






【引子】本文根据《实时分析实战》一书的第3章提炼而成,旨在通过一个具体案例来了解实时流分析面对的具体场景以及潜在的技术实现。

我们将深入探讨一家名为“All About That Dough”(简称AATD)的比萨外卖企业,该企业致力于提供融合印度风味的比萨配送服务。AATD已历经近二十载的风雨,成功打造了一个能够承受每分钟数千次点击并处理高达50个订单的网络平台基础设施。
AATD的业务涉及三种核心数据类型:产品、用户以及订单。起初,公司依赖传统的关系型数据库来管理所有这些数据。然而,几年前,他们引入了流处理技术,以更有效地管理订单数据流。
所有通过流处理平台处理的数据都会进行批处理,每小时整理一次,并被同步到数据仓库中。在这个数据仓库里,每晚都会执行分析查询,以便审视当日的运营状况。除此之外,AATD还保存了网站的全部访问日志,但迄今为止,这些数据尚未被用于任何分析或操作。
尽管AATD在业务扩展方面取得了显著成就,但是一些反复出现的问题却成为了公司发展的绊脚石:
l公司偶尔会遇到欺诈或恶意订单,但这些订单往往在处理开始或甚至完成后几天才被发现。
l库存管理颇具挑战,因为公司难以准确预测特定时段内哪些产品更受客户青睐。例如,由于某些比萨系列的订单量突增,公司曾多次面临原料短缺的困境。
l顾客们经常反映无法知晓订单何时能够送达,他们渴望能够实时跟踪订单状态。
面对这些挑战,希望改进应用架构以解决部分或全部现存问题,同时希望采用开源解决方案,以避免对单一供应商产生过度依赖。
3.1 现有架构
AATD现有的数据基础设施如图3-1所示。
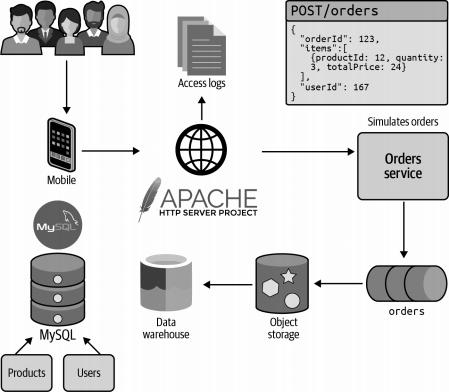
图3-1. AATD的现有架构
尽管图3-1展示了对象存储和数据仓库的概念,但这些主题并不在本书的讨论范围之内。AATD可继续依赖其现行的数据仓库方案,以便对历史数据进行深入分析。
现在,让我们从用户向Web服务器发起请求的动作着手,进而探讨该架构的其他组成部分,正如图3-2所展示的那样。
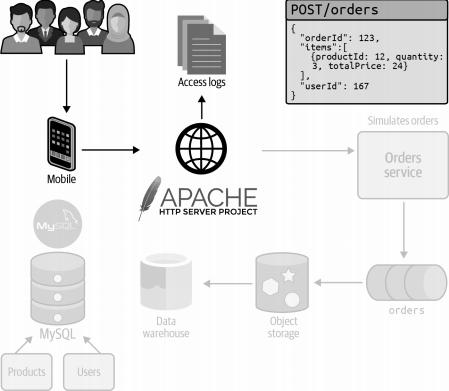
图3-2. 用户发出web请求
当用户通过移动设备浏览AATD的网站时,他们产生的每个页面请求都会被系统自动记录并保存至访问日志文件中。若用户进行订单提交,则会发送一个封装了订单详细内容的POST请求。
接着,这个订单请求会被转发至订单处理服务,正如图3-3所描绘的那样。在该服务中,订单会经过一系列的验证逻辑检验。一旦验证无误,订单便会被推送至事件流处理平台,以便进一步的处理和分析。
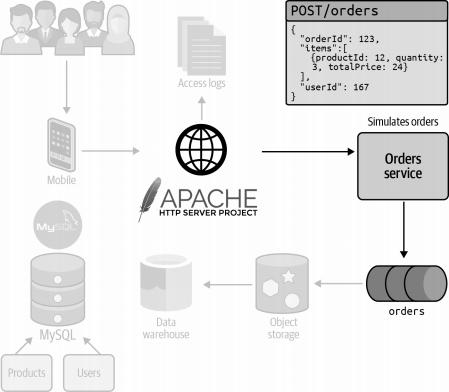
图 3-3. 订单被发送到订单服务
最终,我们还需引入一个MySQL数据库,如图3-4所示,该数据库承担着记录用户信息与产品数据的重要角色。
这些关键数据由AATD的后端服务所调用,而这些服务并不属于数据分析基础设施的一环,因此它们也将不在本书的讨论范畴之内。
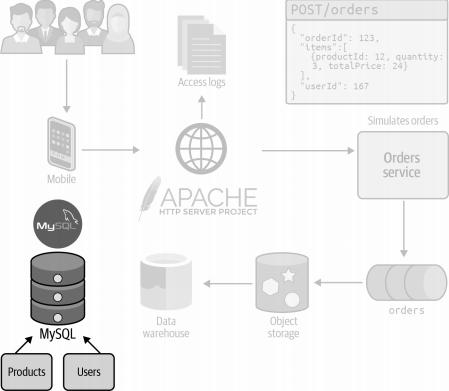
图3-4. 用户和产品信息存储在MySQL中
3.2 设置
本书有一个配套的GitHub代码仓库(https://oreil.ly/RTA-github) ,其中包含了每个章节所使用的代码。如果您是Git用户,可以通过运行以下命令将该代码仓库克隆到本地:
git clone git@github.com:mneedham/real-time-analytics-book.git
cd real-time-analytics-book
如果您不是Git用户,仍然可以通过下面的命令下载包含所有示例的ZIP文件:
wget github.com/mneedham/real-time-analytics-book/archive/refs/heads/main.zip
unzip main.zip
我们将使用Docker来运行该应用程序的所有组件。Docker Compose文件位于代码仓库的根目录,并带有docker-compose前缀。下面,我们将逐一介绍每个组件。
3.2.1 MySQL
MySQL诞生于1995年,作为一款广受欢迎的开源关系数据库管理系统,它以其用户友好性、系统健壮性以及可靠性而著称。
该数据库将信息存储在表格(亦称作关系)中,在进行数据检索时,可以依托这些键来联接不同的表。我们借助SQL语言执行查询操作,它是处理关系型数据库的行业标准语言。
无论是面向小型项目,还是服务于大型的企业级系统,MySQL都是众多应用程序和场景的优选数据库解决方案。在本项目中,我们也将利用MySQL来保管产品和用户的相关信息。
服务配置如示例3-1所示。
示例3-1. docker-compose-base.yml—MySQL
mysql:
image: mysql/mysql-server:8.0.27
hostname: mysql
container_name: mysql
ports:
- 3306:3306
environment:
- MYSQL_ROOT_PASSWORD=debezium
- MYSQL_USER=mysqluser
- MYSQL_PASSWORD=mysqlpw
volumes:
- ${PWD}/mysql/mysql.cnf:/etc/mysql/conf.d
- ${PWD}/mysql/mysql_boots.sql:/docker-entrypoint-initdb.d/mysql_bootstrap.sql
- ${PWD}/mysql/data:/var/lib/mysql-files/data
数据库的data schema如图3-5所示。
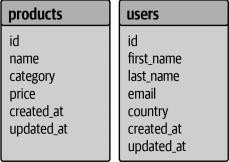
图3-5. MySQL的数据模式
创建这些表的SQL命令被包含在创建容器时运行的引导文件(/docker-entry point-initdb . d/MySQL_bootstrap.SQL)中。让我们仔细看下该引导文件的内容。
首先,我们要创建数据库pizzashop(如果尚不存在),并将权限授予mysqluser:
CREATE DATABASE IF NOT EXISTS pizzashop;
USE pizzashop;
GRANT ALL PRIVILEGES ON pizzashop.* TO 'mysqluser';
GRANT FILE on *.* to 'mysqluser';
FLUSH PRIVILEGES;
接下来,创建用户表(users):
CREATE TABLE IF NOT EXISTS pizzashop.users
(
id SERIAL PRIMARY KEY,
first_name VARCHAR(255),
last_name VARCHAR(255),
email VARCHAR(255),
country VARCHAR(255),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);
以及产品表(products):
CREATE TABLE IF NOT EXISTS pizzashop.products
(
id SERIAL PRIMARY KEY,
name VARCHAR(100),
description VARCHAR(500),
category VARCHAR(100),
price FLOAT,
image VARCHAR(200),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);
最后,我们将使用/var/lib/mysql-files/data/users.csv中的内容填充用户表,其示例如表3-1所示。
表 3-1. 用户表(users)示例

导入用户信息的代码如下所示:
LOAD DATA INFILE '/var/lib/mysql-files/data/users.csv'
INTO TABLE pizzashop.users
FIELDS TERMINATED BY ','
OPTIONALLY ENCLOSED BY '"'
IGNORE 1 LINES
(first_name,last_name,email,country);
产品表(products)将使用/var/lib/mysql-files/data/products.csv中的内容来进行填充,其示例如表 3-2 所示。
表3-2. 产品表(products)示例
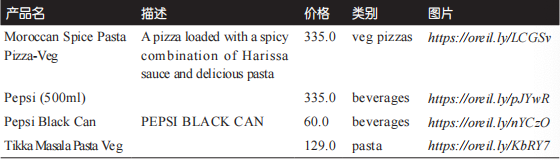
导入产品信息的代码如下所示:
LOAD DATA INFILE '/var/lib/mysql-files/data/products.csv'
INTO TABLE pizzashop.products
FIELDS TERMINATED BY ','
OPTIONALLY ENCLOSED BY '"'
IGNORE 1 LINES
(name,description,price,category,image);
3.2.2 Apache Kafka
Apache Kafka作为我们的事件流处理平台,已被众多组织采纳,以高效地处理大规模实时数据流。它提供了高数据吞吐率和低延迟的处理能力,因而在那些对数据处理速度和可靠性有着苛刻要求的应用场景中,成为了首选技术。
Kafka的分布式架构优雅地支持多源数据的生产者和消费者,使得它能够构建出既复杂又可扩展的数据流水线。此外,借助Kafka Connect,它可以无缝地与各种系统和应用程序集成,极大地增强了其灵活性和实用性。无疑,Kafka是构建当代数据驱动应用最受欢迎的解决方案之一。
通过订单服务,来自网站的订单可以被有效地发布到Kafka。该服务的设置和配置细节,正如示例3-2所展示的那样。
示例3-2. docker-compose-base.yml—Kafka
kafka:
image: confluentinc/cp-kafka:7.1.0
hostname: kafka
container_name: kafka
ports:
- "29092:29092"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP:
PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS:
PLAINTEXT://kafka:9092,PLAINTEXT_HOST://localhost:29092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_TOOLS_LOG4J_LOGLEVEL: ERROR
depends_on:
[zookeeper]
3.2.3 ZooKeeper
Apache ZooKeeper作为一项分布式协调服务,已成为众多分布式系统不可或缺的核心组件。它提供了一个高度可用的分层式键值存储方案,适用于存放配置数据、管理领导者选举以及作为消息队列等功能。
得益于其强大且稳健的基础架构,ZooKeeper为打造可扩展的分布式系统奠定了坚实可靠的基础。在本项目里,我们将利用ZooKeeper来监控Kafka集群中各节点的状态,并维护Kafka主题与消息队列的清单。
关于该服务的配置细节,示例3-3提供了详尽的展示。
示例3-3. docker-compose-base.yml—ZooKeeper
zookeeper:
image: zookeeper:latest
hostname: zookeeper
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOO_MY_ID: 1
ZOO_PORT: 2181
ZOO_SERVERS: server.1=zookeeper:2888:3888;2181
3.2.4 订单服务
订单服务每秒钟将多个订单发布到Kafka中的订单主题。该主题中的事件结构如下所示:
{
"id":"string",
"createdAt":"string",
"userId":"integer",
"price":"double",
"status":"string",
"items": [
{
"productId": "string",
"quantity": "integer",
"price": double
}
]
}
该服务的配置如示例3-4所示。
示例3-4. docker-compose-base.yml—orders service
orders-service:
build: orders-service
container_name: orders-service
depends_on:
- mysql
- kafka
这是一个包含数据模拟器的自定义Docker镜像。我们不会在书中详细介绍数据模拟器,但您可以在本书的GitHub代码仓库中找到数据模拟器的代码(https://oreil.ly/z5YIL)。
3.2.5 启动组件
我们可以通过运行以下命令来启动所有这些组件:
docker-compose -f docker-compose-base.yml up
完成此操作后,我们将运行Kafka、MySQL和ZooKeeper的实例。订单服务也将被启动,并向Kafka 填充订单数据,向MySQL填充用户数据和产品数据。
3.3检查数据
让我们从MySQL表开始,看一下AATD数据的子集。我们可以通过CLI连接到MySQL,具体命令如下所示:
docker exec -it mysql mysql -u mysqluser -p
输入密码mysqlpw,然后可以看到mysql的提示语:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 5902
Server version: 8.0.27 MySQL Community Server - GPL
Copyright (c) 2000, 2021, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
我们可以使用以下查询命令来查询产品表:
SELECT count(*) FROM pizzashop.products;
该查询命令的执行结果如表3-3所示。
表3-3. 产品数量

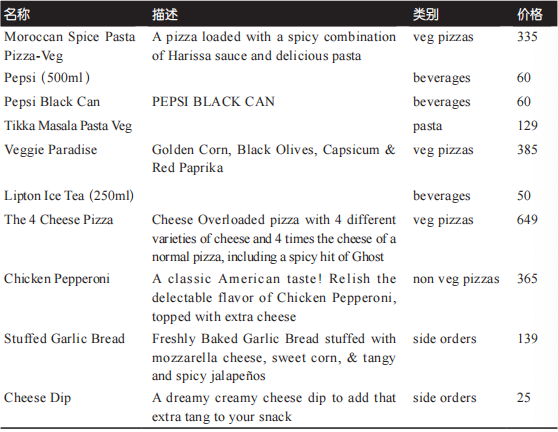
这里有81种不同的产品,让我们选择一些产品来进行查看:
SELECT name, description, category, price
FROM pizzashop.products
LIMIT 10;
该查询命令的执行结果如表3-4所示。
表3-4. 前10个产品
我们可以编写类似的查询命令来查询用户信息:
SELECT id, first_name, last_name, email, country
FROM pizzashop.users
LIMIT 10;
该查询命令的执行结果如表3-5所示。
表3-5. 前10个用户

至此,所有数据已成功且准确地加载完毕。
在执行这些查询命令的过程中,如果未返回任何记录,那通常意味着在数据导入时可能发生了错误。此时,我们可以通过检查Docker日志中的错误信息来进行问题诊断。
接下来,让我们转向Apache Kafka中的数据检验。我们可以借助kcat命令行工具(https://oreil.ly/hb-9y)来实施这一操作。关于kcat,Confluence文档提供了以下描述:
“kcat是一个专为测试和调试Apache Kafka部署而设计的命令行程序。通过kcat,我们能够生成、消费以及罗列Kafka的主题和分区信息。因其强大的功能,kcat被誉为“Kafka界的netcat”,是一把在Kafka环境下检视与构造数据的瑞士军刀。”
我们使用以下命令调用kcat:
kcat -C -b localhost:29092 -t orders -c 1
默认情况下,只要事件还在产生,该命令就会不断地返回事件,但为了简洁起见,我们将其限制为仅返回一条消息。运行该命令后,你会看到类似于示例3-5的输出。
示例3-5. 订单(orders)流中的一条消息
{
"id": "c6745d1f-cecb-4aa8-993b-6dea64d06f52",
"createdAt": "2022-09-06T10:46:17.703283",
"userId": 416,
"status": "PLACED_ORDER",
"price": 1040,
"items": [
{
"productId": "21",
"quantity": 2,
"price": 45
},
{
"productId": "36",
"quantity": 3,
"price": 60
},
{
"productId": "72",
"quantity": 2,
"price": 385
}
]
}
订单的产生似乎正如我们所预期的那样持续进行。从数据中我们可以观察到,每个事件都由事件ID、用户ID、订单状态、下单时间以及一个包含订单详情的数组构成。
若在订单主题下没有任何新事件生成,那么相关命令将会处于等待状态,并且终端上也不会显示任何输出信息。这一现象通常预示着订单服务可能存在一些问题,这时我们就需要通过检查Docker日志来定位并解决问题。
至此,我们已经完整地审视了AATD现有架构的所有组成部分,这些都在图3-6中得到了清晰的展示。
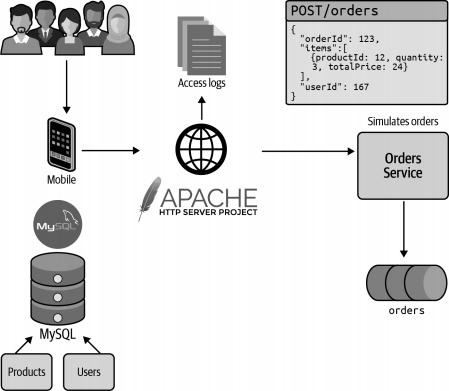
图3-6. 现有架构
既然我们已经完成了现有架构的配置,那么是时候考虑如何基于这些数据实现实时分析应用程序了。
3.4 实时分析的应用
接下来,我们将探索如何集成实时分析功能。以AATD为业务案例,我们打算实施实时分析,同时针对第9页所述的“实时分析应用分类”中的各个象限进行具体阐述。
下面列举了一些潜在的应用程序,通过它们的构建,我们可以解决AATD面临的多种业务挑战:
l针对人员/内部:一个仪表盘应用,展示最新的订单情况、收入数据、已订购产品以及客户满意度等关键指标。这将使得AATD的运营团队能够实时掌握业务动态,并在出现任何问题时迅速响应。
l针对人员/外部:一款允许客户在地图上实时跟踪订单状态和披萨配送时间的Web/移动应用。这为AATD的用户提供了根据订单预计到达时间来安排自己的时刻表,并能够在订单发生异常时即刻得到通知。
l针对机器/内部:基于AATD访问日志构建的异常检测系统,当系统发现非正常的流量模式时,会通过Slack或电邮发送警报。这帮助AATD的网站可靠性工程(SRE)团队确保网站的高可用性,并能够及时识别出拒绝服务攻击(DoS)。
l针对机器/外部:一个用于侦测和拦截欺诈订单的欺诈检测系统。
在本书中,我们会重点讨论面向人的应用程序,而将把面向机器的应用作为读者的实践练习。
3.5 本章小结
在本章内容中,我们向读者介绍了“All About That Dough”(简称AATD),这不仅仅是一家普通的披萨连锁店,而是一家致力于通过实时分析技术来优化业务流程的企业。我们不仅深入了解了AATD的现行技术架构,而且已经在我们的笔记本电脑上成功实现了该架构的部署。
随着本书内容的推进,在接下来的四个章节里,我们将基于现有的技术架构继续深化工作,为前面所述的“实时分析应用程序分类”中提及的四种实时分析场景增添更多必要的组件。我们将在下一章节首先搭建一个内部仪表盘,它能够实现对订单流程的实时跟踪与监控。

【参考资料与关联阅读】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









