







count(*) 和 count(1)和count(列名)区别
执行效果上:
- count(*)包括了所有的列,相当于行数,在统计结果的时候,不会忽略列值为NULL
- count(1)包括了所有列,用1代表代码行,在统计结果的时候,不会忽略列值为NULL
- count(列名)只包括列名那一列,在统计结果的时候,会忽略列值为空(这里的空不是只空字符串或者0,而是表示null)的计数,即某个字段值为NULL时,不统计
执行效率上:
- 列名为主键,count(列名)会比count(1)快
- 列名不为主键,count(1)会比count(列名)快
- 如果表多个列并且没有主键,则 count(1) 的执行效率优于 count(*)
- 如果有主键,则 select count(主键)的执行效率是最优的
- 如果表只有一个字段,则 select count(*) 最优
MySQL中 in和 exists 的区别?
- exists:exists对外表用loop逐条查询,每次查询都会查看exists的条件语句,当exists里的条件语句能够返回记录行时(无论记录行是的多少,只要能返回),条件就为真,返回当前loop到的这条记录;反之,如果exists里的条件语句不能返回记录行,则当前loop到的这条记录被丢弃,exists的条件就像一个bool条件,当能返回结果集则为true,不能返回结果集则为false
- in:in查询相当于多个or条件的叠加
SELECT * FROM A WHERE A.id IN (SELECT id FROM B);
SELECT * FROM A WHERE EXISTS (SELECT * from B WHERE B.id = A.id);
如果查询的两个表大小相当,那么用in和exists差别不大。
如果两个表中一个较小,一个是大表,则子查询表大的用exists,子查询表小的用in
UNION和UNION ALL的区别?
UNION和UNION ALL都是将两个结果集合并为一个,两个要联合的SQL语句 字段个数必须一样,而且字段类型要“相容”(一致)
- UNION在进行表连接后会筛选掉重复的数据记录(效率较低),而UNION ALL则不会去掉重复的数据记录;
- UNION会按照字段的顺序进行排序,而UNION ALL只是简单的将两个结果合并就返回;
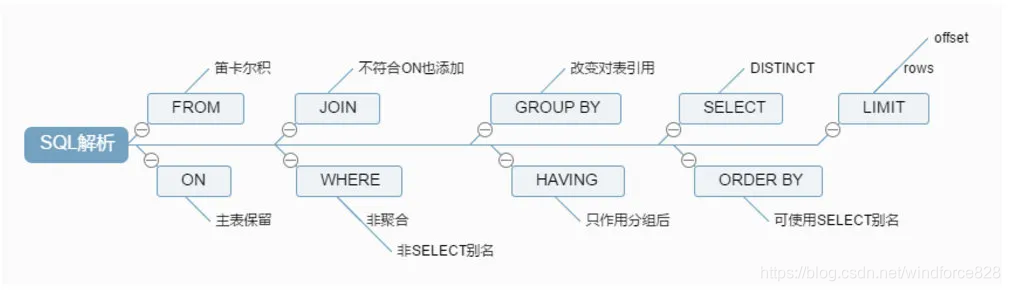
SQL执行顺序
- 手写
SELECT DISTINCT <select_list>
FROM <left_table> <join_type>
JOIN <right_table> ON <join_condition>
WHERE <where_condition>
GROUP BY <group_by_list>
HAVING <having_condition>
ORDER BY <order_by_condition>
LIMIT <limit_number>
- 机读
FROM <left_table>
ON <join_condition>
<join_type> JOIN <right_table>
WHERE <where_condition>
GROUP BY <group_by_list>
HAVING <having_condition>
SELECT
DISTINCT <select_list>
ORDER BY <order_by_condition>
LIMIT <limit_number>
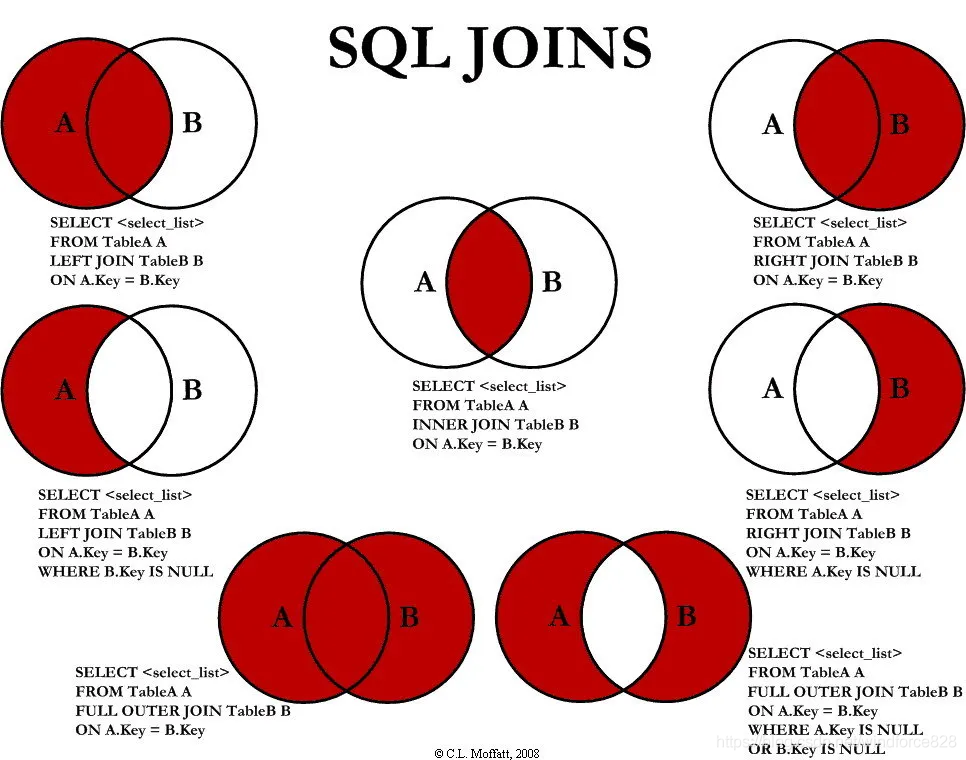
mysql 的内连接、左连接、右连接有什么区别?
什么是内连接、外连接、交叉连接、笛卡尔积呢?
Join图















 7242
7242











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









