







问题描述
截至目前,PyTorch中有一个潜在的不合理之处,即pytorch优化器中的正则化会将所有可训练参数都进行正则化,而理论上,偏置(bias)是没有必要进行正则化的(反而会限制模型的能力)。以Adam优化器为例,我们在模型的训练开始之前,一般会这样定义优化器:
optimizer = torch.optim.Adam(net.parameters(), lr=0.01, weight_decay=0.0001)
其中weight_decay为正则化项的系数。如上定义,模型在训练时,模型的所有参数(即net.parameters())都将被正则化,而我们希望其中的偏置(bias)不要被正则化。怎么办?
解决方案
pytorch的torch.optim.Adam的第一个参数接受一个可学习参数的迭代器(或列表),同时还可以是字典。如下
optimizer = torch.optim.Adam([
{'params': net.layer.weight, 'weight_decay': 0.0001},
{'params': net.layer.bias}
], lr=0.01)
如上指定了可学习参数net.layer.bias(这是网络中的一个偏置参数)的学习率lr为0.01,weight_decay为0(也就是没有正则化项)。
对于非常简单的模型,我们可以手动把可学习参数写成如上代码中的字典形式,但对于比较复杂的模型很难手动一个一个的分离出来。通过分析发现,对于比较复杂的模型,其中所有的偏置参数的名字中都含有子串"bias",如下测试:
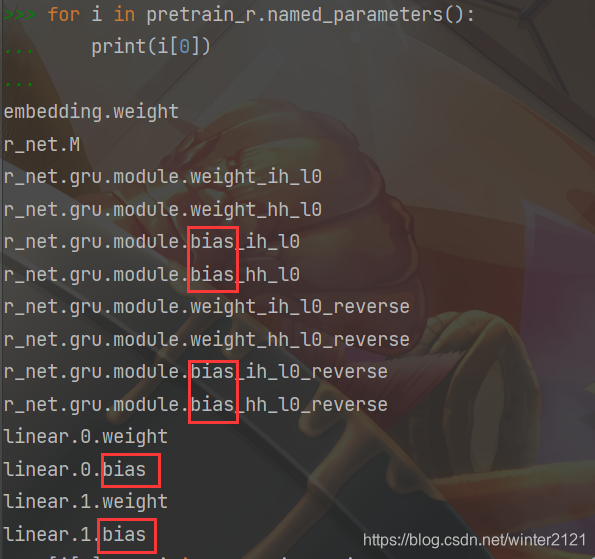
其中named_parameters()函数可以获取当前模型中所有的参数(含不可训练的参数)。于是,我们可以这样分离出偏置参数:
bias_list = (p for name, p in net.named_parameters() if 'bias' in name)
注意细节,这里用的是圆括号()而不是[],因为[]默认是列表,会主动进行一次遍历并返回这个列表,而()返回值为迭代器,只有当被动的迭代它时它才会去计算。话句话说就是[]复杂度高一倍。
最终,我们的优化器如下定义即可实现仅weight正则化而bias取消正则化:
optimizer = torch.optim.Adam([
{'params': (p for name, p in net.named_parameters() if 'bias' not in name), 'weight_decay': 0.0001},
{'params': (p for name, p in net.named_parameters() if 'bias' in name)}
], lr=0.01)















 639
639











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











