







在测试环境于遇到问题重启服务,并不是一个好的实践,因为重启可能会让不容易出现的问题现场被破坏。如果问题在测试环境不能再重新,却在发版后出现在生产环境的话,那不仅会造成生产运维事件,还要在巨大的压力下去解决问题。
初步分析
顺着测试汇报的出现问题的场景,跟踪调用链上相关服务的日志,发现出现了微服务之间循依赖调用。大致情况可以抽象如下所示(图中所有调用都是 http 协议):
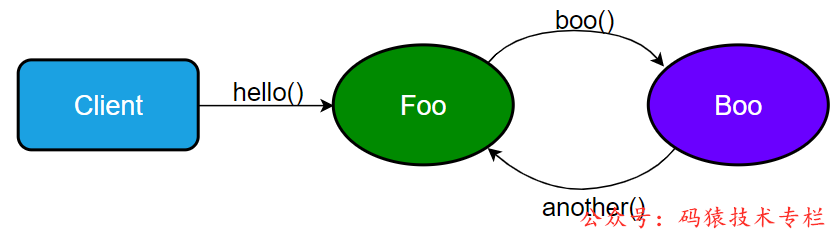
图片
- Client 调用服务 Foo.hello()
- Foo.hello() 逻辑中会调用服务 Boo.boo()
- Boo.boo() 又调用回服务 Foo 的另外一个方法 another()
当然真实的场景要比较这个复杂,调用链更长,不过最终形成了环形依赖调用。至于这个环形依赖为什么回导致超时,当时想了多种可能,比如数据库慢查询、数据库锁、分布式锁等等。但是整个调用链上都是查询请求,而且查询相关的数据量也非常小,不会有锁存在。发生问题的时候也没有与查询数据相关的数据库写请求。
鉴于这个环形依赖调用确实是这个迭代版本中引入的变更,以及虽然没有理清其中的因果关系原理,但是这个环性依赖调用还是很可疑的,而且是不必要的环形调用。就抱着将环形依赖调用去掉试试看的态度,做了修复。修复完后,SocketTimeoutException 不再出现了。问题解决了。
探寻原因
问题虽然不再出现,但是凭运气
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1892
1892

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











