







转载:http://blog.csdn.net/a1015553840/article/details/50781173
大家好,这篇文章主要和大家讨论coursra网站上斯坦福大学机器学习第6周第二部分Machine Learning System Design的课后习题。我将给出习题的大致翻译和本人的解题思路,其中可能存在错误,欢迎大家批评指正!
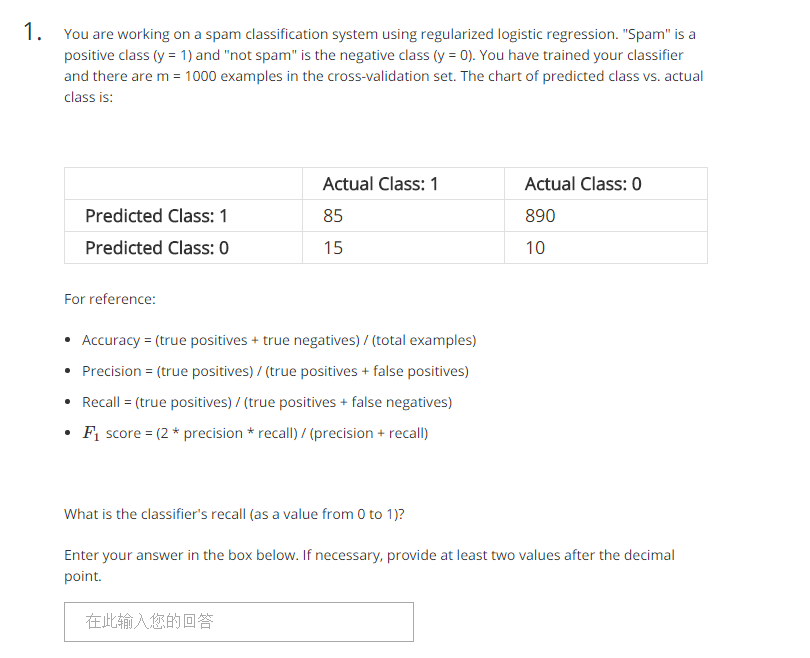
题意:你用正则化逻辑回归构造一个垃圾邮件分类器,垃圾邮件y=1这类,非垃圾邮件为y=0这类。你已经训练好了你的分类器,并且有1000个交叉验证数据集。预测分类和实际分类的图标如下。
请问这个分类器的recall(召回率)为多少?将答案填入下面框内,不少于两位小数。
分析:
| Tables | Actuall 1 | Actuall 0 |
|---|---|---|
| prediction 1 | True possitive | False possitive |
| prediction 0 | False Negative | True Negative |
85对应的是True possitive,890对应的是False possitive,15对应的是False negative,10对应的是True negative.召回率对应第三个公式,带入计算即可。
答案:recall = 85/(85+15)=0.85. 注意,不同学生计算的内容可能不同,看清计算recalll,accuracy,prediction,F1 score.

题意:假设有大量的数据集可以用于训练机器学习算法。当下列选项中有的两个为真时,利用大量的数据训练有良好的效果。请问是哪两个?
1.当我们想要利用高次多项式作为特征,如x1^2,x1x2等
2.数据不是偏斜类
3.我们学习算法可以相当复杂(比如利用很多参数训练神经网络和其他一些算法)
4.当给定特征x时,专家可以确定的预测y。即x提供了足够的特征,我们特定方法可以准确的预测y。
分析:因为有大量的训练数据,所以不会出现过拟合(或称为高方差high variance)问题,所以我们要解决欠拟合(或成为高偏差high bias)问题。
答案:3,4

题意:假设你训练了一个逻辑回归分类器,他的输出是h(x)。目前,当h(x)大于threshold,预测为1;当h(x)小于threshold,预测为0,目前的threshold定为0.5。假设你增加threshold到0.9,下面哪些是正确的?
1.分类器的查准率和召回率不变,因此F1 score不变
2.分类器有更高查准率
3.分类器有更高召回率
4.分类器查准率和召回率不变,但是准确率更高了
分析:threshold提升到0.9,即你在非常确定的情况下才把它归为y=1,查准率自然提升了,召回率降低了。
答案:2
题意:假设你在创建一个垃圾邮件分类器,垃圾邮件被归为y=1类,非垃圾邮件被归为y=0类。用于训练的邮件99%是非垃圾邮件,1%是垃圾邮件。下面哪些陈述时正确的。
1.如果你总是预测输入为垃圾邮件,分类器的recall为100%,prediction为1%
2.如果总预测输入为非垃圾邮件,则正确率为99%
3.如果总预测输入为非垃圾邮件,recall为0%
4.如果总是预测输入为垃圾邮件,recall为0%,prediction=99%
分析:predicetion,recall,accurary,F1 score的计算公式在第一题中已经给出。假设总共有m封邮件。
1.总是预测输入为垃圾邮件,则Ture possitive为1%m,false possitive 为99%m,false negative 为0,Ture negative为0。所以prediction=1%,recall=99%,选。
2.上面四个量分别为:0,0,1%m,99%m,正确率=99%,选。
3.上面四个量分别为:0,0,1%m,99%m,recall=0,选。
4.上面四个量分别为:1%m,99%m,0,0,recall = 100%,prediction=1%,不选。
答案:1,2,3
题意:选出下列陈述所有正确的。
1.当训练了一个逻辑回归分了,必须以0.5为分类器的临界值。
2.用大量的数据让模型不太容易产生过拟合问题。
3.在机器学习算法建立之初就花大量时间搜集大量数据是一个好方法。
4.对于偏斜类,正确率不是衡量模型好坏的好标准,应该用基于prediction和recall的F1 score衡量。
5.如果模型对训练样本欠拟合,添加更多的数据对模型有帮助。
分析:1.错误,可以根据实际情况修改theshold的值,不选
2.正确,数据量大不容易产生过拟合,从learning curves曲线也可看出
3.错误,模型建立之初需要尽快建立模型,分析数据确定改进方法。
4.正确
5.错误,增加训练样本数可以帮助解决overfitting,不是unfderfitting.
答案:2,4
















 155
155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









