







一、集群
1.1 特性
如果RabbitMQ服务器遇到内存崩溃、机器掉电或者主板故 障等情况,该怎么办?单台RabbitMQ服务器可以满足每秒1000条消息的吞吐量,那么如果应 用需要RabbitMQ服务满足每秒10万条消息的吞吐量呢?购买昂贵的服务器来增强单机 RabbitMQ服务的性能显得捉襟见肘,搭建一个RabbitMQ集群才是解决实际问题的关键。
RabbitMQ集群允许消费者和生产者在RabbitMQ单个节点崩溃的情况下继续运行,它可以 通过添加更多的节点来线性地扩展消息通信的吞吐量。当失去一个RabbitMQ节点时,客户端 能够重新连接到集群中的任何其他节点并继续生产或者消费。
不过RabbitMQ集群不能保证消息的万无一失,即将消息、队列、交换器等都设置为可持 久化,生产端和消费端都正确地使用了确认方式。当集群中一个RabbitMQ节点崩溃时,该节 点上的所有队列中的消息也会丢失。
RabbitMQ集群中的所有节点都会备份所有的元数据信息,
1.队列元数据:队列的名称及属性;
2.交换器:交换器的名称及属性;
3.绑定关系元数据:交换器与队列或者交换器与交换器之间的绑定关系;
4.vhost元数据:为vhost内的队列、交换器和绑定提供命名空间及安全属性。
但是不会备份消息,在RabbitMQ集群中创建队列,集群只会在单 个节点而不是在所有节点上创建队列的进程并包含完整的队列信息(元数据、状态、内容)。这 样只有队列的宿主节点,即所有者节点知道队列的所有信息,所有其他非所有者节点只知道队 列的元数据和指向该队列存在的那个节点的指针。因此当集群节点崩溃时,该节点的队列进程 和关联的绑定都会消失。附加在那些队列上的消费者也会丢失其所订阅的信息,并且任何匹配该队列绑定信息的新消息也都会消失。
不同于队列那样拥有自己的进程,交换器其实只是一个名称和绑定列表。当消息发布到交 换器时,实际上是由所连接的信道将消息上的路由键同交换器的绑定列表进行比较,然后再路 由消息。当创建一个新的交换器时,RabbitMQ所要做的就是将绑定列表添加到集群中的所有节 点上。这样,每个节点上的每条信道都可以访问到新的交换器了。
1.2 集群节点类型
RabbitMQ中的每一个节点,不管是单一节点系统或者是集群中的一部分, 要么是内存节点,要么是磁盘节点。内存节点将所有的队列、交换器、绑定关系、用户、权限和vhost 的元数据定义都存储在内存中,而磁盘节点则将这些信息存储到磁盘中。单节点的集群中必然只有 磁盘类型的节点,否则当重启RabbitMQ之后,所有关于系统的配置信息都会丢失。不过在集群中, 可以选择配置部分节点为内存节点,这样可以获得更高的性能。
在集群中创建队列、交换器或者绑定关系的时候,这些操作直到所有集群节点都成功提交 元数据变更后才会返回。对内存节点来说,这意味着将变更写入内存;而对于磁盘节点来说, 这意味着昂贵的磁盘写入操作。内存节点可以提供出色的性能,磁盘节点能够保证集群配置信 息的高可靠性,如何在这两者之间进行抉择呢?
RabbitMQ只要求在集群中至少有一个磁盘节点,所有其他节点可以是内存节点。当节点加 入或者离开集群时,它们必须将变更通知到至少一个磁盘节点。如果只有一个磁盘节点,而且 不凑巧的是它刚好崩溃了,那么集群可以继续发送或者接收消息,但是不能执行创建队列、交 换器、绑定关系、用户,以及更改权限、添加或删除集群节点的操作了。也就是说,如果集群 中唯一的磁盘节点崩溃,集群仍然可以保持运行,但是直到将该节点恢复到集群前,你无法更 改任何东西。所以在建立集群的时候应该保证有两个或者多个磁盘节点的存在。
在内存节点重启后,它们会连接到预先配置的磁盘节点,下载当前集群元数据的副本。当 在集群中添加内存节点时,确保告知其所有的磁盘节点(内存节点唯一存储到磁盘的元数据信 息是集群中磁盘节点的地址)。只要内存节点可以找到至少一个磁盘节点,那么它就能在重启后 重新加入集群中。
除非使用的是RabbitMQ的RPC功能,否则创建队列、交换器及绑定关系的操作确是甚少, 大多数的操作就是生产或者消费消息。为了确保集群信息的可靠性,或者在不确定使用磁盘节 点或者内存节点的时候,建议全部使用磁盘节点。
二、跨越集群的界限
RabbitMQ可以通过3种方式实现分布式部署:集群、Federation和Shovel。这3种方式不 是互斥的,可以根据需要选择其中的一种或者以几种方式的组合来达到分布式部署的目的。 Federation和Shovel可以为RabbitMQ的分布式部署提供更高的灵活性,但同时也提高了部署的复杂性。
2.1 Federation
Federation插件的设计目标是使RabbitMQ在不同的Broker节点之间进行消息传递而无须建 立集群,该功能在很多场景下都非常有用:
1.Federation插件能够在不同管理域(可能设置了不同的用户和vhost,也可能运行在不同 版本的RabbitMQ和Erlang上)中的Broker或者集群之间传递消息。
2.Federation插件基于AMQP 0-9-1协议在不同的Broker之间进行通信,并设计成能够容忍不稳定的网络连接情况。
3.—个Broker节点中可以同时存在联邦交换器(或队列)或者本地交换器(或队列),只 需要对特定的交换器(或队列)创建Federation连接(Federation link)。
4.Federation不需要在N个Broker节点之间创建0(N2)个连接(尽管这是最简单的使用方 式),这也就意味着Federation在使用时更容易扩展。
Federation插件可以让多个交换器或者多个队列进行联邦。一个联邦交换器(federated exchange)或者一个联邦队列(federated queue)接收上游(upstream)的消息,这里的上游是 指位于其他Broker上的交换器或者队列。联邦交换器能够将原本发送给上游交换器(upstream exchange)的消息路由到本地的某个队列中;联邦队列则允许一个本地消费者接收到来自上游 队列(upstream queue)的消息。
2.1.1 联邦交换器
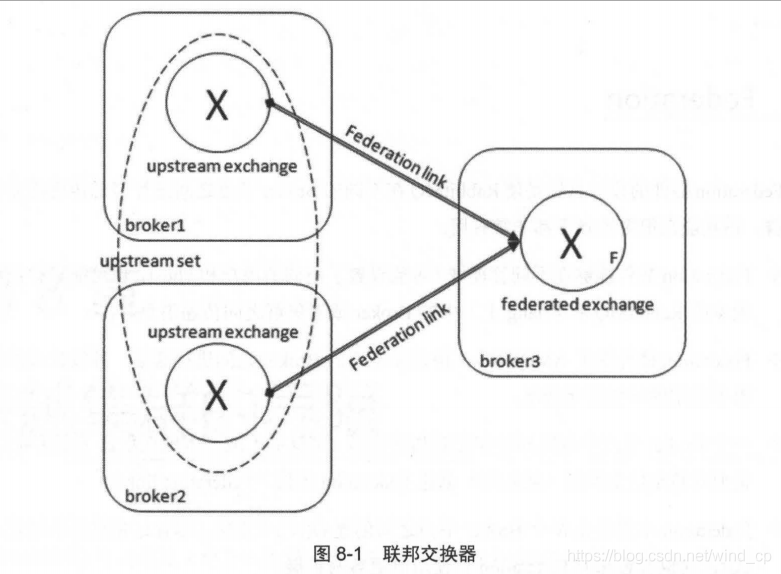
假设brokerl部署在北京,broker2部署在上海,而broker3部署在广州,彼此之间相距甚远,网络延迟是一个不得不面对的问题。
比如有一个在广州的业务ClientA需要连接broker3,并向其中的交换器exchangeA发送消息, 此时的网络延迟很小,ClientA可以迅速将消息发送至exchangeA中,就算在开启了 publisher confirm机制或者事务机制的情况下,也可以迅速收到确认信息。此时又有一个在北京的业务 ClientB需要向exchangeA发送消息,那么ClientB与broker3之间有很大的网络延迟,ClientB 将发送消息至exchangeA会经历一定的延迟,尤其是在开启了 publisher confirm机制或者事务 机制的情况下,ClientB会等待很长的延迟时间来接收broker3的确认信息,进而必然造成这条 发送线程的性能降低,甚至造成一定程度上的阻塞。
为解决上述问题我们可以引入Federation插件,这样可以很好的解决上述问题。
在broker3中为交换器exchangeA (broker3中的队列queueA通过“rkA” 与exchangeA进行了绑定)与广州的brokerl之间建立一条单向的Federation link。此时Federation插件会在brokerl上会建立一个同名的交换器exchangeA (这个名称可以配置,默认同名),同 时建立一个内部的交换器“exchangeA—broker3 B”,并通过路由键“rkA”将这两个交换器绑定 起来。这个交换器“exchangeA —broker3 B”名字中的“broker3”是集群名,可以通过 rabbitmqctl set_cluster_name {new_name}命令进行修改。与此同时 Federation 插件 还会在 brokerl 上建立一个队列 “federation: exchangeA—broker3 B”,并与交换器 “exchangeA —broker3 B” 进行绑定。Federation 插件会在队列 “federation: exchangeA—broker3 B” 与 broker3 中的交换器exchangeA之间建立一条AMQP连接来实时地消费队列“federation: exchangeA— broker3B”中的数据。这些操作都是内部的,对外部业务客户端来说这条Federation link建立在 brokerl 的 exchangeA 和 broker3 的 exchangeA 之间
。
部署在北京的业务ClientB可以连接broker1并向exchangeA发送消息,这样ClientB可以迅速发送完消息并收到确认信息,而之后消息会通过Federation link转发到 broker3的交换器exchangeA中。最终消息会存入与exchangeA绑定的队列queueA中,消费者 最终可以消费队列queueA中的消息。经过Federation link转发的消息会带有特殊的headers属 性标记。例如向brokerl中的交换器exchangeA发送一条内容为“federation test payload.”的持 久化消息,之后可以在broker3中的队列queueA中消费到这条消息。

Federation不仅便利于消息生产方,同样也便利于消息消费方。假设某生产者将消息存入 brokerl中的某个队列queueB,在广州的业务ClientC想要消费queueB的消息,消息的流转及 确认必然要忍受较大的网络延迟,内部编码逻辑也会因这一因素变得更加复杂,这样不利于 ClientC的发展。不如将这个消息转发的过程以及内部复杂的编程逻辑交给Federation去完成, 而业务方在编码时不必再考虑网络延迟的问题。Federation使得生产者和消费者可以异地部署而 又让这两方感受不到过多的差异。
比如brokerl的队列“federation: exchangeA->broker3 B”是一个相对普通的队列,可 以直接通过客户端进行消费。假设此时还有一个客户端ClientD通过Basic.Consume来消费 队列 “federation: exchangeA—broker3 B” 的消息,那么发往 brokerl 中 exchangeA 的消息会有 一部分(一半)被ClientD消费掉,而另一半会发往broker3的exchangeA。所以如果业务应用 有要求所有发往brokerl中exchangeA的消息都要转发至broker3的exchangeA中,此时就要注 意队列“federation: exchangeA—broker3B”不能有其他的消费者;而对于“异地均摊消费”这 种特殊需求,队列“federation: exchangeA—broker3 B”这种天生特性提供了支持。对于brokerl 的交换器exchangeA而言,它是一个普通的交换器,可以创建一个新的队列绑定它,对它的用 法没有什么特殊之处。
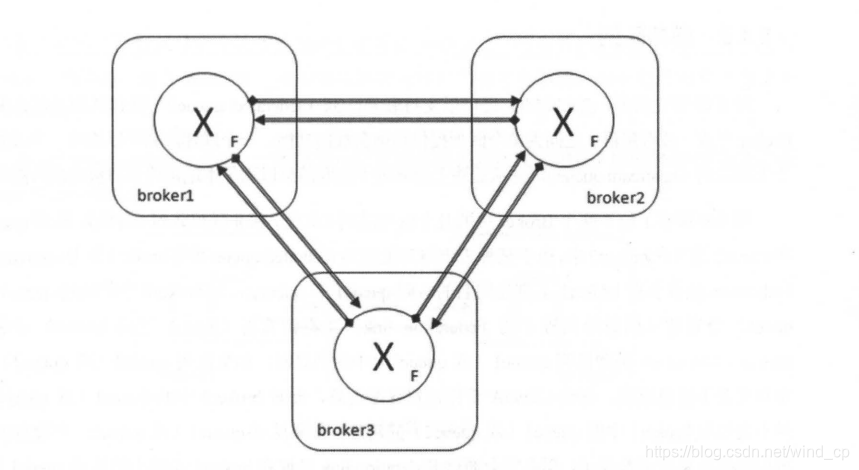
一个federated exchange同样可以成为另一个交换器的upstream exchange。两方的交换器可以互为federated exchange和upstream exchange。其中参数 “max_hops=1”表示一条消息最多被转发的次数为1。(事实是无论这个参数怎么变,消息至多被转发一次,其它的情况只能是消息被复制)
需要特别注意的是,对于默认的交换器(每个vhost下都会默认创建一个名为“”的交换 器)和内部交换器而言,不能对其使用Federation的功能。
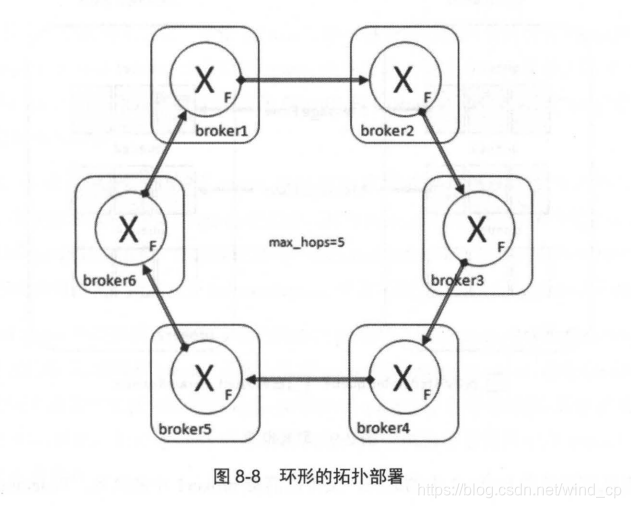
拓扑设计:



2.1.2 联邦队列
除了联邦交换器,RabbitMQ还可以支持联邦队列(federated queue)。联邦队列可以在多个 Broker节点(或者集群)之间为单个队列提供均衡负载的功能。一个联邦队列可以连接一个或者多 个上游队列(upstream queue),并从这些上游队列中获取消息以满足本地消费者消费消息的需求。
下图演示了位于两个Broker中的几个联邦队列(灰色)和非联邦队列(白色)。队列queuel 和queue2原本在broker2中,由于某种需求将其配置为federated queue并将brokerl作为upstream。 Federation插件会在broker 1上创建同名的队列queue 1和queue2,与broker2中的队列queue 1和 queue2分别建立两条单向独立的Federation link。当有消费者ClinetA连接broker2并通过 Basic.Consume消费队列queuel (或queue2)中的消息时,如果队列queuel (或queue2)中 本身有若干消息堆积,那么ClientA直接消费这些消息,此时broker2中的queuel (或queue2) 并不会拉取brokerl中的queuel (或queue2)的消息;如果队列queuel (或queue2)中没有消息 堆积或者消息被消费完了,那么它会通过Federation link拉取在brokerl中的上游队列queuel (或 queue2)中的消息(如果有消息),然后存储到本地,之后再被消费者ClientA进行消费。

消费者既可以消费bmker2中的队列,又可以消费brokerl中的队列,Federation的这种分布式队列的部署可以提升单个队列的容量。如果在brokerl —端部署的消费者来不及消费队列 queuel中的消息,那么broken2—端部署的消费者可以为其分担消费,也可以达到某种意义上 的负载均衡。
和federated exchange不同,一条消息可以在联邦队列间转发无限次。

队列中的消息除了被消费,还会转向有多余消费能力的一方,如果这种“多余的消费能 力”在brokerl和broker2中来回切换,那么消费也会在brokerl和broker2中的队列queue中来回转发。
可以在其中一个队列上发送一条消息“msg”,然后再分别创建两个消费者ClientB和ClientC 分别连接brokerl和br〇ker2,并消费队列queue中的消息,但是并不需要确认消息(消费完消 息不需要调用Basic.Ack)。来回开启/关闭ClientB和ClientC可以发现消息“msg”会在brokerl 和broker2之间串来串去。
federated queue并不具备传递性。Basic.Get是一个异步的方法,如果要从 brokerl中队列queue拉取消息,必须要阻塞等待通过Federation link拉取消息存入broker2中的队 列queue之后再消费消息,所以对于federated queue而言只能使用Basic. Consume进行消费。

队列queue2作为federated queue与 队列queue1进行联邦,而队列queue2又作为队列queue3的upstream queue,但是这样队列queuel 与queue3之间并没有产生任何联邦的关系。如果队列queuel中有消息堆积,消费者连接broker3 消费queue3中的消息,无论queue3处于何种状态,这些消费者都消费不到queuel中的消息, 除非queue2有消费者。
注意要点:
理论上可以将一个federated queue与一个federated exchange绑定起来,不过这样会导致一 些不可预测的结果,如果对结果评估不足,建议慎用这种搭配方式。
2.1.3 Federation使用
为了能够使用Federation功能,需要配置以下2个内容:
需要配置一个或多个upstream,每个upstream均定义了到其他节点的Federation link。 这个配置可以通过设置运行时的参数(Runtime Parameter)来完成,也可以通过federation management插件来完成。
需要定义匹配交换器或者队列的一种/多种策略(Policy)。
Federation upstream
有关Federation upstream的信息全部都保存在RabbitMQ的Mnesia数据库中,包括用户信 息、权限信息、队列信息等。在Federation中存在3种级别的配置。
Upstreams:每个upstream用于定义与其他Broker建立连接的信息。
Upstream sets:每个 upstream set 用于对一系列使用 Federation 功能的 upstream 进行分组。
Policies:每一个Policy会选定出一组交换器,或者队列,亦或者两者皆有而进行 限定,进而作用于一个单独的upsteam或者upstream set之上。
实际上,在简单使用场景下,基本上可以忽略upstream set的存在,因为存在一种名为“all” 并且隐式定义的upstream set,所有的upstream都会添加到这个set之中。Upstreams和 Upstream sets都属于运行时参数,就像交换器和队列一样,每个vhost都持有不同的参数 和策略的集合。
Federation
a.设置:
Federation相关的运行时参数和策略都可以通过下面3种方式进行设置:
1.通过 rabbitmqctl 工具。
2.通过RabbitMQ Management插件提供的HTTP API接口
3.通过rabbitmq_federation_management插件提供的Web管理界面的方式(最 方便且通用)。不过基于Web管理界面的方式不能提供全部功能,比如无法针对upstream set进行管理。
b.步骤:
使用Federation插件
(第一步)
需要在brokerl和broker3中开启rabbitmq_federation插件,最好同时开启 rabbitmq—federation—management 插件。
(第二步)
在 broker3 中定义一个 upstream。
第一种是通过rabbitmqctl工具的方式,
第二种是通过调用HTTP API接口的方式
第三种是通过在Web管理界面中添加的方式,在“Admin” 一* “FederationUpstreams” 一 “ Add a new upstream ” 中创建。

web界面参数详解:
Name:定义这个upstream的名称。必填项。
URI (uri):定义upstream的AMQP连接。必填项。本示例中可以填写为amqp://root:root 123@192.168.0.2:5672
Prefetch count (prefetch_count):定义 Federation 内部缓存的消息条数,即 在收到上游消息之后且在发送到下游之前缓存的消息条数。
Reconnect delay (reconnect-delay) : Federation link 由于某种原因断开之后, 需要等待多少秒开始重新建立连接
Acknowledgement Mode (ack-mode):定义 Federation link 的消息确认方式。共 有 3 种:on-confirm、on-publish、no-ack。
默认为 on-confirm,表不在接收 到下游的确认消息(等待下游的Basic.Ack)之后再向上游发送消息确认,这个选项 可以确保网 络失败或者Broker宕机时不会丢失消息,但也是处理速度最慢的选项。
如 果设置为on-publish,则表示消息发送到下游后(并需要等待下游的Basic.Ack) 再向上游发送消息确认,这个选项可以确保在网 络失败的情况下不会丢失消息,但不能 确保Broker宕机时不会丢失消息。
no-ack表示无须进行消息确认,这个选项处理速 度最快,但也最容易丢失消息。
Trust User-ID (trust-user-id>:设定 Federation 是否使用 “ValidatedUser-ID” 这 个功能。如果设置为false或者没有设置,那么Federation会忽略消息的user_id这个属 性;如果设置为true,则 Federation只会转发user_id为上游任意有效的用户的消息。
Exchange (exchange):指定 upstream exchange 的名称,默认情况下和 federated exchange 同名,即图 8-2 中的 exchange A。
Max hops (max-hops):指定消息被丢弃前在Federation link中最大的跳转次数。默 认为1。注意即使设置max-hops参数为大于1的值,同一条消息也不会在同一个Broker 中出现2次,但是有可能会在多个节点中被复制。
Expires (expires):指定 Federationlink 断开之后,federated queue 所对应的upstream queue(即图 8-2 中的队列“federation: exchangeA—broker3 B”)的超时时间,默认为‘none”, 表示为不删除,单位为ms。这个参数相当于设置普通队列的x-expires参数。设置 这个值可以避免Federation link断开之后,生产者一直在向brokerl中的exchangeA发 送消息,这些消息又不能被转发到broker3中而被消费掉,进而造成brokerl中有大量 的消息堆积。
Message TTL (message-ttl):为 federated queue所对应的 upstream queue (即图8-2中的队列“ federation: exchangeA — broker3 B ”)设置,相当于普通队列的 x-message-ttl参数。默认为“none”,表示消息没有超时时间。
HA policy (ha - policy):为 federated queue 所对应的 upstream queue (即图 8-2 中 的队列 “federation: exchangeA—broker3B”)设置,相当于普通队列的 x-ha-policy 参数,默认为“none”,表示队列没有任何HA。
Queue (queue):执行upstream queue的名称,默认情况下和federated queue同名,可以 参考图8-10中的queue。
(第三步)
定义一个Policy用于匹配交换器exchangeA,并使用第二步中所创建的upstream。
第一种是通过rabbitmqctl工具的方式
第二种是通过HTTP API接口的方式
第三种是通过在Web管理界面中添加的方式,在“Admin”一 “Policies”一 “Add/update a policy”中创建
通情况下,针对每个upstream都会有一条Federation link,该Federation link对应到一 个交换器上。例如,3个交换器与2个upstream分别建立Federation link的情况下,会有6条连接。
2.2 Shovel
与Federation具备的数据转发功能类似,Shovel能够可靠、持续地从一个Broker中的队列 (作为源端,即source)拉取数据并转发至另一个Broker中的交换器(作为目的端,即destination)。 作为源端的队列和作为目的端的交换器可以同时位于同一个Broker上,也可以位于不同的 Broker上。Shovel可以翻译为“铲子”,是一种比较形象的比喻,这个“铲子”可以将消息从一 方“挖到”另一方。Shovel的行为就像优秀的客户端应用程序能够负责连接源和目的地、负责 消息的读写及负责连接失败问题的处理。
Shovel的主要优势在于:
松藕合:Shovel可以移动位于不同管理域中的Broker(或者集群)上的消息,这些Broker (或者集群河以包含不同的用户和vhost,也可以使用不同的RabbitMQ和Erlang版本。
支持广域网:Shovel插件同样基于AMQP协议在Broker之间进行通信,被设计成可以 容忍时断时续的连通情形,并且能够保证消息的可靠性。
高度定制:当Shovel成功连接后,可以对其进行配置以执行相关的AMQP命令。
2.2.1 Shovel 的原理
图8-15展示的是Shovel的结构示意图。这里一共有两个Broker:brokerl(IP地址:192.168.0.2) 和broker2 (IP地址:192.168.0.3)。brokerl中有交换器exchangel和队列queuel,且这两者通 过路由键“rkl”进行绑定;broker2中有交换器exchange2和队列queue2,且这两者通过路由键 “rk2”进行绑定。在队列queuel和交换器exchange2之间配置一个Shovel link,当一条内容为 “shovel test payload”的消息从客户端发送至交换器exchangel的时候,这条消息会经过图8-15 中的数据流转最后存储在队列queue2中。如果在配置Shovel link时设置了 add_forward_headers参数为true,则在消费到队列queue2中这条消息的时候会有特殊的 headers属性标记,详细内容可参考图8-16。


通常情况下,使用Shovel时配置队列作为源端,交换器作为目的端,就如图8-15 —样。同样可以将队列配置为目的端,如图8-17所示。虽然看起来队列queuel是通过Shovel link直 接将消息转发至queUe2的,其实中间也是经由broket的交换器转发,只不过这个交换器是默 认的交换器而已。

如图8-18所示,配置交换器为源端也是可行的。虽然看起来交换器exchangel是通过Shovel link直接将消息转发至exchange2上的,实际上在brokerl中会新建一个队列(名称由RabbitMQ 自定义,比如图 8-18 中的 “amq.gen-ZwolUsoUchY6a7xaPyrZZH”)并绑定 exchangel,消息从 交换器exchangel过来先存储在这个队列中,然后Shovel再从这个队列中拉取消息进而转发至 交换器 exchange2。

前面所阐述的 brokerl 和 broker2 中的 exchange1、queue2、exchange2 及 queue2 都可以在 Shovel成功连接源端或者目的端Broker之后再第一次创建(执行一系列相应的AMQP配置声 明时),它们并不一定需要在Shovel link建立之前创建。Shovel可以为源端或者目的端配置多个Broker的地址,这样可以使得源端或者目的端的Broker失效后能够尝试重连到其他Broker 之上(随机挑选)。可以设置recormect+delay参数以避免由于重连行为导致的网络泛洪, 或者可以在重连失败后直接停止连接。针对源端和目的端的所有配置声明会在重连成功之后被重新发送。
2.2.2 Shovel 的使用
Shovel既可以部署在源端,也可以部署在目的端。有两种方式可以部署Shovel:静态方式(static)和动态方式(dynamic)。静态方式是指在rabbitmq.config配置文件中设置,而动 态方式是指通过Runtime Parameter设置。
静态方式:
在rabbitmq. conf ig配置文件中针对Shovel插件的配置信息是一种Erlang项式,由单条Shovel条目构成(shovels部分的下一层)
每一条Shovel条目定义了源端与目的端的转发关系,其名称(shovel_name)必须是独一 无二的。每一条Shovel的定义都像下面这样:
其中sources、destination和queue这三项是必需的,其余的都可以默认
sources和destinations两者都包含了同样类型的配置:
sources中broker项配置的是URI,定义了用于连接Shovel两端的服务器地址、用户名、密 码、vhost和端口号等。如果sources或者destinations是RabbitMQ集群,那么就使用 brokers,并在其后用多个URI字符串以“[]”的形式包裹起来,比如{brokers, ["amqp:// root: root 12 3@192.168.0.2:5672", ’’amqp: / /root: root 12 3@ 192.168.0.4:5 672’’] }, 这样的定义能够使得Shovel在主节点故障时转移到另一个集群节点上。
sources中declarations这一项是可选的,declaration_list指定了可以使用的AMQP命令的 列表,声明了队列、交换器和绑定关系。比如代码清单8-1中sources的declarations这一项 声明了队列 queuel( 'queue.declare')交换器 exchangel( 'exchange.declare')及 其之间的绑定关系(queue.bind )〇注意其中所有的字符串并不是简单地用引号标注,而是同 时用双尖括号包裹,比如《"queue1》。这里的双尖括号是要让Erlang程序不要将其视为简单 的字符串,而是binary类型的字符串。如果没有双尖括号包裹,那么Shovel在启动的时候就会出错。 与queuel —起的还有一个durable参数,它不需要像其他参数一样需要包裹在大括号内,这是因 为像durable这种类型的参数不需要赋值,它要么存在,要么不存在,只有在参数需要赋值的时 候才需要加上大括号。
与sources和destinations同级的queue表不源端服务器上的队列名称。可以将 queue设置为“<<>>”,表示匿名队列(队列名称由RabbitMQ自动生成,参考图8-18中brokerl 的队列)。
prefetch_count参数表不Shovel内部缓存的消息条数,可以参考Federation的相关参 数。Shovel的内部缓存是源端服务器和目的端服务器之间的中间缓存部分,可以参考7.4.2节的 RabbitMQ ForwardMaker。
ack_mode表示在完成转发消息时的确认模式,和Federation的ack_mode —样也有三种 取值:no_ack表示无须任何消息确认行为;on_publish表示Shovel会把每一条消息发送到 目的端之后再向源端发送消息确认;on_confirm表示Shovel会使用publisher confirm机制, 在收到目的端的消息确认之后再向源端发送消息确认。Shovel的ack_mode默认也是 〇n_C〇nfirm,并且官方强烈建议使用该值。如果选择使用其他值,整体性能虽然会有略微提 升,但是发生各种失效问题的情况时,消息的可靠性得不到保障。
publish_properties是指消息发往目的端时需要特别设置的属性列表。默认情况下, 被转发的消息的各个属性是被保留的,但是如果在piablish_Pr〇Perties中对属性进行了设 置则可以覆盖原先的属性值。publish_properties的属性列表包括content_type、 content—encoding、headers、delivery_mode、priority 、correlation_id、 reply_to、expiration、message_id、timestamp、type、user_id、 app_id 和 cluster_id。
add_forward_headers如果设置为true,则会在转发的消息内添加x-shovelled的 header属性
publish_fields定义了消息需要发往目的端服务器上的交换器以及标记在消息上的路 由键。如果交换器和路由键没有定义,则Shovel会从原始消息上复制这些被忽略的设置。
reconnect_delay指定在Shovel link失效的情况下,重新建立连接前需要等待的时间, 单位为秒。如果设置为0,则不会进行重连动作,即Shovel会在首次连接失效时停止工作。 reconnect一delay 默认为 5 秒。
动态方式:
与Federation upstream类似,Shovel动态部署方式的配置信息会被保存到RabbitMQ的 Mnesia数据库中,包括权限信息、用户信息和队列信息等内容。每一个Shovel link都由一个相 应的Parameter定义,这个Parameter同样可以通过rabbitmqctl工具、RabbitMQ Management 插件的 HTTP API 接口或者 rabbitmq_shovel_management 提供的 Web 管理 界面的方式设置。
第一种是通过rabbitmqctl工具的方式
第二种是通过调用HTTP API接口的方式
第三种是通过Web管理界面中添加的方式,在“Admin” 一 “Shovel Management” 一 “Add a new shovel”中创建
在创建了一个Shovel link之后,可以在Web管理界面中“Admin” 一 “Shovel Status”中查看到相应的信息,也可以通过 rabbitmqctl eval 'rabbit_shovel_status:status()' 命令直接查询Shovel的状态信息,该命令会调用rabbitmq_shovel插件模块中的status方法, 该方法将返回一个Erlang列表,其中每一个元素对应一个己配置好的Shovel。列表中的每一个元素都以一个四元组的形式构成:{Name, Type, Status, Timestamp}。具体含义如下:
Name:表示Shovel的名称。
Type:表示类型,有2种取值 static和dynamic。
Status:表示目前Shovel的状态。当Shovel处于启动、连接和创建资源时状态为 starting;当 Shovel 正常运行时是 running;当 Shovel 终止时是 terminated。
Timestamp:表示该Shovel进入当前状态的时间戳,具体格式是{{YYYY, MM, DD}, {HH, MM, SS}}
2.2.3案例:消息堆积的治理
消息堆积是在使用消息中间件过程中遇到的最正常不过的事情。消息堆积是一把双刃剑,适 量的堆积可以有削峰、缓存之用,但是如果堆积过于严重,那么就可能影响到其他队列的使用, 导致整体服务质量的下降。对于一台普通的服务器来说,在一个队列中堆积1万至10万条消息, 丝毫不会影响什么。但是如果这个队列中堆积超过1千万乃至一亿条消息时,可能会引起一些严 重的问题,比如引起内存或者磁盘告瞥而造成所有Connection阻塞.
消息堆积严重时,可以选择清空队列,或者采用空消费程序丢弃掉部分消息。不过对于重 要的数据而言,丢弃消息的方案并无用武之地。另一种方案是增加下游消费者的消费能力,这 个思路可以通过后期优化代码逻辑或者增加消费者的实例数来实现。但是后期的代码优化在面 临紧急情况时总归是“远水解不了近渴”,并且有些业务场景也并非可以简单地通过增加消费实 例而得以增强消费能力。

在一筹莫展之时,不如试一下Shovel。当某个队列中的消息堆积严重时,比如超过某个设 定的阈值,就可以通过Shovel将队列中的消息移交给另一个集群。
三、网络分区
网络分区是在使用RabbitMQ时所不得不面对的一个问题,网络分区的发生可能会引起消 息丢失或者服务不可用等。
3.1 网络分区的意义
RabbitMQ集群的网络分区的容错性并不是很高,一般都是使用Federation或者Shovel来解决广域网中的使用问题。不过即使是在局域网环境下,网络分区也不可能完全避免,网络 设备(比如中继设备、网卡)出现故障也会导致网络分区。当出现网络分区时,不同分区里 的节点会认为不属于自身所在分区的节点都己经挂(down) 了,对于队列、交换器、绑定的 操作仅对当前分区有效。在RabbitMQ的默认配置下,即使网络恢复了也不会自动处理网络分 区带来的问题。
当一个集群发生网络分区时,这个集群会分成两个部分或者更多,它们各自为政,互相都 认为对方分区内的节点己经挂了,包括队列、交换器及绑定等元数据的创建和销毁都处于自身 分区内,与其他分区无关。如果原集群中配置了镜像队列,而这个镜像队列又牵涉两个或者更 多个网络分区中的节点时,每一个网络分区中都会出现一个master节点,对于各个网络分区, 此队列都是相互独立的。当然也会有一些其他未知的、怪异的事情发生。当网络恢复时,网络分区的状态还是会保持,除非你采取了一些措施去解决它。
网络分区带来的影响大多是负面 的,极端情况下不仅会造成数据丢失,还会影响服务的可用性。
某队列配置了 4个镜像,其中A节点作为master节点,其余B、C和D节点 作为slave节点,4个镜像节点组成一个环形结构。假如需要确认(ack) —条消息,先会在A 节点即master节点上执行确认命令,之后转向B节点,然后是C和D节点,最后由D将执行 操作返回给A节点,这样才真正确认了一条消息,之后才可以继续相应的处理。这种复制原理 和ZooKeeper1的Quorum 原理不同,它可以保证更强的一致性。在这种一致性数据模型下,如 果出现网络波动或者网络故障等异常情况,那么整个数据链的性能就会大大降低。如果C节点 网络异常,那么整个A—B—C—D—A的数据链就会被阻塞,继而相关服务也会被阻塞,所以 这里就需要引入网络分区来将异常的节点剥离出整个分区,以确保RabbitMQ服务的可用性及 可靠性。等待网络恢复之后,可以进行相应的处理来将此前的异常节点加入集群中。

许多 情况下,网络分区都是由单个节点的网络故障引起的,且通常会形成一个大分区和一个单节点 的分区,如果之前又配置了镜像,那么可以在不影响服务可用性,不丢失消息的情况下从网络分区的情形下得以恢复。
3.2 网络分区的判定
RabbitMQ集群节点内部通信端口默认为25672,两两节点之间都会有信息交互。如果某节点出现网络故障,或者是端口不通,则会致使与此节点的交互出现中断,这里就会有个超时判 定机制,继而判定网络分区。
对于网络分区的判定是与net_tiCktime这个参数息息相关的,此参数默认值为60秒。 注意与heartbeat_time的区别,heartbeat_time是指客户端与RabbitMQ服务之间通信 的心跳时间,针对5672端口而言。如果发生超时则会有net_tick_timeout的信息报出。在 RabbitMQ集群内部的每个节点之间会每隔四分之一的net_ticktime—次应答(tick)。如 果有任何数据被写入节点中,则此节点被认为已经被应答(ticked) 了。如果连续4次,某节点 都没有被ticked,则可以判定此节点已处于“down”状态,其余节点可以将此节点剥离出当前分区。
RabbitMQ不仅会将队列、交换器及绑定等信息存储在Mnesia数据库中,而且许多围绕网 络分区的一些细节也都和这个Mnesia的行为相关。如果一个节点不能在t时间连上另一个节点, 那么Mnesia通常认为这个节点已经挂了,就算之后两个节点又重新恢复了内部通信,但是这两 个节点都会认为对方己经挂了,Mnesia此时认定了发生网络分区的情况。这些会被记录到 RabbitMQ的服务日志之中.
除了通过查看RabbitMQ服务日志的方式,还有以下3种方法可以查看是否出现网络分区。
第一种,采用rabbitmqctl工具来查看,即采用rabbitmqctl cluster_status命令。
第二种,通过Web管理界面的方式查看。
第三种,通过HTTP APi的方式调取节点信息来检测是否发生网络分区。比如通过curl命令来调取节点信息:














 1344
1344











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









