






GBase 8a MPP Cluster 存储过程和存储函数
一、概述:
天津南大通用数据技术股份有限公司(以下简称GBASE公司)的GBase 8a MPP Cluster(以下简称 8a 集群)是一款大规模分布式并行处理数据库集群产品。其存储过程非常强大,广泛应用于金融、电信、海关、政企、公安等行业的数仓建设工作。
本章重点主题:
1、存储过程的概念和应用价值。
2、存储过程语法结构和案例。
3、存储过程强大的预处理功能。
4、存储函数的基本语法和案例。
二、实操环境准备
(一)GBase Data Studio 的获取路径:
【百度云盘链接】:https://pan.baidu.com/s/1cI7tIdyCojMku2yjhrWDlw?pwd=ckrf
【一般我们下载的如下文件】:
☆ 8a V95软件安装包\GBaseDataStudio\GBaseDataStudio_9.5.2.0_build7_Windows_x86_64.zip 8a企业管理器 windows 64bit 版本。
【使用】解压此 zip 文件到某目录(名称不能包含汉字或全角字符)下,执行 GBaseDataStudio\GBaseDataStudio.exe 即可打开主界面。
(二)GBase Data Studio 数据源连接信息:
1、单击界面左上角的“新建连接向导”,
2、选择 GBase 8a MPP 然后输入以下信息——
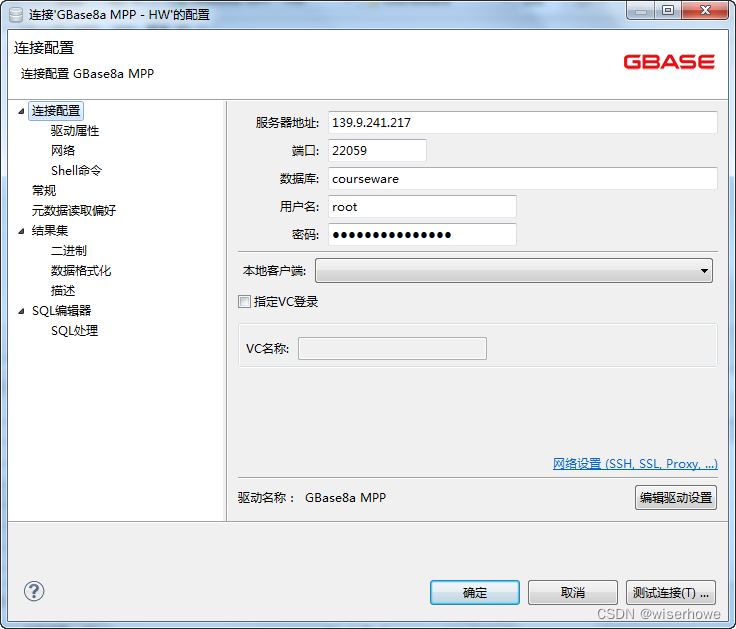
gdcp 密码:gdcp!@
三、存储程序:
(一)基本概念:存储程序是 8a 集群SQL类扩展函数,是存储过程和存储函数的统称。
(二)存储过程和存储函数的区别:
| 存储过程 | 存储函数 | |
|---|---|---|
| 功能 | 完成数据库较复杂的操作 | 针对数据较简单的处理 |
| 创建语句 | CREATE PROCEDURE | CREATE FUNCTION |
| 执行 | 通过CALL语句来执行 | 类似于内置函数 |
| 调用关系 | 存储过程内部可以调用存储函数、过程 | 存储函数内部不能调用存储过程 |
| 应用 | 1、数据加载跑批脚本;2、应用程序通过数据库开发接口调用存储过程 | 1、在SQL语句中当做内置函数使用;2、在存储过程中给变量赋值 |
| 返回值 | 能返回结果集或多个值;不能有 RETURN 语句。 | 只能返回一个值; |
(三)查看存储程序基本信息:
1、查看存储过程或函数的基本信息
show procedure status; #查看所有存储过程
show function status; #查看所有存储函数
2、查询存储过程和函数的基本信息(通过系统表)
SELECT * FROM gbase.proc WHERE NAME = 'proc_Test_out'; #存储过程
SELECT * FROM gbase.proc WHERE NAME = 'fnTestCondition'; #存储函数
3、查看存储过程或函数的创建代码
show create procedure {过程名};
show create function {函数名};
四、存储过程:
(一)存储过程的基本概念:
存储过程 (Stored Procedure) 是一组可以完成特定功能的 SQL 语句和可选控制流语句的预编译集合。存储过程可看做是 SQL 语句集的批处理。存储过程也是一种数据库对象,其名称必须符合标识符命名规则(64字符长,以字符或_开始),在当前数据库中创建,并赋予执行权限。
(二)存储过程的应用价值:
1、跨平台:当多个客户端应用程序是由不同的语言编写,或者运行在不同的平台,这些应用程序共同调用的一组数据库批处理可以封装在存储过程中。
2、模块化:存储过程允许用户在数据库服务器中使用功能丰富的内置函数。通过模块化程序设计封装复杂的业务逻辑、提升代码的复用性,实现应用程序与SQL的解耦。
4、保证数据安全:一般用户不能有数据表读写权限的,通过存储过程即可间接访问数据表的数据。尤其涉密行业的业务系统,数据的安全性至关重要。
5、保证数据完整:相关的业务数据处理动作在存储过程中一起执行,只要发生一个失败,则整个批处理回滚,从而保证数据完整性。
6、低延迟:在 WEB 系统中,存储过程数据库查询性能表现更加明显,因为存储过程在数据库引擎中已经是预编译的,而且服务器和客户端之间网络通讯量比单纯多条SQL操作少很多。请求回馈的低延迟带来的是并发数的提升。
(三)存储程序:
8a集群的存储过程概念是包含在存储程序之内的。存储程序是存储过程和存储函数的统称。
1、查看存储过程
show procedure status; # 列出当前用户能访问到的所有存储过程的基本信息
show create procedure <过程名>; # 列出某存储过程代码
或者通过系统表查看——
SELECT * FROM information_schema.ROUTINES WHERE ROUTINE_NAME = '<过程名>' and ROUTINE_TYPE= 'PROCEDURE'
2、查看存储函数
show function status; # 列出当前用户能访问到的所有存储函数的基本信息
show create function <函数名>; # 列出某存储函数代码
或者通过系统表查看——
SELECT * FROM information_schema.ROUTINES WHERE ROUTINE_NAME =
'<函数名>' and ROUTINE_TYPE= 'FUNCTION'
(四)存储过程的编写步骤:
1、可视化工具:在 GBase Data Studio 新建 SQL 文件;
在SQL文件窗口中可以执行任何SQL语句。
2、存在则删除:便于未来修改程序;
DROP PROCEDURE IF EXISTS pMyProcedure;
在 CREATE PROCEDURE 之前执行这句话,可以将本地保存的存储过程SQL代码的更新到数据库服务端。
3、定义新的限定符:用 DELIMITER 更换限定符,目的是界定存储过程代码的范围;
DELIMITER |
4、功能注释:梳理业务需求,这是接口设计的基础;
5、接口设计:定义输入输出参数及其数据类型、返回值;创建存储过程;
CREATE PROCEDURE pMyProcedure (OUT id char(2), IN bName VARCHAR(10))
6、编码:程序体逻辑设计和编写脚本,使用 BEGIN…END 关键字包围程序体代码;
BEGIN
-- <程序体>
END
7、恢复限定符:存储程序编写完毕后,用“DELIMITER ;”恢复默认的限定符分号。
DELIMITER ;
(五)存储过程的结构、参数类型和调用:
1、存储过程的基本结构
CREATE PROCEDURE <proc_name> (OUT param1 INT, IN param2 VARCHAR(10))
BEGIN
<程序体>
END
2、参数:
- 参数名称前的 IN 关键字表示输入参数;
- 参数名称前的 OUT 关键字表示输出参数;
- 参数名称前的 INOUT 关键字表示输入输出参数;
- 不支持缺省参数。
3、程序体:
(1) 变量的声明、赋值;
(2) SQL 语句:DDL、DML、DQL、DCL;
(3) 流程控制:条件分支和循环;
(4) 游标:静态和动态游标;
(5) 预处理;
(6) 异常处理。
4、存储过程的调用:
CALL <存储过程名字(实际参数列表)>
实参可以是实际的数值,也可以是变量。
5、代码示例:
DELIMITER |
DROP PROCEDURE IF EXISTS proc_Test_out |
/*
功能:根据学生的姓名得到学生的学号
*/
CREATE PROCEDURE proc_Test_out (OUT id INT, IN bName VARCHAR(10))
BEGIN
SELECT `SId` INTO id FROM student WHERE Sname=bName;
END |
DELIMITER ;
###### 存储过程的调用 ######
set @ID = 0; # 初始化用户变量 @ID(代表学号)
set @name = '曹操'; # 赋值后的用户变脸 @name 将作为存储过程的输入参数
CALL proc_Test_out (@ID, @name); # 调用存储过程,结果存储在 @ID 变量中。
SELECT concat(@name, '的学号是:', @ID) 结果; # 查看输出变量 @ID 的内容。
(六)变量
1、局部变量
在存储过程程序体中声明的变量就是局部变量。其作用范围在其被声明的 BEGIN…END 块之间。变量可以在嵌套块中使用,除非在块中声明了同名的变量。
局部变量的值可以通过存储过程的OUT参数传递给外部。
2、用户变量
用户变量是基于当前会话的(连接)。 即用户变量的作用域局限于当前会话,由一个客户端定义的用户变量不能被其他客户端看到或使用。
用户变量以"@“开始,形式为”@变量名",使用SET设置变量时,可以使用“=”或者“:=”操作符进行赋值。使用用户变量可以实现在不同的SQL间传递值。
3、存储过程中的变量
(1) 声明
DECLARE var_name <类型>[(<长度>)];
declare iCount int;
(2) 赋值
1、单变量赋值:SET var_name = 值;
2、批量赋值:SELECT col_name[,…] INTO var_name[,…] FROM onetable LIMIT 1;
select Sname, Sage into varName, varAge from student where SId='01' limit 1;
注意:只有单一行的结果才可以被取回!所以语句最后需要加上 limit 1。
(3) 输出变量值
SELECT var_name; # 用于存储过程 DEBUG
(七)存储过程的流程控制
1、两种条件分支结构
(1) IF <判断条件> THEN <执行体> ELSE <执行体> END IF;
######(IF 条件分支)######
delimiter $
drop procedure if exists pTestCondition01 $
CREATE procedure pTestCondition01(in name varchar(10), in subject varchar(10))
begin
declare iScore smallint;
declare sSubject varchar(10);
declare sGrade varchar(10);
select sc.SC into iScore from student S inner join score sc on sc.Sid=S.SId
inner join Course C on C.CId=sc.CId
where S.Sname=name and C.Cname=subject;
if iScore>=90 then set sGrade = '优秀';
elseif iScore>=80 then set sGrade = '良好';
elseif iScore>=60 then set sGrade = '及格';
else
set sGrade = '不及格';
end if;
select subject, iScore, sGrade;
end $
delimiter ;
###########
#call pTestCondition('刘备','语文');
(2) CASE WHEN…ELSE…END CASE;
###### CASE 条件分支 ###############
delimiter $
drop procedure if exists pTestCondition02 $
CREATE procedure pTestCondition(in name varchar(10), in subject varchar(10))
begin
declare iScore smallint;
declare sSubject varchar(10);
declare sGrade varchar(10);
select sc.SC into iScore from student S inner join score sc on sc.Sid=S.SId
inner join Course C on C.CId=sc.CId
where S.Sname=name and C.Cname=subject;
case when iScore>=90 then set sGrade = '优秀';
when iScore>=80 then set sGrade = '良好';
when iScore>=60 then set sGrade = '及格';
else
set sGrade = '不及格';
end case;
select subject, iScore, sGrade;
end $
delimiter ;
###### 测试 #####
call pTestCondition('刘备','语文');
2、三种循环结构:
(1) LOOP 循环: LOOP…LEAVE <标签>…END LOOP <标签>;
###### 流程控制示例(标签循环;ITERATE 和 LEAVE):
DELIMITER $
USE `courseware`$
DROP PROCEDURE IF EXISTS `pCircleLabel`$
CREATE PROCEDURE pCircleLabel(in fromN INT, in ToN int, out rs INT)
BEGIN
set rs = fromN;
lblCircles: LOOP
SET fromN = fromN + 1;
SET rs = rs + fromN;
IF fromN < ToN THEN
ITERATE lblCircles; # 继续执行标签循环
END IF;
LEAVE lblCircles; # 退出标签循环
END LOOP lblCircles;
END $
DELIMITER ;
###### 测试 ######
set @rs = 0;
call pCircleLabel(1, 100, @rs);
select @rs
严格讲,LOOP 不是循环语句,其循环体内如果条件永远不满足,则容易形成死循环。
(2) WHILE 循环:
WHILE <执行条件> DO <执行体> END WHILE;
进入循环体之前先判断条件。
(3) REPEAT 循环:
REPEAT <执行体> UNTIL <退出条件>…END REPEAT;
循环体末尾判断条件。
下面我们分析一个包含WHILE、REPEAT循环的综合示例——
DELIMITER $
USE `courseware`$
DROP PROCEDURE IF EXISTS `pCircleWhileRepeat`$
CREATE DEFINER=`root`@`%` PROCEDURE `pCircleWhileRepeat`(age INT)
BEGIN
/*变量的声明*/
DECLARE username VARCHAR(40);
DECLARE var INT;
DECLARE DONE INT DEFAULT 0;
DECLARE varPERIOD_ID INT; # 接收 program_period.PERIOD_ID 字段的变量
DECLARE varChapter_id VARCHAR(40) ; # 接收 program_period.chapter_id 字段的变量
/* 声明一个游标,指向一个结果集 */
DECLARE cur_program_period CURSOR FOR SELECT PERIOD_ID, chapter_id FROM program_period ;
/* 游标结束标识(循环游标结束时候 这个数值会变为1) */
DECLARE CONTINUE HANDLER FOR SQLSTATE '02000' SET DONE=1;
#SET age=7 ;
/*if语句以及逻辑运算符*/
IF age > 29 THEN
SELECT '年龄大于29' ;
END IF;
SET username='GBase'; # 字串变量赋值
SELECT username ; # 输出变量值
/* WHILE 循环 */
SET var = 0;
WHILE var < 6 DO
SET var = var +1 ;
END WHILE ;
SELECT var ; # 输出 6
/* 打开游标 */
OPEN cur_program_period;
/* REPEAT 循环*/
REPEAT
FETCH cur_program_period INTO varPERIOD_ID , varChapter_id ;
if not DONE then
insert into program_period(PERIOD_ID, chapter_id) values(varPERIOD_ID, varChapter_id);
end if;
UNTIL DONE END REPEAT; # DONE = 1 时退出循环
CLOSE cur_program_period; # 关闭游标
END$
DELIMITER ;
(八)存储过程的游标
1、游标的定义:
系统为用户开通的一个数据缓冲区,存放SQL执行结果。用户可以通过SQL语句逐一从游标中获取记录,并赋值给变量,交由主语言进一步处理。游标让 SQL 这种面向集合的语言有了面向过程开发的能力。
2、静态游标
(1) 概念:DECLARE 时必须指定 SELECT STATEMENT 语句的结果集进行绑定;在后续操作中只能对于该结果集进行只读、仅向前的操作。
以游标打开时刻的当时状态显示结果集。有时又称为快照游标。
(2) 语法:
- 声明:DECLARE <游标名称> CURSOR FOR <SELECT 语句>
注意变量声明顺序是严格要求的:
1st 局部变量
2nd CURSOR
3rd HANDLER
- 打开:OPEN <游标名称>
- 取数:FETCH <游标名称> INTO <局部变量>
- 关闭:CLOSE <游标名称>
如果没有明确的关闭游标的语句,在包含光标声明、使用的 BEGIN…END 复合语句块结束时,光标会自动关闭的。但即使如此,也应该及时关闭不再使用的游标,及时释放服务器资源,否则可能导致数据库服务器性能下降。
(3) 静态游标示例:
delimiter |
DROP PROCEDURE if exists pStaticCursor |
/*
实现累加考试成绩最高的几个学员的总分,直到总和大于我们传入的limit_total_grade的参数值,
并且返回累加的人数:total_count;
*/
CREATE PROCEDURE pStaticCursor(IN LIMIT_TOTAL_GRADE INT, OUT TOTAL_COUNT INT )
BEGIN
# 声明相关的变量
DECLARE SUM_GRADE INT DEFAULT 0; # 累加的总成绩
DECLARE CURSOR_GRADE INT DEFAULT 0; # 记录某条成绩
DECLARE SCORE_COUNT INT DEFAULT 0; # 记录累加的记录数
# 定义游标
DECLARE SCORE_CURSOR CURSOR FOR SELECT SC FROM SCORE ORDER BY SC ;
# 打开游标
OPEN SCORE_CURSOR;
# 使用游标
REPEAT
FETCH SCORE_CURSOR INTO CURSOR_GRADE; # 从游标中获取一条数据
SET SUM_GRADE = SUM_GRADE + CURSOR_GRADE; # 成绩累加
SET SCORE_COUNT = SCORE_COUNT + 1; # 记录累加的次数
UNTIL SUM_GRADE > LIMIT_TOTAL_GRADE # 退出条件
END REPEAT ;
# 复制OUT参数
SET TOTAL_COUNT = SCORE_COUNT;
# 关闭游标
CLOSE SCORE_CURSOR;
end |
delimiter ;
###### 调用存储过程 ######
SET @s_count = 0;
CALL pStaticCursor(200,@s_count) ;
SELECT @s_count;
3、动态游标
(1) 概念:
在DECLARE 时使用 REF CURSOR 声明为动态游标后,允许在OPEN 时可多次绑定不同 SELECT STATEMENT 语句的结果集。
在游标打开时反映对基础数据进行的修改。
(2) 语法:
DECLARE <游标名称> REF CURSOR
OPEN <游标名称> FOR <SELECT 语句>
FETCH <游标名称> INTO <局部变量>
CLOSE <游标名称>
(3) 动态游标示例
DROP PROCEDURE IF EXISTS pDymanicCursor;
DELIMITER $$
CREATE PROCEDURE pDymanicCursor()
/*
功能:ssbm.customer.c_region 中的地区值提取出来,插入到 courseware.country 国家维表中,每个国家名称对应唯一的 GUID
*/
BEGIN
DECLARE sRegion VARCHAR(40); # 客户所在地区
DECLARE DONE INT DEFAULT(0); # 游标读取到记录结尾的标识
DECLARE cur REF CURSOR; # 声明动态游标
DECLARE CONTINUE HANDLER FOR SQLSTATE '02000' SET done = 1; # 若侦测到 02000 错误(ER_SP_FETCH_NO_DATA,游标到记录结尾)号
OPEN cur FOR SELECT DISTINCT c_region FROM ssbm.customer ORDER BY c_region LIMIT 6;
/* 开始循环 */
REPEAT
FETCH cur INTO sRegion;
IF NOT done THEN
insert into courseware.country values(UUID(), sRegion);
END IF;
UNTIL DONE END REPEAT; # DONE = 1 结束循环
CLOSE cur; # 关闭游标
END $$
DELIMITER ;
###### 测试 ################
call pDymanicCursor();
4、存储过程的游标总结
(1) 游标最多的应用场景是数据迁移:
源数据体量非常大,不能全部缓存到到客户端、做数据集合式处理;并且每行数据处理逻辑不尽相同、条件分支多。
数据操闲时的数据跑批任务使用游标是没有问题的。
(2) 优化建议
能用一条包含多个相关子查询的 SQL,就尽量不用游标。游标的操作类似将每行的值取出来,循环地做逻辑处理,对性能有一定的影响。
确实不能使用一条SQL实现的逻辑,也有替代方法(临时表方案)。举例如下——
drop procedure if exists `pCursorSubstitute`;
delimiter |
CREATE PROCEDURE `pCursorSubstitute`()
/*
* 用游标实现:从 student 表中取学生信息,再通过 score 求每位学生的分数平均值
* */
BEGIN
DECLARE id char(2); # 学生标识
DECLARE s_Name char(10); # 学生姓名
declare avgSC float; # 每位学生的平均分数
#create temporary table tmpResult(SID char(2) primary key, name varchar(20), avgScore float default NULL, flag bool default 0);
declare DONE boolean;
declare csr cursor for select SId, Sname from student;
DECLARE CONTINUE HANDLER FOR SQLSTATE '02000' SET DONE = 1;
SET DONE = 0;
/* 创建用于处理临时结果集的临时表 */
drop table if exists tmpResult;
create temporary table tmpResult(SID char(2) primary key, name varchar(20), avgScore float default NULL);
open csr; # 打开游标
repeat
#set id = '';
#select SID into id from tmpResult where flag = 0 limit 1;
fetch csr into id, s_Name; # 每次取得学生标识和姓名
#if @id != '' then
if not DONE then
#set avgSC = null;
select avg(SC) into avgSC from score where SId = id;
#update tmpResult set flag = 1, avgScore = @avg where SID = @id;
insert into tmpResult(SID,name,avgScore) values(id, s_Name,avgSC);
end if;
UNTIL DONE end repeat;
SELECT * from tmpResult; # 输出处理结果
#drop table tmpResult;
close csr; # 关闭游标
end |
delimiter ;
################
call pCursorSubstitute();
将以上存储过程代码改写为 pCursorSubstitute02,避开游标的使用 ——
drop procedure if exists `pCursorSubstitute02`;
delimiter |
CREATE PROCEDURE `pCursorSubstitute02`()
/*
* 用临时表替代游标:从 student 表中取学生信息,再通过 score 求每位学生的分数平均值
* */
BEGIN
DECLARE id char(2);
DECLARE s_Name char(10); # 学生姓名
declare avgSC float; # 每位学生的平均分数
/* 创建临时表,比 pCursorSubstitute 中的 tmpResult 增加 flag 字段(flag=0标识未处理)用于标识当前行数据是否处理完毕 */
drop table if exists tmpResult;
create temporary table tmpResult(SID char(2) primary key, name varchar(20), avgScore float default NULL, flag bool default 0);
#create temporary table tmpResult(SID char(2) primary key, name varchar(20), avgScore float default NULL);
insert into tmpResult(SID, name) select SId, Sname from student;
#open csr;
repeat
set id = '';
select SID into id from tmpResult where flag = 0 limit 1; # 取得一条未处理的数据
#fetch csr into id, s_Name;
if id != '' then
#if not DONE then
#set avgSC = null;
select avg(SC) into avgSC from score where SId = id;
# 当前行数据处理完毕,设置 flag = 1
update tmpResult set flag = 1, avgScore = avgSC where SID = id;
#insert into tmpResult(SID,name,avgScore) values(id, s_Name,avgSC);
end if;
until id = '' end repeat;
SELECT * from tmpResult; # 输出处理结果
#drop table tmpResult;
end |
delimiter ;
###### 测试 ##########
call pCursorSubstitute02();
(九)存储过程的预处理
1、预处理的概念
Prepared Statement,编译过的要执行的SQL语句模板,可以使用不同的变量参数定制。还可以通过存储过程参数控制SQL语句模板中数据对象(表、视图等)名称的变化,即实际意义上的动态SQL。
预处理的优势:一次编译、多次运行,省去了解析优化等过程;防止 SQL 注入。
2、预处理的语法
# 定义预处理语句( 作用域是session级)
PREPARE stmt_name FROM preparable_stmt;
# 执行预处理语句的语法格式
EXECUTE stmt_name [USING @var_name [, @var_name] ...];
# 删除(释放)预处理的定义
{DEALLOCATE | DROP} PREPARE stmt_name;
3、预处理的两种模式
(1) 无参数的预处理
PREPARE STMT FROM 'select * from Student ';
EXECUTE STMT ;
DROP PREPARE STMT;
(2) 一个参数的预处理
set @rows = 5;
PREPARE STMT FROM 'select * from Student limit ? ';
EXECUTE STMT USING @rows;
DROP PREPARE STMT;
注意:limit 子句中不能直接使用变量,要用预处理语句来为 limit 子句绑定一个参数
? 是个占位符,所代表的是一个字符串。
(3) 多个参数预处理
DELIMITER |
DROP PROCEDURE IF EXISTS courseware.p_test_ps |
/* 需求:输入学生姓氏和学号,输出学员列表*/
CREATE PROCEDURE "p_test_ps"(inName varchar(20), inID varchar(10))
BEGIN
SET @name=concat(inName, '%');
set @ID=inID;
# 学生姓名模糊查询;标识是精确查询
SET @ps = 'SELECT * FROM student WHERE Sname LIKE ? and Sid=?';
PREPARE stmt FROM @ps; # 将 @name @ID 两个参数替代到以上 SQL 文中的两个问号
EXECUTE stmt USING @name, @ID; # 执行 SQL
DEALLOCATE PREPARE stmt; # 删除预处理占用的内存
END |
DELIMITER ;
(4) 预处理实现动态SQL
- 需求:每日结存日志表。
- 假设:每天0:00~00:05系统维护,当天是 2022.05.12;0:01执行该存储过程,
logdata 更名为 logdata_20220511,并且产生同构新表 logdata - 接口参数:日志名称
- 逻辑伪代码:
1、rename table logdata to logdata_YYYYMMDD
2、create table logdata like logdata_YYYYMMDD
delimiter |
drop procedure if exists `pDynamicTableName`|
/* 需求:每日结存日志表。
假设每天0:00~00:05系统维护,当天是 2022.05.12;0:01执行该存储过程,logdata更名为logdata_20220511,
并且产生同构新表logdata
*/
CREATE procedure pDynamicTableName(IN logname varchar(50))
begin
declare newtab varchar(50);
# 新的日志表名是逻辑日志名称加前一天日期
set newtab = logname || date_format(date_sub(now(),interval 1 day), '_%Y%m%d');
# 主内更换表名的预处理 SQL
set @renameSQL = 'rename table ' || logname || ' to ' || newtab;
set @createSQL = 'create table ' || logname || ' like ' || newtab;
#select @renameSQL;
prepare renameStmt from @renameSQL;
execute renameStmt; # 执行日志表的更名(即前一天的日志表结存)
prepare createStmt from @createSQL;
execute createStmt; # 创建新的日志表
DEALLOCATE prepare renameStmt; # 释放预处理对象
DEALLOCATE prepare createStmt; # 释放预处理对象
end |
delimiter ;
#################################
call pDynamicTableName('logdata');
(十)存储过程的异常处理
任何编程语言都需要在代码中监测可能发生的系统异常,即设置错误陷阱,捕获异常后程序要有响应的处理方法,以提升代码的健壮性。如果不设置错误陷阱,任何模块发生的系统异常将导致整个应用崩溃。讲解异常处理之前,我们先看看 GET DIAGNOSTICS 关键字的用法。
1、GET DIAGNOSTICS
- 基本功能:获得DML操作的影响行数;捕获存储过程中SQL执行的异常信息。
- 报错信息:错误数、错误号、错误状态、错误信息。
- 常用 GET DIAGNOSTICS 语句:
– 获取错误和告警的数量:
GET DIAGNOSTICS n=NUMBER;
– 获取DML操作影响的行数:
GET DIAGNOSTICS r=ROW_COUNT;
– 获取错误号:
GET DIAGNOSTICS CONDITION 1 error=GBASE_ERRNO;
– 获取错误状态:
GET DIAGNOSTICS CONDITION 1 state=RETURNED_SQLSTATE;
– 获取错误信息:
GET DIAGNOSTICS CONDITION 1 msg=MESSAGE_TEXT;
2、异常处理
(1) 定义处理器:
DECLARE {CONTINUE | EXIT} HANDLER FOR condition_value[,…]
SQLWARNING:对所有以01开始的SQLSTATE代码的速记;
NOT FOUND:对所有以02开始的SQLSTATE代码的速记;
SQLEXCEPTION:除了SQLWARNING、NOT FOUND以外的异常代码。
(2) 捕获错误信息:
GET DIAGNOSTICS CONDITION 1 errno=GBASE_ERRNO, sstate=RETURNED_SQLSTATE, message=MESSAGE_TEXT;
(3) 输出错误信息:可以通过存储过程结果集或者存储到日志实表中。
DELIMITER |
DROP PROCEDURE IF EXISTS p_get_exception|
CREATE PROCEDURE p_get_exception()
BEGIN
DECLARE errno, sstate, message varchar(50);
DECLARE CONTINUE HANDLER FOR SQLEXCEPTION # 定义处理器监测 SQLEXCEPTION,发生异常后继续执行下面的语句
# 捕获下方语句块中错误号SQL STATE、和错误信息
GET DIAGNOSTICS CONDITION 1 errno=gbase_errno, sstate=returned_sqlstate, message=message_text;
DELETE FROM onetable; # 试图删除一个不存在的表
SELECT errno, sstate, message;# 输出错误号、SQL STATE和错误信息
END |
DELIMITER ;
###### 测试 #################
CALL p_get_exception();
(十一)存储过程的约束
- 要创建一个存储过程,必须具有 CREATE ROUTINE 权限
- 不支持断点调试、跟踪。可以使用 SELECT 语句输出变量的中间结果。
- 存储过程中不支持任何 Exception(异常) 的定义和 throw(抛出)。
- 结果集返回给客户端时,直接 select…from…输出数据集。
五、存储函数:
(一)存储函数的语法
1、创建
CREATE FUNCTION <func_name>(param1 INT, param2 VARCHAR(10)...))
RETURNS <数据类型>
BEGIN
<程序体>
RETURN <指定类型的单值>
END
(1) 参数只有输入类型;
(2) 必须包含 RETURN 语句,只能返回单值。
(3) 程序体中支持条件分支和循环语句。
2、调用
SET 用户变量= 函数名(参数列表);
例如:
SET @result = hello('world');
SELECT @result; # 输出变量值
(二)代码示例
delimiter $
drop function if exists `f_test1`$
create DEFINER=`gbase`@`%` function `f_test1`(id varchar(2)) returns varchar(10)
begin
declare name varchar(10);
select Sname into name from student where SId=id;
return name; # 存储函数只能返回单值
end $
delimiter ;
###### 测试 ####################
set @name = f_test1('03');
select @name;
下面的例子是将存储过程 pTestCondition02 替换为存储函数
DROP FUNCTION IF EXISTS courseware.fnTestCondition ;
DELIMITER $$
$$
CREATE FUNCTION "fnTestCondition"(name varchar(10), subject varchar(10)) RETURNS varchar(3) CHARSET utf8
begin
declare iScore smallint;
declare sSubject varchar(10);
declare sGrade varchar(10);
select sc.SC into iScore from student S inner join score sc on sc.Sid=S.SId
inner join Course C on C.CId=sc.CId
where S.Sname=name and C.Cname=subject;
/* 根据分数判断优秀、良好、及格、不及格 */
case when iScore>=90 then set sGrade = '优秀';
when iScore>=80 then set sGrade = '良好';
when iScore>=60 then set sGrade = '及格';
else
set sGrade = '不及格';
end case;
return sGrade; # 返回成绩级别
end $$
DELIMITER ;
###### 测试 ######
set @grade = fnTestCondition('刘备','语文'); # 存储过程的调用需要用 call 关键字;存储函数需要用变量接收其返回值
select @grade;
六、存储过程和存储函数的区别:
(一)创建:
CREATE PROCEDURE 语句创建存储过程;
CREATE FUNCTION…RETURNS 语句创建存储函数。
(二)返回值:
存储过程没有返回值,但是可以输出数据集;
存储函数必须有返回值,且只能单值。
(三)参数:
存储过程可以有IN, OUT, INOUT 参数;
存储函数只有输入参数,而且不能带IN关键字。
(四)调用:
存储过程用 CALL 关键字调用;存储过程内可以调用存储函数;
存储函数可以赋值给变量;不能调用存储过程。
(五)功能:
存储过程中支持DDL、DML语句,可以实现比较复杂的业务逻辑。
存储函数有很多限制:不能在存储函数中使用 DML 和 DDL 语句、不能创建和使用临时表;仅完成功能针对性较强的查询工作,输入参数、从表字段中取数运算并返回一个单值结果。
七、总结
GBase 8a MPP Cluster 存储过程的功能明显比存储函数强大。存储过程最适合的场景是在数据迁移项目中实现复杂的数据抽取、清洗、转换、加载等逻辑。如果用在业务环境中,存储过程代码的执行效率要保证,以满足高并发。
















 582
582











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









