力时,我们可以通过增加其分区的数量来实现。当然,还有别的方式导致这种动态变化,例如,手动触发“优先副本”选举等。
我们创建的ProducerRecord中只指定了Topic的名称,并未明确指定分区编号。KafkaProducer要将此消息追加到指定Topic的某个分区的Leader副本中,首先需要知道Topic的分区数量,经过路由后确定目标分区,之后KafkaProducer需要知道目标分区的Leader副本所在服务器的地址、端口等信息,才能建立连接,将消息发送到Kafka中。因此,在KafkaProducer中维护了Kafka集群的元数据,这些元数据记录了:某个Topic中有哪几个分区,每个分区的Leader副本分配哪个节点上,Follower副本分配哪些节点上,哪些副本在ISR集合中以及这些节点的网络地址、端口。
在KafkaProducer中,使用Node、TopicPartition、PartitionInfo这三个类封装了Kafka集群的相关元数据,其主要字段如下图所示。
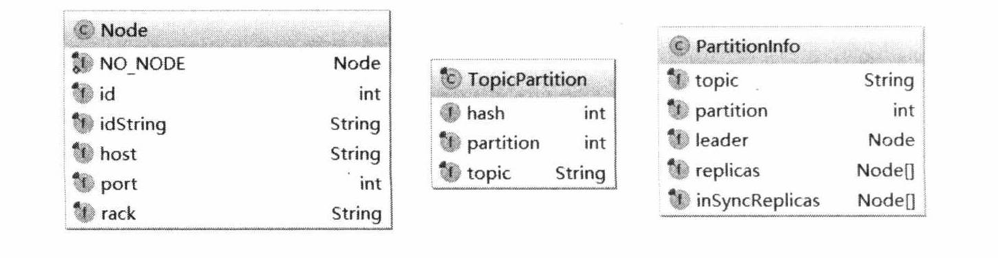
- Node表示集群中的一个节点,Node记录这个节点的host、ip、port等信息。
- TopicPartition表示某Topic的一个分区,其中的topic字段是Topic的名称,partition字段则此分区在Topic中的分区编号(ID)。
- PartitionInfo表示一个分区的详细信息。其中topic字段和partition字段的含义与TopicPartition中的相同,除此之外,leader字段记录了Leader副本所在节点的 id,replica字段记录了全部副本所在的节点信息,inSyncReplicas字段记录了ISR 集合中所有副本所在的节点信息。
通过这三个类的组合,我们可以完整表示出 KafkaProducer需要的集群元数据。这些元数据保存在了Cluster这个类中,并按照不同的映射方式进行存放,方便查询。
Cluster类的核心字段如图下图所示。

- nodes: Kafka集群中节点信息列表。
- nodesById:Brokerld与Node节点之间对应关系,方便按照Brokerld进行索引。 partitionsBy TopicPartition:记录了TopicPartition与PartitionInfo的映射关系。
- partitionsBy Topic:记录了Topic名称和PartitionInfo的映射关系,可以按照Topic 名称查询其中全部分区的详细信息。
- availablePartitionsByTopic: Topic与PartitionInfo的映射关系,这里的List中存放的分区必须是有Leader副本的Parttion,而parttionsByTopic中记录的分区则不一定有Leader副本,因为某些中间状态,例如Leader副本宕机而触发的选举过程中,分区不一定有Leader副本。
- partitionsByNode:记录了Node与PartitionInfo的映射关系,可以按照节点Id查询其上分布的全部分区的详细信息。
Cluster 的方法比较简单,主要是对上述集合的操作,方便集群元数据的查询。例如,partitionsForTopic方法:
public List<PartitionInfo> partitionsForTopic (string topic) {
return this.partitionsByTopic.get(topic);//获取指定topic的分区集合
}
其余方法这里不再赘述了。值得注意的一点是,Node、TopicPartition、PartitionInfo、 Cluster的所有字段都是private final修饰的,且只提供了查询方法,并未提供任何修改方法,这就保证了这四个类的对象都是不可变性对象,它们也就成为了线程安全的对象。
Metadata中封装了Cluster对象,并保存Cluster数据的最后更新时间、版本号(version)、 是否需要更新等待信息,是今天我们要介绍的主角。
下面介绍一下Metadata的核心字段。
public final class Metadata {
...
private final long refreshBackoffMs; //更新失败的情况下,下1次更新的补偿时间(这个变量在代码中意义不是太大)
private final long metadataExpireMs; //关键值:每隔多久,更新一次。缺省是600*1000,也就是10分种
private int version; //每更新成功1次,version递增1。这个变量主要用于在while循环,wait的时候,作为循环判断条件
private long lastRefreshMs; //上一次更新时间(也包含更新失败的情况)
private long lastSuccessfulRefreshMs; //上一次成功更新的时间(如果每次都成功的话,则2者相等。否则,lastSuccessulRefreshMs < lastRefreshMs)
private Cluster cluster; //集群配置信息
private boolean needUpdate; //是否强制刷新
、
...
}
public final class Cluster {
...
private final List<Node> nodes; //Node也就是Broker
private final Map<TopicPartition, PartitionInfo> partitionsByTopicPartition; //Topic/Partion和broker list的映射关系
private final Map<String, List<PartitionInfo>> partitionsByTopic;
private final Map<String, List<PartitionInfo>> availablePartitionsByTopic;
private final Map<Integer, List<PartitionInfo>> partitionsByNode;
private final Map<Integer, Node> nodesById;
}
public class PartitionInfo {
private final String topic;
private final int partition;
private final Node leader;
private final Node[] replicas;
private final Node[] inSyncReplicas;
}
下面介绍一下Metadata的核心字段。
- nodes:记录了当前已知的所有的节点信息,在cluster字段中记录了Topic最新的元数据。
- version:表示Kafka集群元数据的版本号。Kafka集群元数据每更新成功一次,version字段的值增1。通过新旧版本号的比较,判断集群元数据是否更新完成。
- metadataExpireMs:每隔多久,更新一次。默认是300x1000,也就是5分种。
- refreshBackoffMs:两次发出更新Cluster保存的元数据信息的最小时间差,默认为100ms。这是为了防止更新操作过于频繁而造成网络阻塞和增加服务端压力。在 Kafka中与重试操作有关的操作中,都有这种“退避(backoff)时间”设计的身影。
- lastRefreshMs:记录上一次更新元数据的时间戳(也包含更新失败的情况)。
- lastSuccessfulRefreshMs:上一次成功更新的时间戳。如果每次都成功,则lastSuccessfulRefreshMs、 lastRefreshMs相等。否则,lastRefreshMs > lastSuccessulRefreshMsc
- cluster:记录Kafka集群的元数据。
- needUpdate:标识是否强制更新Cluster,这是触发Sender线程更新集群元数据的条件之一。
- listeners:监听Metadata更新的监听器集合。自定义Metadata监听实现Metadata.Listener.onMetadataUpdate()方法即可,在更新Metadata中的cluster字段之前,会通知listener集合中全部Listener对象。
- needMetadataForAllTopics:是否需要更新全部Topic的元数据,一般情况下,KafkaProducer只维护它用到的Topic的元数据,是集群中全部Topic的子集。
Metadata的方法比较简单,主要是操纵上面的几个字段,这里着重介绍主线程用到的requestUpdate方法和awaitUpdate方法。requestUpdate方法将needUpdate字段修改为true,这样当Sender线程运行时会更新Metadata记录的集群元数据,然后返回version字段的值。awaitUpdate方法主要是通过version版本号来判断元数据是否更新完成,更新未完成则阻塞等待,代码如下所示。
metadata的初始化
在kafkaProducer初始化的时候,对metadata数据进行过update,但这次update未进行实质性操作。

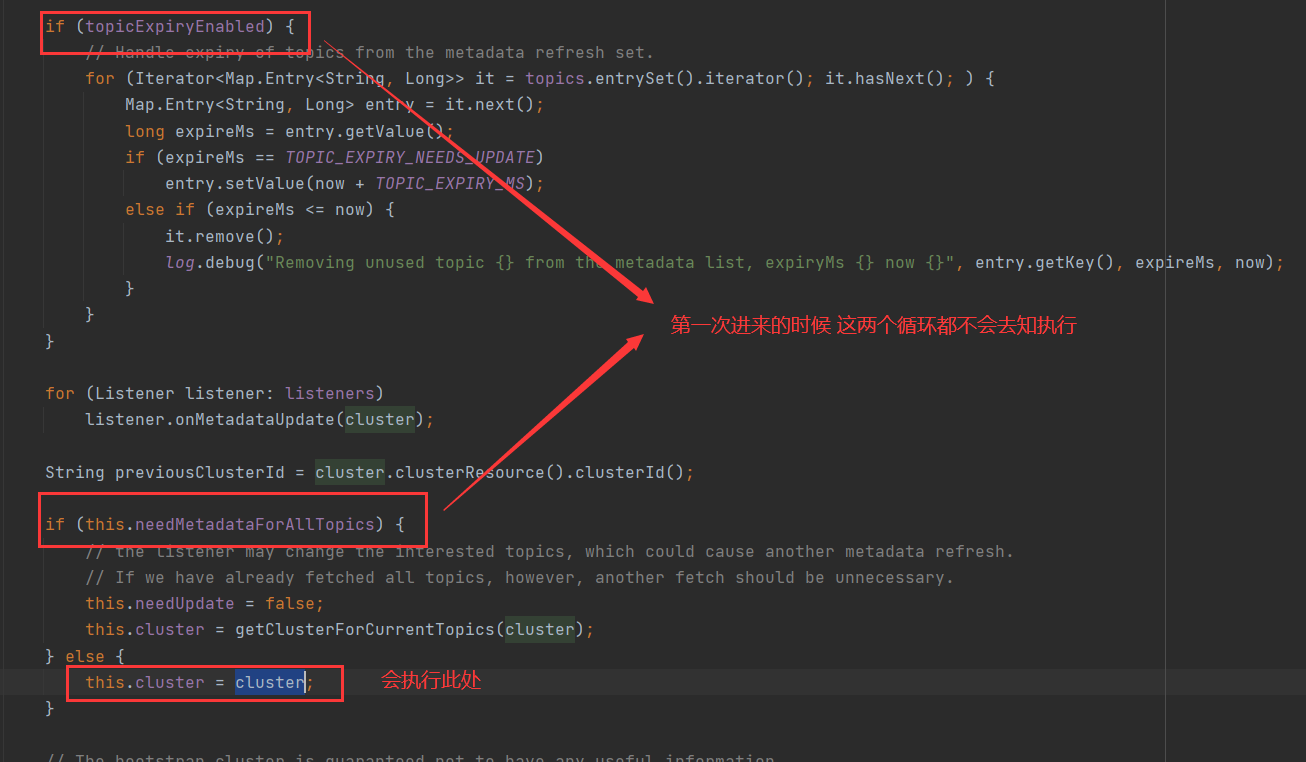
上面的操作只是将我们初始传入的集群节点更新到cluster字段当中,在新建的 Cluter添加了bootstrap的配置信息,并无任何原参数信息。
真正的第一次获取
可能你们会好奇prodecer啥时候才会进行元数据的获取。
答案:是在第一次发送数据的时候。
我们不妨进入producer的send方法中。
send()
@Override
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
// intercept the record, which can be potentially modified; this method does not throw exceptions
ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record);
return doSend(interceptedRecord, callback);
}
当配置了拦截器就会触发拦截器的doSend方法,此处我们忽略,主要去看KafkaProducer的doSend方法。
doSend()
waitOnMetadata()
/**
* Wait for cluster metadata including partitions for the given topic to be available.
* @param topic The topic we want metadata for
* @param partition A specific partition expected to exist in metadata, or null if there's no preference
* @param nowMs The current time in ms
* @param maxWaitMs The maximum time in ms for waiting on the metadata
* @return The cluster containing topic metadata and the amount of time we waited in ms
* @throws TimeoutException if metadata could not be refreshed within {@code max.block.ms}
* @throws KafkaException for all Kafka-related exceptions, including the case where this method is called after producer close
*/
private ClusterAndWaitTime waitOnMetadata(String topic, Integer partition, long nowMs, long maxWaitMs) throws InterruptedException {
// add topic to metadata topic list if it is not there already and reset expiry
Cluster cluster = metadata.fetch();
if (cluster.invalidTopics().contains(topic))
throw new InvalidTopicException(topic);
metadata.add(topic, nowMs);
Integer partitionsCount = cluster.partitionCountForTopic(topic);
// Return cached metadata if we have it, and if the record's partition is either undefined
// or within the known partition range
if (partitionsCount != null && (partition == null || partition < partitionsCount))
return new ClusterAndWaitTime(cluster, 0);
long remainingWaitMs = maxWaitMs;
long elapsed = 0;
// Issue metadata requests until we have metadata for the topic and the requested partition,
// or until maxWaitTimeMs is exceeded. This is necessary in case the metadata
// is stale and the number of partitions for this topic has increased in the meantime.
do {
if (partition != null) {
log.trace("Requesting metadata update for partition {} of topic {}.", partition, topic);
} else {
log.trace("Requesting metadata update for topic {}.", topic);
}
metadata.add(topic, nowMs + elapsed);
int version = metadata.requestUpdateForTopic(topic);
//唤醒 sender 线程,间接唤醒 NetworkClient 线程,NetworkClient 线程来负责发送 Metadata 请求,并处理 Server 端的响应。
sender.wakeup();
try {
// 同步等待sender线程拉取元数据
metadata.awaitUpdate(version, remainingWaitMs);
} catch (TimeoutException ex) {
// Rethrow with original maxWaitMs to prevent logging exception with remainingWaitMs
throw new TimeoutException(
String.format("Topic %s not present in metadata after %d ms.",
topic, maxWaitMs));
}
cluster = metadata.fetch();
elapsed = time.milliseconds() - nowMs;
if (elapsed >= maxWaitMs) {
throw new TimeoutException(partitionsCount == null ?
String.format("Topic %s not present in metadata after %d ms.",
topic, maxWaitMs) :
String.format("Partition %d of topic %s with partition count %d is not present in metadata after %d ms.",
partition, topic, partitionsCount, maxWaitMs));
}
metadata.maybeThrowExceptionForTopic(topic);
remainingWaitMs = maxWaitMs - elapsed;
partitionsCount = cluster.partitionCountForTopic(topic);
} while (partitionsCount == null || (partition != null && partition >= partitionsCount));
// 死循环
return new ClusterAndWaitTime(cluster, elapsed);
}
这里fetch是直接从缓存中获取到已存在的元数据。在第一次发送,我们知道此时这个cluster是没有数据的,这里面只有我们作为参数的addresses而已。根据我们的场景驱动,在第一次执行到这里时也是刚好KafkaProducer初始化完成的时候。此时cluster并没有获取到元数据。
接下来的Integer partitionsCount = cluster.partitionCountForTopic(topic)这里是根据当前的topic从集群中的cluster查看分区信息,但是同理,第一次执行时也是没有数据的,这里的partitionsCount为null。
awaitUpdate()
同步等待获取metadata数据,直到sender线程获取metadata之后版本号被更新或者等待超时。
/**
* Wait for metadata update until the current version is larger than the last version we know of
*/
public synchronized void awaitUpdate(final int lastVersion, final long timeoutMs) throws InterruptedException {
long currentTimeMs = time.milliseconds();
long deadlineMs = currentTimeMs + timeoutMs < 0 ? Long.MAX_VALUE : currentTimeMs + timeoutMs;
time.waitObject(this, () -> {
// Throw fatal exceptions, if there are any. Recoverable topic errors will be handled by the caller.
maybeThrowFatalException();
return updateVersion() > lastVersion || isClosed();
}, deadlineMs);
if (isClosed())
throw new KafkaException("Requested metadata update after close");
}
虽然我们还没去看Sender线程的源码,可是我们猜也能猜到,更新元数据成功之后一定会把这个在metadata对象上wait的线程给唤醒。
这里设计到sender线程的相关逻辑
sender的初始化
KafkaProducer的构造函数中对于sender线程进行了初始化并且在new KafkaThread中将sender传入进去,它就是把这个线程设置成后台线程。它不直接启动而是创建线程把Sender传进去的原因就是因为它要把业务代码和线程相关的代码隔离开来,就算之后你还要增加一些参数给这个线程,你也直接在 KafkaThread.java 中补充即可。
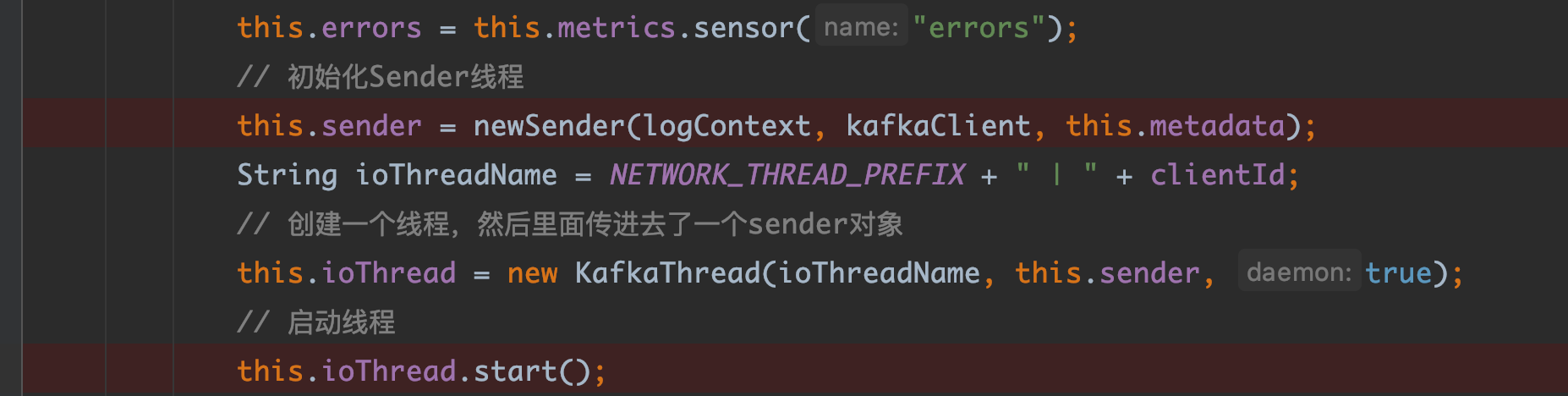
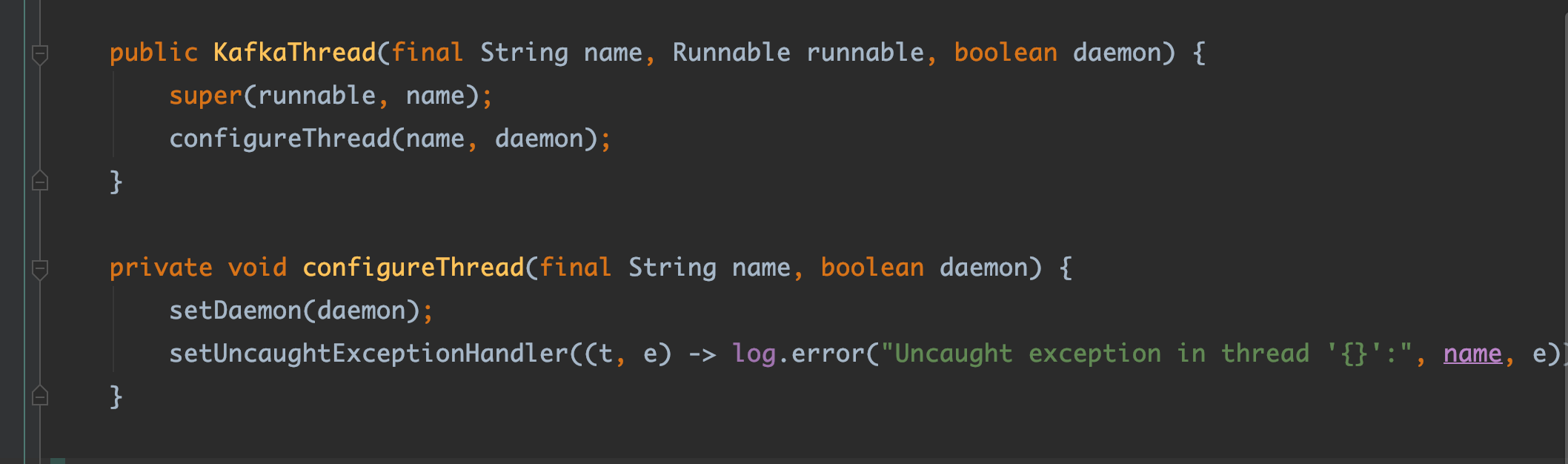
我们知道,在调用线程的start方法时,会调用其run方法,我们进一步查看sender的run方法,如下。
run()
public void run() {
log.debug("Starting Kafka producer I/O thread.");
// main loop, runs until close is called
while (running) {
try {
runOnce();
} catch (Exception e) {
log.error("Uncaught error in kafka producer I/O thread: ", e);
}
}
...
}
runOnce()
/**
* Run a single iteration of sending
*
*/
void runOnce() {
if (transactionManager != null) {
try {
transactionManager.maybeResolveSequences();
// do not continue sending if the transaction manager is in a failed state
if (transactionManager.hasFatalError()) {
RuntimeException lastError = transactionManager.lastError();
if (lastError != null)
maybeAbortBatches(lastError);
client.poll(retryBackoffMs, time.milliseconds());
return;
}
// Check whether we need a new producerId. If so, we will enqueue an InitProducerId
// request which will be sent below
transactionManager.bumpIdempotentEpochAndResetIdIfNeeded();
if (maybeSendAndPollTransactionalRequest()) {
return;
}
} catch (AuthenticationException e) {
// This is already logged as error, but propagated here to perform any clean ups.
log.trace("Authentication exception while processing transactional request", e);
transactionManager.authenticationFailed(e);
}
}
long currentTimeMs = time.milliseconds();
long pollTimeout = sendProducerData(currentTimeMs);
client.poll(pollTimeout, currentTimeMs);
}
runOnce()里面,前面都是涉及到事务的一系列操作,我们再此先不做分析,直到最后一行调用了client.poll()方法。
Poll()
public List<ClientResponse> poll(long timeout, long now) {
ensureActive();
if (!abortedSends.isEmpty()) {
// If there are aborted sends because of unsupported version exceptions or disconnects,
// handle them immediately without waiting for Selector#poll.
List<ClientResponse> responses = new ArrayList<>();
handleAbortedSends(responses);
completeResponses(responses);
return responses;
}
// 这里包含了查询元数据信息的请求
long metadataTimeout = metadataUpdater.maybeUpdate(now);
try {
this.selector.poll(Utils.min(timeout, metadataTimeout, defaultRequestTimeoutMs));
} catch (IOException e) {
log.error("Unexpected error during I/O", e);
}
// process completed actions
long updatedNow = this.time.milliseconds();
List<ClientResponse> responses = new ArrayList<>();
handleCompletedSends(responses, updatedNow);
handleCompletedReceives(responses, updatedNow);
handleDisconnections(responses, updatedNow);
handleConnections();
handleInitiateApiVersionRequests(updatedNow);
handleTimedOutRequests(responses, updatedNow);
completeResponses(responses);
return responses;
}
接下来的流程相对比较复杂,而且里面设计到很多NIO的知识,我们这里简单进行介绍,从上面的maybeUpdate方法中,最后调用到了doSend()方法来进行真正的信息发送的过程,如下所示。
private void doSend(ClientRequest clientRequest, boolean isInternalRequest, long now, AbstractRequest request) {
String destination = clientRequest.destination();
RequestHeader header = clientRequest.makeHeader(request.version());
if (log.isDebugEnabled()) {
log.debug("Sending {} request with header {} and timeout {} to node {}: {}",
clientRequest.apiKey(), header, clientRequest.requestTimeoutMs(), destination, request);
}
Send send = request.toSend(destination, header);
InFlightRequest inFlightRequest = new InFlightRequest(
clientRequest,
header,
isInternalRequest,
request,
send,
now);
this.inFlightRequests.add(inFlightRequest);
selector.send(send);
}
上面主要是向inFlightRequests中存储request对象,存储的是还没有响应的请求,这里与配置参数MAX_IN_FLIGHT_REQUEST_PER_CONNECTION有关,默认为5,这里的请求数量最多就只能存储5个,后面些请求如果有了响应,就会从inFlightRequests中移除出去。
之后我们点send方法,此时会跳到Selectable.java里面,发现send是个抽象方法,实现是Selector.java
send()和setSend()
public void send(Send send) {
String connectionId = send.destination();
KafkaChannel channel = openOrClosingChannelOrFail(connectionId);
if (closingChannels.containsKey(connectionId)) {
// ensure notification via `disconnected`, leave channel in the state in which closing was triggered
this.failedSends.add(connectionId);
} else {
try {
channel.setSend(send);
} catch (Exception e) {
// update the state for consistency, the channel will be discarded after `close`
channel.state(ChannelState.FAILED_SEND);
// ensure notification via `disconnected` when `failedSends` are processed in the next poll
this.failedSends.add(connectionId);
close(channel, CloseMode.DISCARD_NO_NOTIFY);
if (!(e instanceof CancelledKeyException)) {
log.error("Unexpected exception during send, closing connection {} and rethrowing exception {}",
connectionId, e);
throw e;
}
}
}
}
public void setSend(Send send) {
if (this.send != null)
throw new IllegalStateException("Attempt to begin a send operation with prior send operation still in progress, connection id is " + id);
this.send = send;
this.transportLayer.addInterestOps(SelectionKey.OP_WRITE);
}
这里的`this.transportLayer.addInterestOps(SelectionKey.OP_WRITE)将selectionKey与channel的写事件进行绑定,实现了监听响应的作用,我们接下来退回到networkClient的poll方法,进行接收响应并处理的流程。
接收响应并处理
上面请求发出去了我们自然是要接收服务端返回的响应的
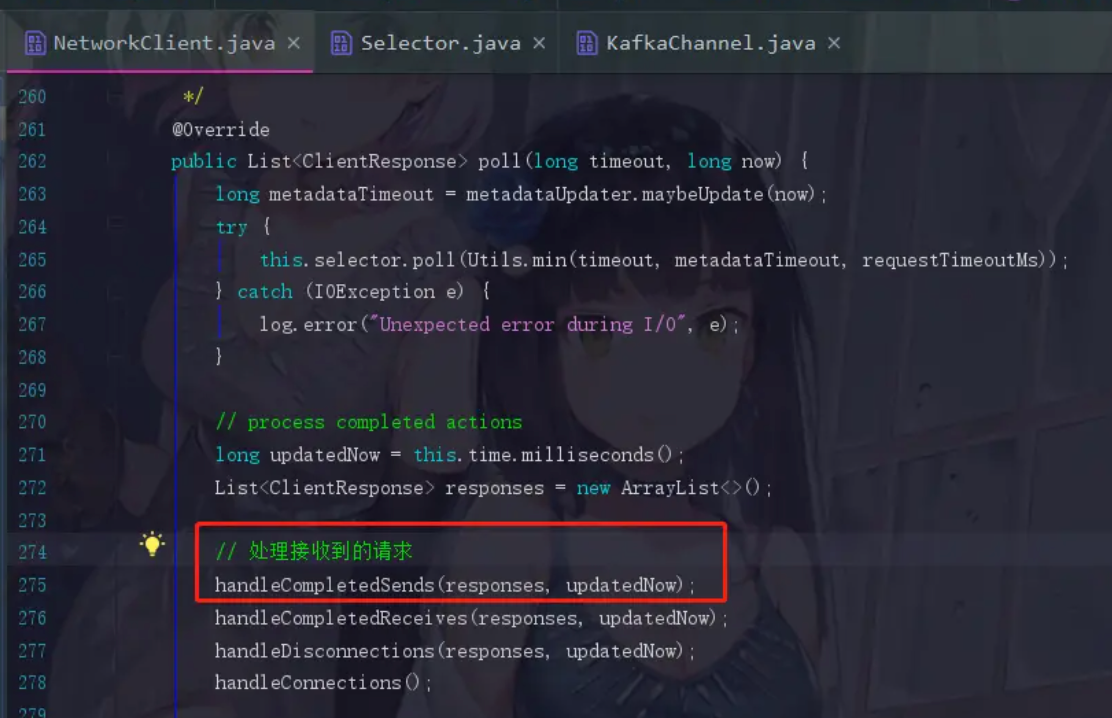
点进去handleCompletedSends
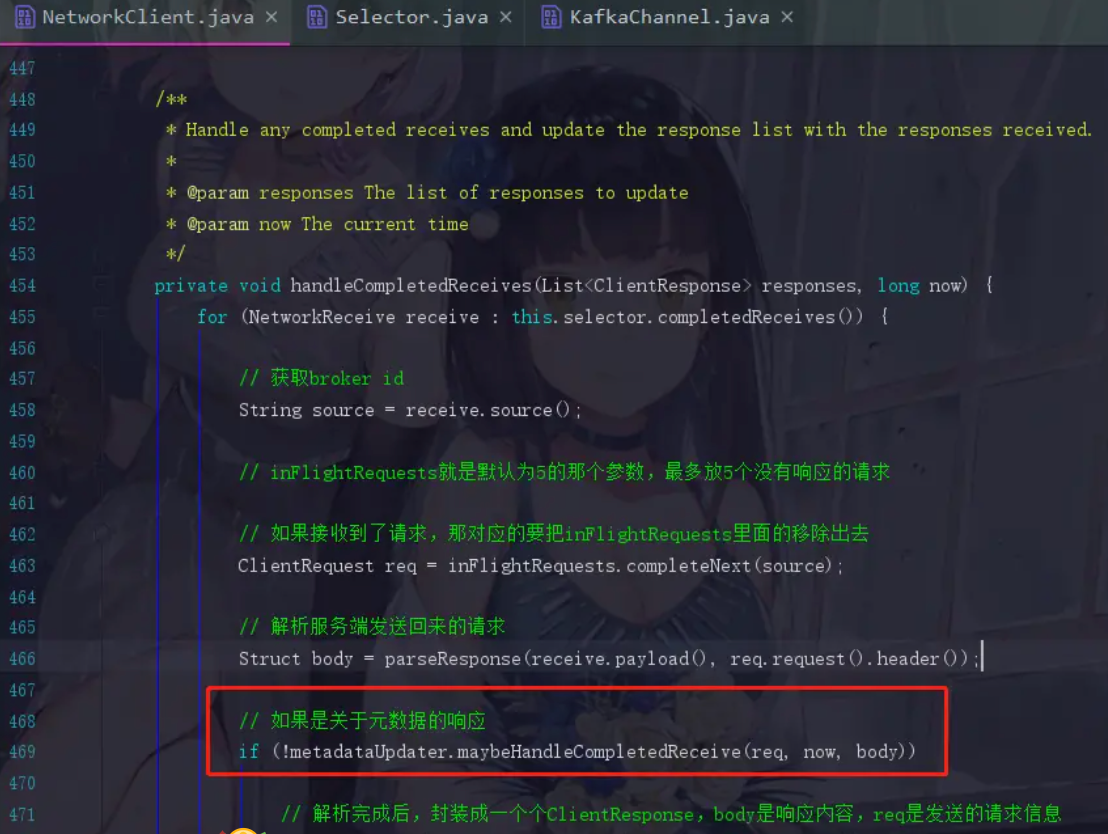
maybeHandleCompletedReceive就是处理响应的方法
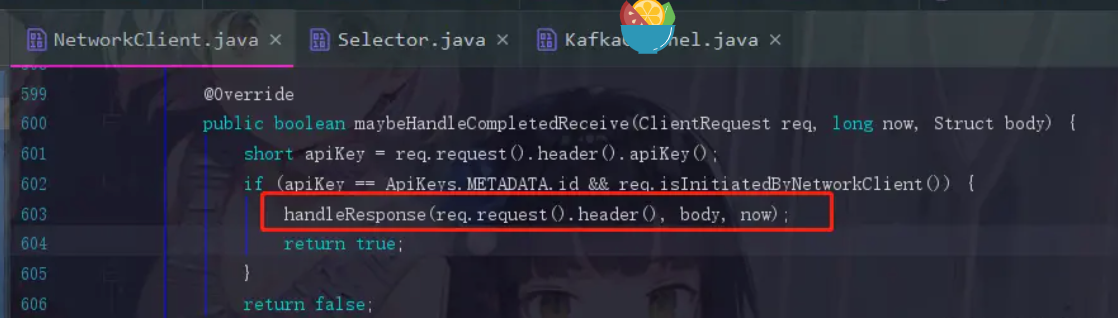
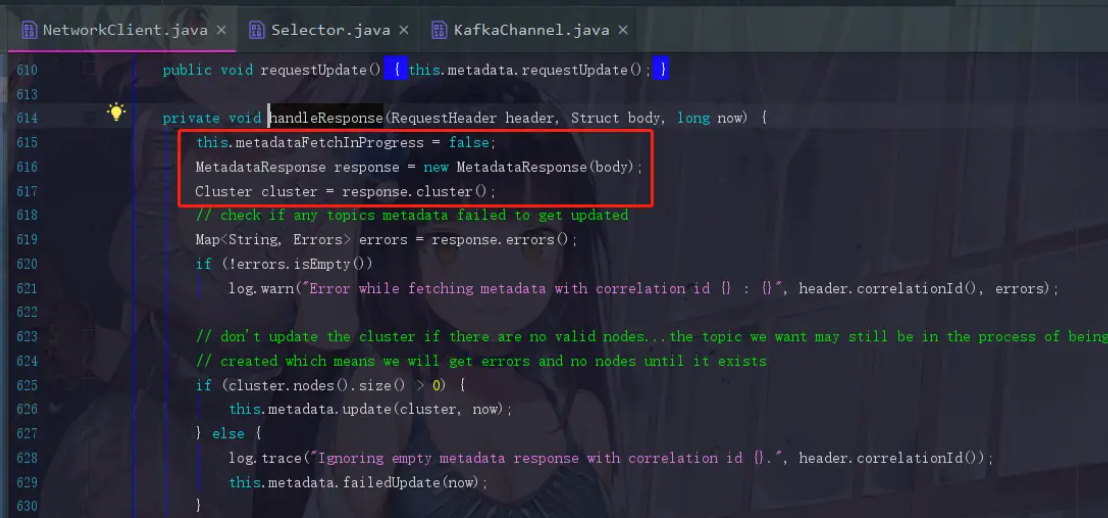
MetadataResponse response = new MetadataResponse(body);
因为服务端发送回来的也是一个二进制的数据结构,所以生产者在这里要对它进行解析,并封装成一个MetadataResponse对象
Cluster cluster = response.cluster();
响应里面会带有元数据的信息,现在进行获取cluster对象了
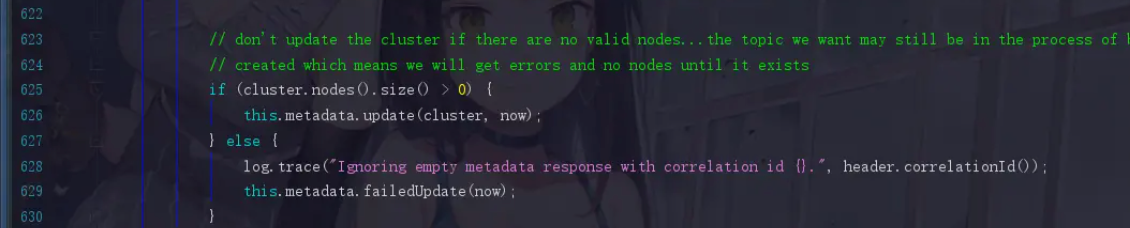
后面开始进行判断,如果cluster.nodes().size() > 0,那就已经成功获取到元数据对象了,此时update,这个方法点进去你也会看到,version=version+=1,版本号加一了。关键点是后面还会有一句notifyAll()方法,把刚刚同步等待元数据信息的线程唤醒,让代码退出while循环。
所以到此,就是一个完整的获取到元数据的过程了。
参考资料
本文的参考自Kafka源码篇 — 你一定能get到的Producer的初始化及元数据获取流程
以及徐郡明编著的《Apache Kafka源码剖析》















 997
997











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









