







Python爬虫学习2
Requests库的安装
在经过上一节的学习过后,我们已经安装了Python和相应的IDE,现在就让我们开始正式的Python爬虫的学习。
首先,我们需要安装Resquest库。
下面对Requests库做出简单说明,想要更深层次了解Requests,请自行百度。Requests的官方网站为:http://www.python-requests.org
说明
Requests 是用Python语言编写,基于 urllib,采用 Apache2 Licensed 开源协议的 HTTP 库。它比 urllib 更加方便,可以节约我们大量的工作,完全满足 HTTP 测试需求。Requests 的哲学是以 PEP 20 的习语为中心开发的,所以它比 urllib 更加 Pythoner。更重要的一点是它支持 Python3 哦!
安装
其实Requests库的安装特别简单,只要你在安装Python的时候选择了pip安装,只需要打开命令提示符输入pip install requests
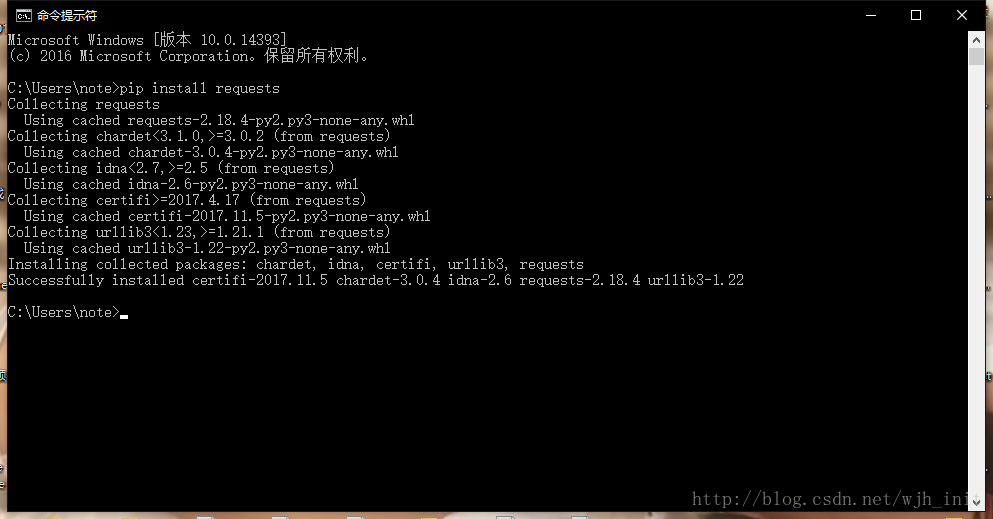
这样就安装完成了,下面我们来实验一下,打开IDLE。
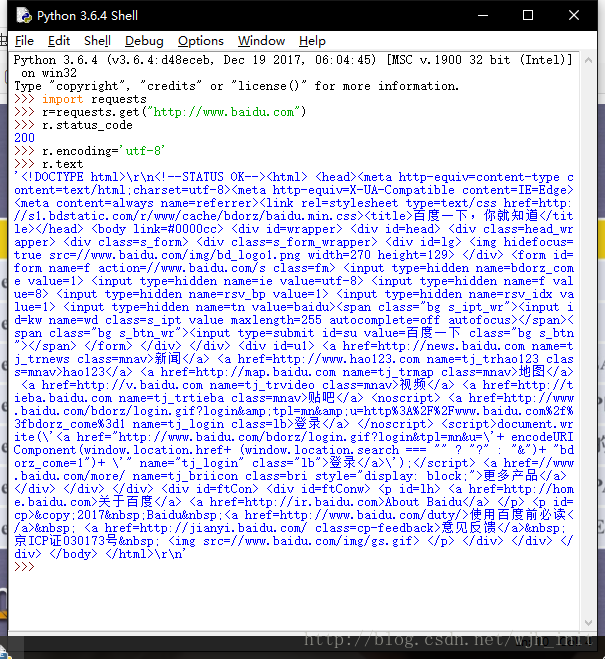
import requests//导入Requests库
r=requests.get("http://www.baidu.com")//请求百度首页
r=status_code//查看状态码
r.encoding='utf-8'//将编码格式转化为utf-8
r.text//查看网页内容下图展示了实验效果
Response对象和Request对象
其实在上文的代码中我们已经使用了这两个对象,只是由于Python的特性,我们并没有看见类型的相关表示。下图清晰的展示了这两个对象。
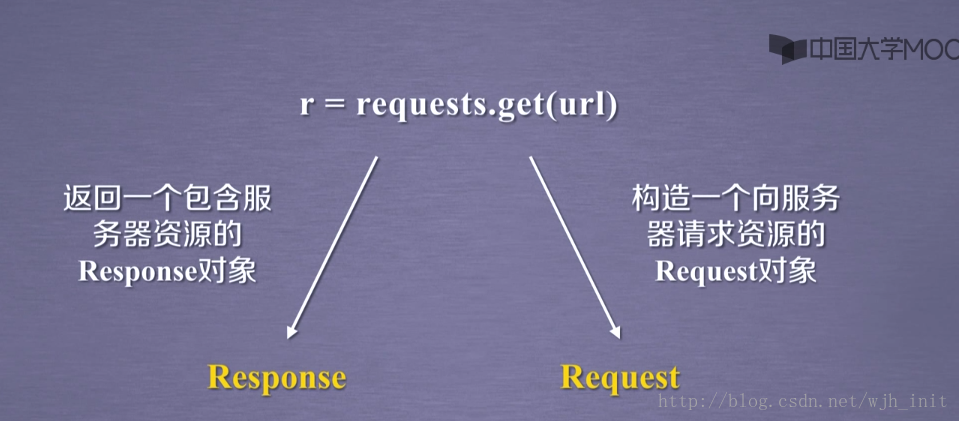
就如上图所言。
下面我们对Response对象进行分析
Response有下面几个属性,分别为:

其中status_code表示的请求状态,需要注意的是只要返回的不是200,则请求都是错误的。
encoding属性是猜测的编码方式,如果在html页面的头部信息中进行了编码格式说明就返回那个编码格式,如果没有就返回ISO-8859-1,所以一般在进行文本的编码格式转化的时候可以参考Response的apparent_encoding对象,因为这个对象是根据内容所分析出的编码格式。一般可以使用这种形式赋予Response正确的编码
r.encoding=r.apparent_encoding
Resquests库的7个主要方法
在这里提示一下,要想很好的理解这7个方法可以去深入的了解一下Http协议,和请自行百度。
下面先给出Http协议对于资源的操作

这里再给出Resquests库的7个主要方法

看到这里大家应该大概明白了吧,其实Requests库方法就是和Http协议方法进行一一对应。

下面对各个函数进行简单说明
requests.requset(method,url,**kwargs)
它是Requests库所有方法的基础方法,它有三个参数。
method:请求方法,对应get/put/post等7中方法。
url:拟获取页面的url链接。
kwargs:控制访问的参数,共13个。由于kwargs参数能让我们更好的理解Requests其它函数的封装。
kwargs参数
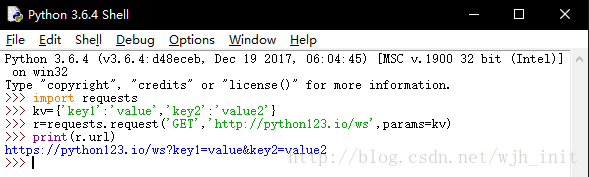
- params:字典或字节序列,作为参数增加到url中。什么意思呢?下面给出一个例子给大家看一下。会在原来的url后面附带上kv中的数据。
- data::字典或字节序列或文件对象,作为Request的内容,一般用于向服务器提供数据。
- json:JSON格式的数据,作为Request的内容。
- header:字典,http定制头。
- cookies:字典或CookiesJar,Request中的cookie。
- auth:元祖,支持HTTP认证功能。
- files:字典类型,传输文件。
- timeout:设定超时时间,秒为单位。
- proxies:设定访问代理服务器,可以增加登录认证。
- allow_redirects:True/False,默认为True,重定向开关。对url进行重定向。
- stream:True/False,默认为True,获取内容立即下载(默认为True)。
- verify:True/False,默认为True,认证SSL证书开关。
cert:本地SSL证书路径。
其实在理解了http协议和上面request函数后其它六个函数其实很容易理解。
requests.get(url,params=None,**kwargs)
requests.head(url,**kwaegs)
requests.post(url,data=None,json=Node,**kwargs)
requests.put(url,data=None,**kwargs)
requests.patch(url,data=None,**kwargs)
requests.delete(url,**kwargs)
在最后我们给出一个爬取网页的通用框架。网络连接有风险,异常处理很重要。
在下图中,r.raise_for_status()//如果状态码不为200产生一个异常。







本博客关联课堂教程链接
来源:中国大学MOOC
相关大学:北京理工大学
讲解人:嵩天副教授
课程:Python网络爬虫与信息提取
链接:http://www.icourse163.org/learn/BIT-1001870001?tid=1002236011















 5407
5407

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









