







通常采用读写分离的策略,将 Elasticsearch(简称 ES)引入作为专门的查询数据库。ES 以其卓越的搜索性能、灵活的数据模式以及强大的可扩展性,成为处理复杂查询需求的理想选择。通过 ES,我们可以实现数据的快速检索与分析,从而大幅提升用户体验和系统响应速度。
在这一过程中,确保 MySQL 数据库与 ES 之间的数据同步成为了至关重要的一环。数据同步不仅关乎数据的实时性和准确性,更是保障系统稳定性和用户体验的基石。因此,我们需要精心设计与实施一套高效、可靠的数据同步方案。
具体而言,数据同步的实现方式多种多样,包括但不限于使用 Logstash、Kafka Connect、Debezium 等工具进行实时数据捕获与传输,或通过定时任务(如 Cron Job)结合 SQL 查询与批量导入的方式实现数据的定期同步。在选择同步方案时,我们需要综合考虑数据的实时性要求、系统架构的复杂度、运维成本以及数据的增量更新特性等因素。
同步方案
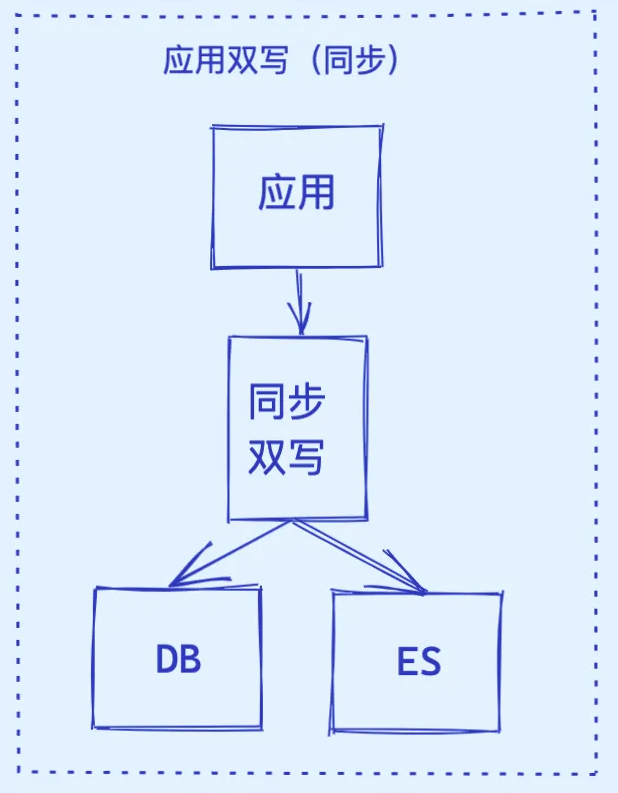
1. 同步双写
同步双写是一种数据同步策略,它指的是在主数据库(如MySQL)上进行数据修改操作时,同时将这些修改同步写入到ES中。这种策略旨在确保两个数据库之间的数据一致性,并优化系统的读写性能。
图片
目标
同步双写是指在进行数据写入操作时,同时向两个或多个数据库写入相同的数据。在MySQL与ES的同步场景中,其主要目的是将MySQL中的业务数据实时同步到ES中,以便利用ES的高效查询能力来应对复杂的查询需求,同时减轻MySQL的查询压力。
实现方式
直接同步
在业务代码中,每次对MySQL数据库进行写入操作时,同时执行对ES的写入操作。这种方式简单直接,但可能增加代码的复杂性和出错的风险。
使用中间件
利用消息队列(如Kafka)、数据变更捕获工具(如Debezium)或ETL工具(如Logstash)等中间件来捕获MySQL的数据变更事件,并将这些事件转发到ES进行同步。这种方式可以解耦业务代码与数据同步逻辑,提高系统的可扩展性和可维护性。
触发器与存储过程
在MySQL中设置触发器或编写存储过程,在数据发生变更时自动触发ES的写入操作。这种方式可以减少业务代码的侵入性,但可能会增加MySQL的负担并影响性能。
优缺点
- 优点
业务逻辑编写简单
业务查询实时性高
- 缺点
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 123
123

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











