




吴恩达-机器学习公开课 学习笔记 Week6-2 Machine Learning System Design
6-2 Machine Learning System Design 课程内容
此文为Week6 中Machine Learning System Design的部分。
6-2-1 Building a Spam Classifier
Prioritizing What to Work On
建立一个垃圾邮件分类器:

在实际工作中,最普遍的做法是遍历整个训练集,然后在训练集中选出出现次数最多的n个单词,n一般介于10,000和50,000之间。然后把这些单词作为你要用的特征。
如果你正在构造一个垃圾邮件分类器,你应该会面对这样一个问题:那就是你最该去使用哪一 改进你的方法,从而使得你的垃圾邮件分类器具有较高的准确度?
- 收集大量的数据
- 用更复杂的特征变量,像是邮件的路径信息、邮件的标题部分、故意的拼写错误…
- 误差分析
Error Analysis
准备研究机器学习的东西或者构造机器学习应用程序 :
- 构建一个简单的算法,很快地实现它。运行一遍,最后通过交叉验证来检验数据。
- 画出学习曲线以及检验误差,来找出你的算法是否有高偏差和高方差的问题或者别的问题。
- 误差分析:一种手动检测的过程,检测算法可能会犯的错误。
最后,在构造机器学习算法时,另一个有用的小窍门是保证你能有一种数值计算的方式来评估你的机器学习算法。它基本上非常直观地告诉你,你的想法是提高了算法表现,还是让它变得更坏。这会大大提高你实践算法时的速度。 所以我强烈推荐在交叉验证集上来实施误差分析而不是在测试集上。

6-2-2 Handling Skewed Data
Error Metrics for Skewed Classes
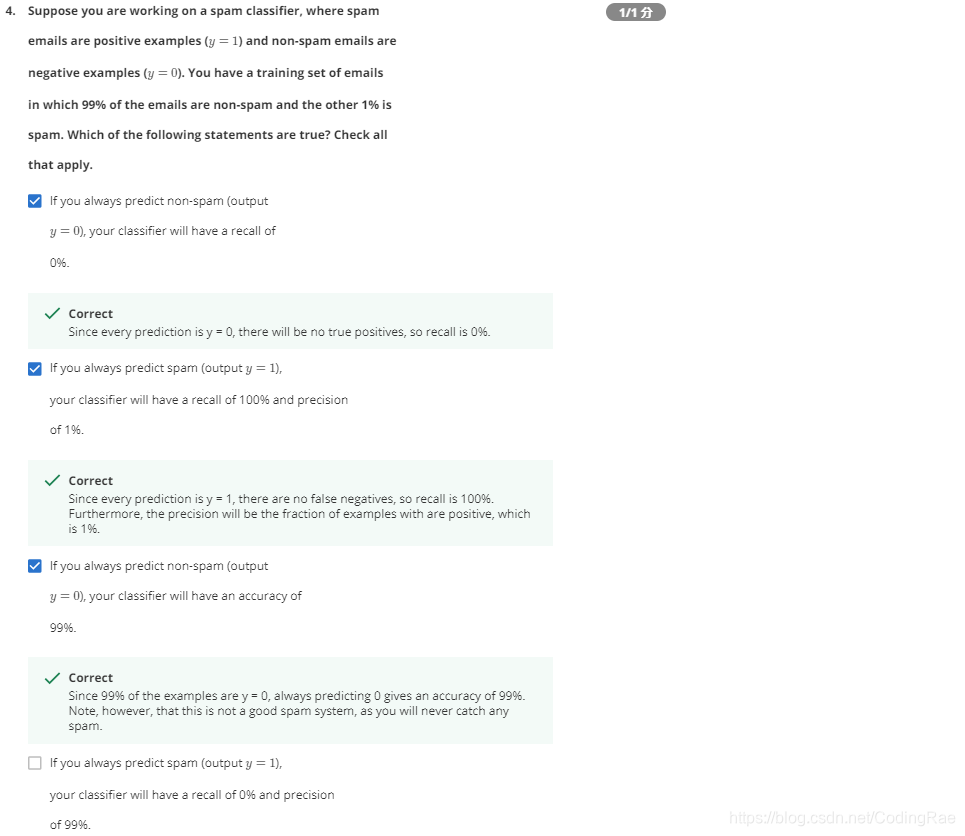
偏斜类:正例和负例的比率非常接近于 一个极端。

当我们遇到这样一个偏斜类时,我们希望有一个不同的误差度量值,或者不同的评估度量值。其中一种评估度量值 叫做查准率(precision)和召回率(recall)。
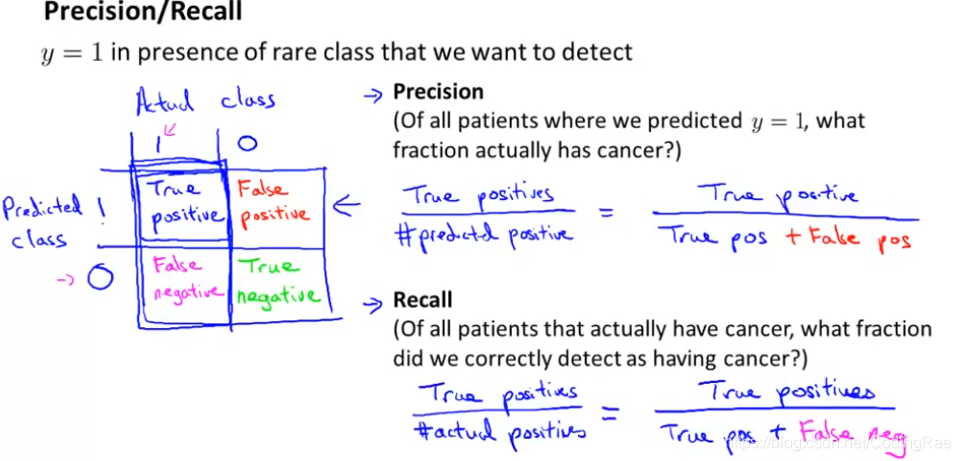
查准率越高就越好,说明对于这类病人我们对预测他们得了癌症有很高的准确率。同样地,召回率越高越好。
在查准率和召回率的定义中,我们定义查准率和召回率,我们总是习惯性地用y=1。如果这个类出现得非常少,因此如果我们试图检测某种很稀少的情况,比如癌症,我希望它是个很稀少的情况。查准率和召回率会被定义为 y=1 而不是y=0。
对于偏斜类的问题,查准率和召回率给予了我们更好的方法来检测学习算法表现如何。这是一种更好地评估学习算法的标准,当出现偏斜类时比仅仅只用分类误差或者分类精度好。
Trading Off Precision and Recall
假设我们用逻辑回归模型训练了数据,输出概率在0-1之间的值。一种方法是修改算法,我们不再将临界值 设为0.5。更普遍的一个原则是这取决于你想要什么。你想要高查准率低召回率,还是高召回率低查准率,你可以预测y=1 当h(x)大于某个临界值。总的来说,对于大多数的回归模型,你得权衡查准率和召回率。
当你改变临界值,可以画出回归模型的所有曲线,来看看你能得到的查准率和召回率的范围。

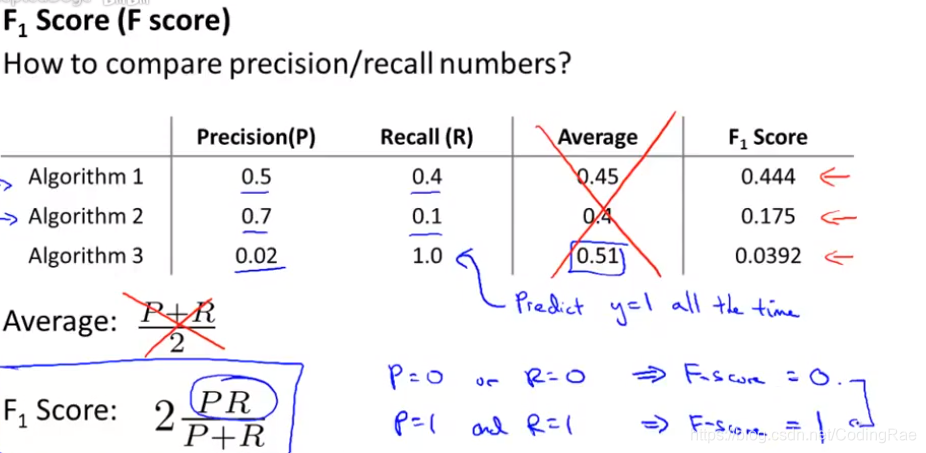
一种结合查准率和召回率的不同方式,叫做F值,也叫做F1值。
6-2-3 Using Large Data Sets
Data For Machine Learning
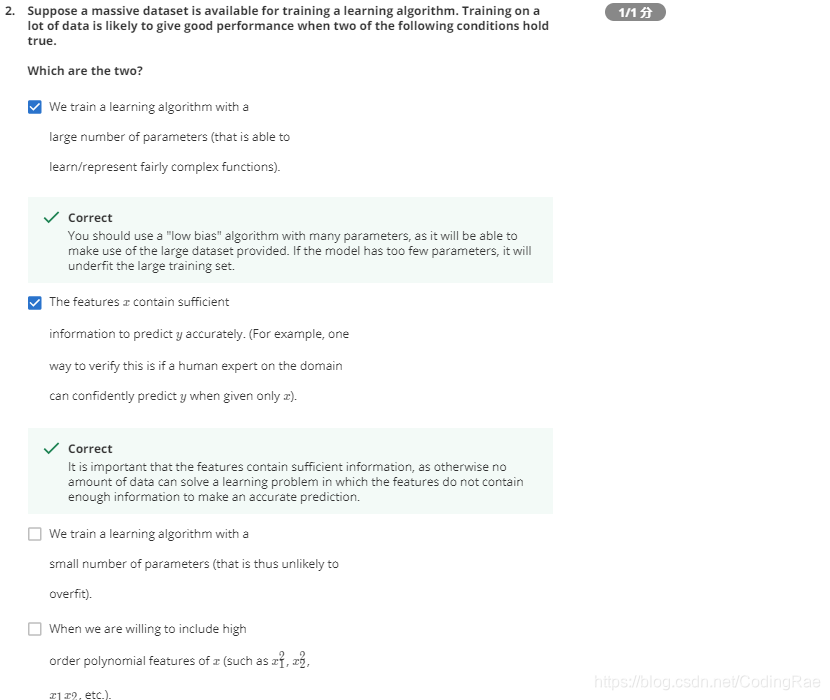
许多不同的学习算法有时倾向于表现出非常相似的表现,这还取决于一些细节,但是真正能提高性能的是你能够给一个算法大量的训练数据。像这样的结果,引起了一种在机器学习中 的普遍共识: “取得成功的人不是拥有最好算法的人,而是拥有最多数据的人”。
测验 Machine Learning System Design


课程链接
https://www.coursera.org/learn/machine-learning/home/week/6


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









