







DNS
Domain Name System,
域名系统,首先得明白域名的作用——IP地址不容易记忆,域名相当于是某个主机IP的别名,我们访问某个主机是只需要输入域名即可连接对应的主机,例如我需要访问百度时,输入baidu,com,
但计算机是看不懂域名的,这时候就需要域名系统的帮助了
具体流程是这样的——我们输入域名后,计算机便会开始寻找这个域名对应的IP地址,只要能找到不就完事大吉了么,至于这个寻找的过程,在下文会详细描述。
重点:
域名格式
以 点dot 为分隔符,
mail.cumt.edu. 从左到右级别依次升高,最高级为 "." 即根域名,然后是顶级域名,二级,三级....
baidu.com,这是我们平时所输入的域名,其实真正的域名最后面还有一个“.”代表根域名
真正的域名应该是这样www.baidu.com. 平时只不过浏览器帮我们补充上了而已
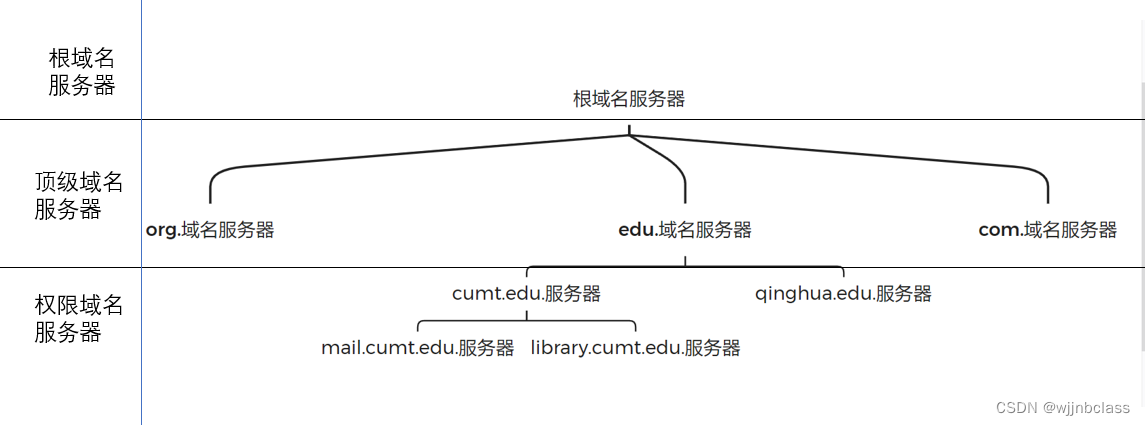
域名服务器
域名服务器有四类:
1,根域名服务器 2,顶级域名服务器 3,权限域名服务器 4,本地域名服务器
 他们之间有如下联系:
他们之间有如下联系:
每台域名服务器都有根域名服务器的IP地址
对于前三者而言,上级服务器记录了下级服务器的IP
因此可知,只要从根服务器开始查询,一定能查到结果
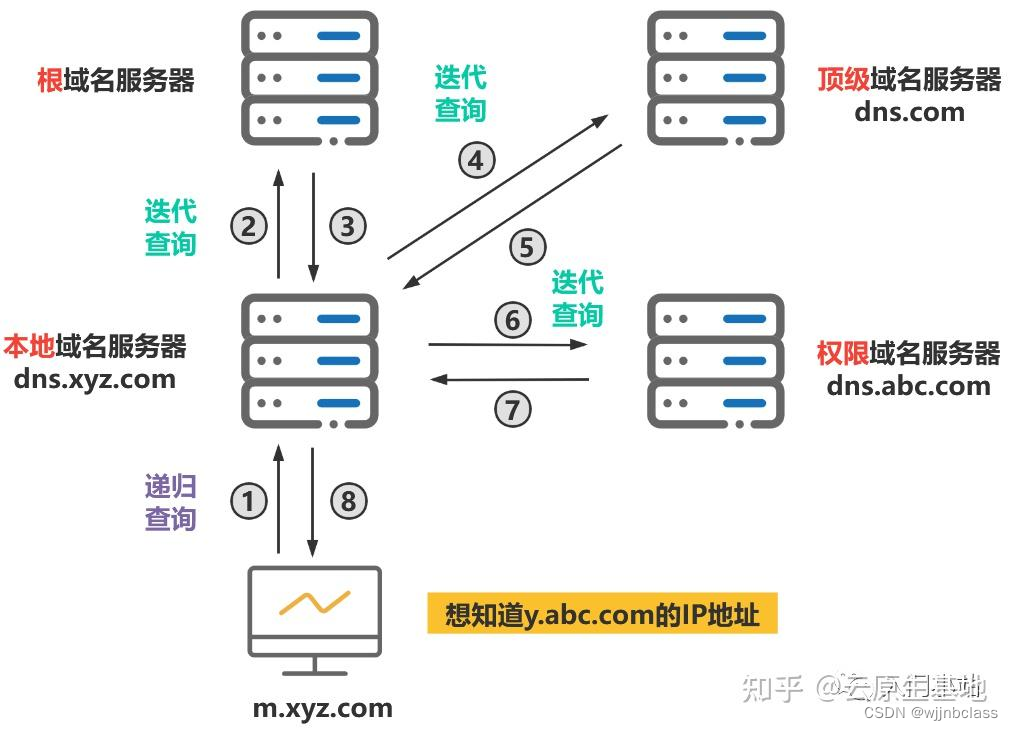
而在在查询域名对应的ip时,主机第一个访问的是本地域名服务器,其存储的是用户当前这个小网络的域名-IP对应信息,若未查到则利用本地域名服务器从根域名服务器开始查询,
需要注意的是,主机与本地域名服务器之间一定是递归查询
而本地服务器与根,权限服务器查询的过程中就有两种方式:
1,递归查询 2,迭代查询
简单来说:
递归是一层一层一直查,查到为止,然后再将数据一层一层返回去,这个过程中参与查询的每个服务器都接力传输
而迭代查询,对方查到信息了,不会替你继续查,替你传输信息,而是把你要查的信息丢给你,接下来的查询,数据传输你自己搞定
主机向本地服务器查询为递归查询。
本地服务器与根,权限服务器查询的为递归查询或者递归查询。

参考这篇文章
DHCP
Dynamic Host Configurition Protocal--动态主机配置协议
端口号固定:client为68,server为67
对于移动通信设备来说,由于经常在不同网络之间切换,
每次都需要配置:ip地址,子网掩码,默认路由器的ip地址,本地域名服务器的ip地址
这样很麻烦,于是设计了DHCP协议,租用“ip地址”给主机
有以下四个步骤:
1,首选客户端在所属网络广播DHCP信息(源ip0.0.0.0,目标ip255.255.255.255)
2,当这个网络的DHCP服务器或者DHCP中继代理收到时,便会回复该客户端,给出这一系列配置信息,称为offer
(这里解释一下DHCP代理服务器,假设在每个网络都搭建一个DHCP服务器,这样代价太大了,于是在每个网络都设一个DHCP中继代理relay agent,在客户端所属网络内,客户端以广播形式找到relay agent,然后relay以单播的方式与DHCP服务器通信),当这个网络的DHCP服务器或者DHCP代理服务器收到时,便会回复
3,客户端会收到多个offer,选择其中一个offer,向该offer的发送方发出DHCP请求报文
4,DHCP服务器收到请求报文后,向客户端发送acknolodge确认
前两步的目的主要是为了让客户端找到合适DHCP服务器的IP地址

同时租用是有规定时间的,这里设租用期时间为T
当时租用时间到达,0.5T,0.875T时,客户端便会从第三步开始申请延长租用期
万维网WWW,HTML,URL,HTTP,HTTPS
万维网 WWW,World Wide Web
其实相当于多台服务器连接在一起形成的网络
同时,不需要制作专门的应用程序,来连接这些服务器。
所以主机只需要通过浏览器即可访问所有万维网中的服务器,这时就出现了问题:
这么多服务器,找哪台,文件在哪,文件会不会重名,于是设计了URL统一资源定位符,万维网中的每一个文件都有自己的URL,通过这个URL便能找到这个文件。
Web 浏览器从Web 服务器或本地存储接收 HTML 文档,并将文档呈现为多媒体网页。
浏览器相当于也是一个编译器,实时的将获得的html文档编译解析成可视化的网页,提供给用户HTML从语义上描述了网页 的结构,并且最初包含了其外观的提示。
还需介绍,在web上获取文件的方式是通过超链接,超链接相当于一个指针指向要去的地方。
当然这个超链接也是html文档中提供的
URI,Uniform Resource Identifier,统一资源标识符
URL,Uniform Resource Locator,统一资源定位符
格式:协议://IP:端口(通常省略)/路径
例如当前web:写文章-CSDN创作中心![]() https://mp.csdn.net/mp_blog/creation/editor/134915118
https://mp.csdn.net/mp_blog/creation/editor/134915118
HTML,Hyper Text Markup Protocal 超文本传输语言
HTTP,Hyper Text Transfer Protocal 超文本传输协议,设计目的就是用来传输HTML的
默认端口80
HTTP通信过程
1,先进行tcp三次握手实现链接
2,然后进行HTTP的请求与响应
格式:

常用请求头和响应头:
请求头(Request Headers):
- Host:指定请求的目标主机和端口号。
- User-Agent:标识客户端软件的类型、版本号和操作系统等信息。
- Accept:指定客户端可接受的内容类型。
- Authorization:用于身份验证的凭据信息,比如用户名和密码。
- Cookie:包含客户端发送到服务器的HTTP Cookie信息。
- Referer:指示请求的来源页面的URL。
- Content-Type:指定请求体的媒体类型和字符集。
响应头(Response Headers):
- Content-Type:指定响应体的媒体类型和字符集。
- Content-Length:指定响应体的长度(以字节为单位)。
- Cache-Control:指定响应的缓存控制策略。
- Set-Cookie:服务器设置的HTTP Cookie信息。
- Location:指示客户端重定向的目标URL。
- Server:指示服务器的软件信息。
- ETag:指示资源的实体标签,用于缓存验证。
GET和POST的区别
GET 和 POST 是 HTTP 协议中最常用的两种请求方法,它们之间的主要区别如下:
-
get主要用来获取数据,而post是提交或修改数据
-
参数传递方式:
- GET:通过 URL 参数传递数据,参数会附加在 URL 的末尾,以
?开始,多个参数之间使用&分隔,如:http://example.com/search?q=keyword&page=1。因此,GET 请求的参数会暴露在 URL 中,对于敏感信息不太适合。 - POST:通过请求体(Request Body)传递数据,参数不会暴露在 URL 中,而是放在请求体中。POST 请求可以传递更多、更大的数据,也更适合传递文件等二进制数据。
- GET:通过 URL 参数传递数据,参数会附加在 URL 的末尾,以
-
数据长度限制:
- GET:由于数据是通过 URL 参数传递的,URL 的长度有限制,为2048个字节,因此 GET 请求传递的数据量有限。
- POST:由于数据是通过请求体传递的,没有长度限制(受服务器限制),可以传递较大的数据量,适合传递大量数据或文件。
-
缓存:
- GET:请求参数暴露在 URL 中,可以被浏览器缓存,如果请求相同的 URL,浏览器可能会直接从缓存中获取响应,而不发送实际的请求。
- POST:请求参数在请求体中,不会被浏览器缓存,每次请求都是实际发送的请求,不会从缓存中获取响应。
-
安全性:
- GET:因为参数暴露在 URL 中,不适合传递敏感信息,如密码等,因为这些信息会被记录在服务器日志中、浏览器历史记录中等,存在安全风险。
- POST:参数在请求体中,相对安全,适合传递敏感信息,但仍需注意使用 HTTPS 等安全通道加密传输。
总的来说,GET 和 POST 在数据传输方式、数据长度限制、缓存、安全性等方面有所不同,根据具体的需求和场景选择合适的请求方法。通常来说,GET 适用于请求少量数据,无需保密的场景,而 POST 更适用于传递大量数据或敏感信息的场景。
Cookie和Session的区别与联系
联系:cookie和session都是用来跟踪浏览器用户身份的会话方式。
区别:
- cookie数据保存在客户端,session数据保存在服务端。
- cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗,如果主要考虑到安全应当使用session
- Cookie的存储容量通常为4KB左右,而Session的存储容量则没有明确的限制,通常由服务器的内存大小和配置参数决定。
http1.0和1.1的区别
HTTP/1.0和HTTP/1.1是HTTP协议的两个主要版本,它们在功能和性能方面有一些显著的区别:
-
持久连接(Persistent Connections):
- HTTP/1.0默认情况下是非持久连接的,每个请求/响应周期都需要建立一个新的TCP连接。这就意味着每次请求都要经历TCP连接的建立和关闭过程,效率较低。
- HTTP/1.1引入了持久连接的概念,即在单个TCP连接上可以传输多个HTTP请求和响应。这样可以避免重复建立和关闭连接的开销,提高了性能和效率。
-
管道化(Pipeline):
- HTTP/1.1支持管道化(Pipeline)机制,允许客户端在不等待响应的情况下发送多个请求。服务器可以按照请求的顺序返回响应,从而减少了网络延迟和提高了吞吐量。
- HTTP/1.0并不支持管道化,每个请求都需要等待上一个请求的响应返回后才能发送下一个请求。
-
缓存控制(Caching):
- HTTP/1.1对缓存的控制更加灵活,引入了更多的缓存控制头字段(如Cache-Control、Pragma、ETag等),以及对缓存的新鲜度和验证等机制。
- HTTP/1.0的缓存机制相对简单,主要通过Expires和Last-Modified等头字段控制缓存。
-
错误通知(Error Notification):
- HTTP/1.1引入了更多的错误状态码(如416、417等),以及更详细的错误信息,使得客户端和服务器能够更准确地识别和处理错误情况。
- HTTP/1.0的错误状态码相对较少,而且错误信息相对简略。
-
主机头字段(Host Header Field):
- HTTP/1.1中要求所有请求头中必须包含Host字段,以标识请求的目标主机。这样可以支持同一个IP地址上的多个虚拟主机,提高了服务器的灵活性和可扩展性。
- HTTP/1.0中并没有Host字段的概念,因此无法支持多个虚拟主机共享同一个IP地址的情况。
总的来说,HTTP/1.1相对于HTTP/1.0在性能、功能和灵活性方面有较大的改进,使得网络通信更加高效、可靠和灵活。
http/2和http/1.x的区别
HTTP/2 相比于 HTTP/1.x,引入了一些重要的变化和改进,主要包括以下几个方面的区别:
-
多路复用(Multiplexing):
- HTTP/2 允许多个请求和响应消息在一个 TCP 连接上同时交错传输,而不像 HTTP/1.x 需要为每个资源请求建立一个新的连接。这样可以减少连接的建立和关闭开销,提高网络利用率。
-
头部压缩(Header Compression):
- HTTP/2 使用 HPACK 算法对消息头部进行压缩,减少了消息头部的大小,降低了网络传输的开销。这样可以减少每个请求和响应的传输数据量,提高传输效率。
-
服务器推送(Server Push):
- HTTP/2 允许服务器在客户端请求之前推送资源到客户端缓存中,从而减少客户端请求的延迟。服务器可以根据客户端请求的资源类型预测性地推送相关的资源,提高页面加载速度。
-
二进制协议(Binary Protocol):
- HTTP/2 使用二进制格式而不是文本格式来编码和传输数据,这样可以提高解析效率和传输速度。相比于 HTTP/1.x 的明文格式,二进制格式更加紧凑和高效。
-
流(Stream)和优先级(Priority):
- HTTP/2 中引入了流的概念,一个 HTTP/2 连接可以包含多个流,每个流都可以承载多个消息。此外,HTTP/2 还支持对流的优先级设置,可以根据资源的重要性和依赖关系优先处理。
综上所述,HTTP/2 相比于 HTTP/1.x 在性能、效率和功能方面都有了显著的改进,可以提供更快的页面加载速度、更高的网络利用率和更好的用户体验。
HTTPS,Hyper Text Transfer Protocal Secure
HTTPS (Hyper Text Transfer Protocol over SecureSocket Layer):
HTTPS 是一种应用层协议,是一种透过计算机网络进行安全通信的传输协议。
HTTPS 经由 HTTP 进行通信,但是在 HTTP 的基础上引入了一个加密层,使用 SSL/TLS 来加密数据包
HTTPS 开发的主要目的,是提供对网站服务器的身份认证,保护交换数据的隐私与完整性。
HTTPS 默认工作在 TCP 协议443端口
在HTTP基础上使用SSL/TLS加密报文,默认端口443
TSL Transport Layer Security 传输层安全协议,前身为SSL Secure Sockets Layer安全套接层
其工作应用层和传输层之间,如图所示:
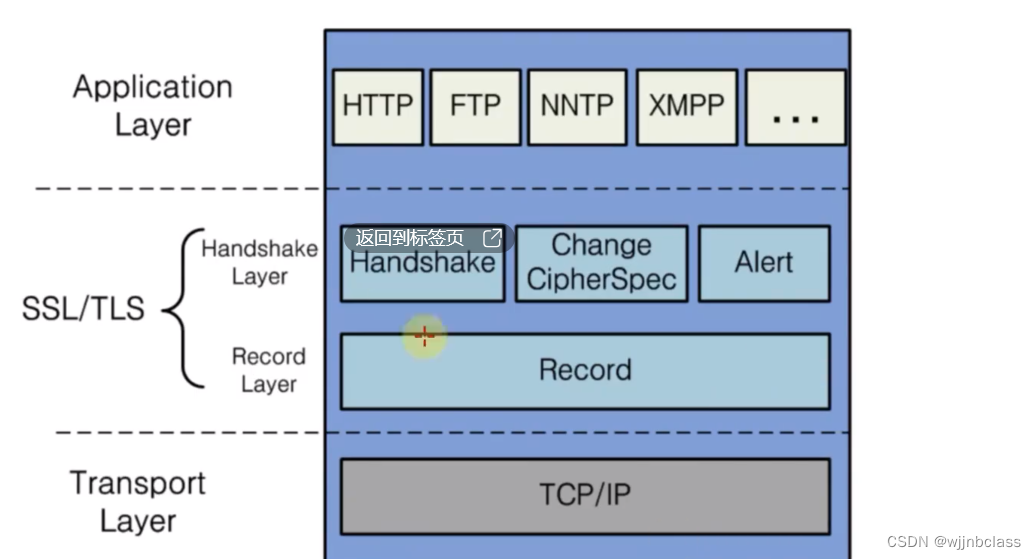
3. HTTPS 的工作原理
既然要保证数据安全,就需要进行“加密”,即网络传输中不再直接传输明文,而是加密之后的“密文”。加密的方式有很多,但是整体可以分为两大类:对称加密和非对称加密
3.1 引入对称加密
基本介绍:
对称加密其实就是只通过一个密钥,把明文加密成密文,并且也能把密文解密成明文
如使用异或操作,就可以实现一个简单的对称加密。设明文为 1234,密钥为 8888。通过明文和密钥异或操作实现加密 1234 ^ 8888,得到密文为 9834。然后通过密文和密钥异或操作解密 9834 ^ 8888,得到明文 1234
只引入对称加密存在的问题:
通过对称加密,貌似就可以进行数据的保护了。黑客就算入侵了路由器,也只能得到请求的密文内容
但是上述方案有一个问题,就是密钥如何进行约定?毕竟一个服务器对应着很多的客户端,每个客户端和服务器之间都需要约定一个独自的密钥。
可如果让服务器管理所有的密钥,其实并不简单,因此更好的做法就是客户端连接过来时,就自带一个客户端生成好的密钥。当每个客户端在连接之前,自己先生成一个密钥,通过网络将该信息告诉服务器,服务器将这个密钥保存即可。
也正是因为如此,黑客在获取密文请求的同时,也获取到了密钥,因此只使用对称加密并不能起到数据保护的作用。所以还需要让密钥进行加密,但是使用对称加密的话,是行不通的,故引入了非对称加密
3.2 引入非对称加密
基本介绍:
非对称加密要额外再用到两个密钥,一个叫做==“公钥”,一个叫做”私钥“。公钥和私钥是配对的==,这对密钥由服务器产生。
缺点:
运算速度非常慢,比对称加密慢很多
引入流程:
服务器将公钥直接发送给客户端,将私钥保留。客户端得到公钥后,通过公钥将双方打算使用的密钥进行加密,再发送给服务器,服务器通过私钥解密获取到这个密钥(只有私钥才能解出公钥加密的内容)。之后再将收到密钥的消息通过密钥加密后发送给客户端,客户端收到后,就使用该密钥通过对称加密的方式与客户端进行数据传输
引入非对称加密后,为什么还要使用对称加密?
由于对称加密的成本(对机器资源的消耗)远远低于非对称加密,而实际上客户端和服务器之间传输的数据量会很大,如果都使用非对称加密,整体的传输速度就会很慢,因此通过非对称加密,让服务器得到密钥后,再使用对称加密进行传输,能够提高传输的效率
引入非对称加密后还存在的问题:
服务器首先生成一对公钥A和私钥A。首先服务器要把公钥A发送给客户端,此时黑客可以当作一个中间人,自己生成一对公钥B和私钥B。他会将服务器的信息阶段,并将自己生成的公钥B发送给客户端。当客户端得到公钥B后,就使用公钥B加密自己生成的密钥A并发送给服务器。此时黑客再次截取,通过私钥B解密公钥B,得到密钥A,并使用公钥A将密钥进行加密返回给服务器。至此服务器和客户端都确定了密钥A,但黑客也神不知鬼不觉的知道了密钥A。故在之后的数据传输中,黑客就可以直接完全的获取客户端和服务器的明文数据。因此即使引入了非对称机密还是存在两个问题:
客户端如何获取到公钥?
客户端如何确定这个公钥不是黑客伪造的?
为了解决这两个问题,就引入了证书
3.3 引入证书机制
基本介绍:
在客户端和服务器刚建立连接时,服务器就给客户端返回一个证书。这个证书就好比人的身份证,用来作为网站的身份标识。而每搭建一个 HTTPS 网址时都需要在 CA 机构申请一个证书。
证书含有的重要信息:
证书发布机构
证书有效期
公钥
证书所有者
签名
引入证书流程:
服务器首先产生一对公钥和私钥,在第三方公证机构申请一个证书时,该证书内就包含了公钥的信息,然后服务器就会将公钥发送给客户端,由于证书的校验很严格,因此黑客就算获取了,也很难伪造一个假的证书。即使伪造了,客户端也可以拿到第三方公证机构去校验,因此客户端就能够拿到服务器发送的公钥,之后再通过公钥加密自己产生的密钥,发送给服务器。由于黑客没有私钥,就算截获了该请求,也不能拿到密钥,因此服务器就能顺利的得到加密的密钥,并使用私钥来解密。最终就能够很好的防止黑客获取或篡改数据。
校验证书方式:
判定证书的有效期是否过期
判定证书的发布机构是否受信任
判定证书是否被篡改(从系统中拿到该证书发布机构的公钥,对签名解密,得到一个 hash 值(称为数据摘要),设为 hash1。然后计算整个证书的 hash 值,设为 hash2。对比 hash1 和 hash2 是否相等,如果相等,则说明证书是没有被篡改过的)
理解数据值摘要和签名:
针对一段数据,可以通过一些特定的算法对这个数据生成一个签名。由于不同的数据生成的签名差别很大,因此就可以使用签名在一定程度上区分不同的数据。常见的生成签名的算法有:MD5 和 SHA,以下以 MD5 为例,介绍其特点
定长:无论多长的字符串,计算出来的 MD5 值都是固定长度(16字节版本或者32字节版本)
分散:源字符串只要改变一点点,最终得到的 MD5 值都会差别很大
不可逆:通过源字符串生成 MD5 很容易,但是通过 MD5 还原成原串理论上是不可能的
由于 MD5 这样的特性,因此可以认为如果两段数据的 MD5 值相同,则这两段数据相同
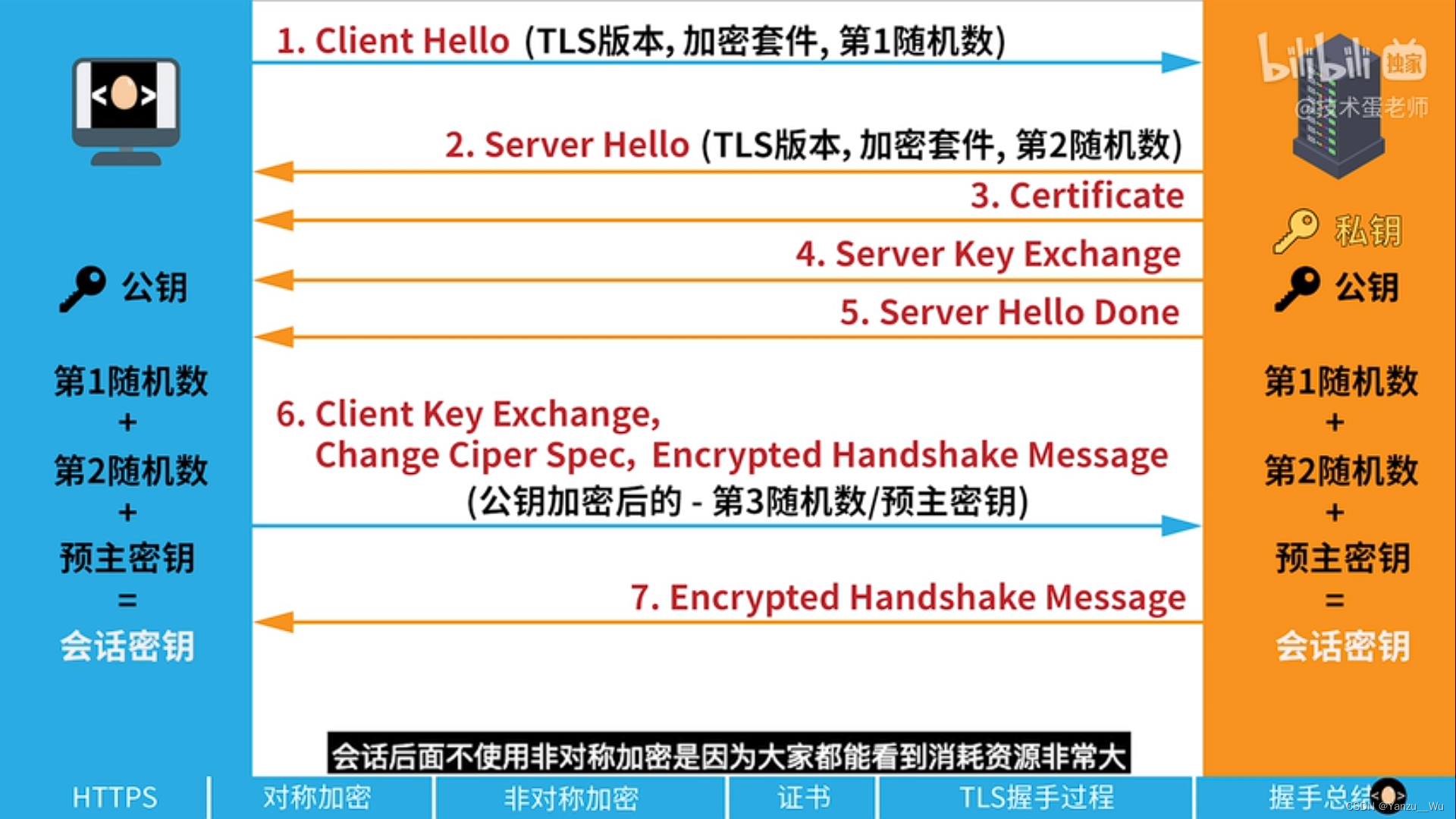
3.4 完整流程
1,通过Tcp三次握手建立连接T
2,通过TLS握手建立连接(这一步为非对称加密,目的是获取之后进行对称加密的密钥)
对称加密: 需要有一个客户端生成的对称密钥,用于对传输的数据进行加密,但需要将该对称密钥告知给服务器
非对称加密: 服务器提供一个公钥(自己持有私钥),将公钥传发送给客户端,客户端使用公钥对对称密钥进行加密,将密文传送给服务器
引入证书机制: 通过第三方公证机构,向网站颁发证书,该证书里面就含有公钥。客户端向服务器请求的也就是证书,客户端拿到证书后去公证机构校验,如果证书合法,就使用里面的公钥对对称密钥进行加密
————————————————
原文链接:https://blog.csdn.net/weixin_51367845/article/details/123385750
使用HTTPS是有成本的
1,证书费用 2,需要进行加解密计算 3,降低了访问速度
HTTPS通信过程
1,先进行tcp三次握手实现链接
2,TLS连接
3,然后进行HTTP的请求与响应
FTP
FTP(File Transfer Protocol,文件传输协议)是一种用于在计算机网络上进行文件传输的标准协议。它允许用户通过网络连接到远程计算机上,并在本地计算机和远程计算机之间传输文件。
以下是 FTP 协议的一般工作流程和特点:
-
客户端-服务器模型:
- FTP 使用客户端-服务器模型,客户端负责发起文件传输请求,而服务器负责响应这些请求并提供文件服务。
-
两种连接模式:
- FTP 支持两种连接模式:主动模式(Active Mode)和被动模式(Passive Mode)。在主动模式下,客户端发起数据连接;在被动模式下,服务器发起数据连接。
-
两个 TCP 连接:
- FTP 使用两个 TCP 连接来进行文件传输,一个用于控制连接(Control Connection),用于发送命令和接收响应;另一个用于数据连接(Data Connection),用于实际传输文件数据。
-
支持匿名登录和身份验证:
- FTP 支持匿名登录,用户可以使用匿名账户登录到 FTP 服务器并下载公共文件。此外,FTP 也支持身份验证机制,可以使用用户名和密码进行登录。
-
支持多种操作:
- FTP 不仅支持文件的上传和下载,还支持文件的创建、删除、重命名、目录的创建和删除等操作,使其成为一个完整的文件管理协议。
-
传输数据不加密:
- FTP 是一种明文传输协议,传输的数据不会进行加密,存在被窃听的风险。为了提高安全性,可以使用 FTPS(FTP over SSL/TLS)或 SFTP(SSH File Transfer Protocol)等加密传输协议。
总的来说,FTP 是一种广泛使用的文件传输协议,它简单、高效,适用于在计算机网络上进行文件传输和管理。然而,由于其传输数据不加密的特点,需要注意保护数据的安全性
SMTP
SMTP(Simple Mail Transfer Protocol,简单邮件传输协议)是用于在计算机网络上发送电子邮件的标准协议。SMTP 定义了邮件的传输规则和格式,它负责将发送者的电子邮件消息传递给接收者的邮件服务器。
以下是 SMTP 协议的一般工作流程和特点:
-
客户端-服务器模型:
- SMTP 使用客户端-服务器模型,客户端负责发送电子邮件消息,而服务器负责接收和传输这些消息。
-
基于文本的协议:
- SMTP 是一种基于文本的协议,它使用简单的文本命令来控制邮件的传输过程。常见的 SMTP 命令包括 HELO(标识客户端)、MAIL FROM(指定发件人)、RCPT TO(指定收件人)、DATA(开始传输邮件内容)、QUIT(结束会话)等。
-
使用 TCP 协议:
- SMTP 使用 TCP 协议进行通信,SMTP 客户端通过连接到 SMTP 服务器的 25 端口来发送邮件。
-
逐跳传输:
- SMTP 使用逐跳传输的方式来传输邮件,即通过一系列中间邮件服务器将邮件从发送者传递给接收者。每个邮件服务器都负责将邮件传递给下一个邮件服务器,直到达到目的地。
-
支持身份验证:
- SMTP 支持身份验证机制,以确保邮件只能由授权用户发送。常见的身份验证方式包括基于口令的身份验证(如PLAIN、LOGIN)和基于证书的身份验证(如CRAM-MD5)等。
-
不负责邮件的存储和检索:
- SMTP 只负责将邮件从发送者传递给接收者的邮件服务器,不负责邮件的存储和检索。邮件的存储和检索通常由 POP3(Post Office Protocol version 3)或 IMAP(Internet Message Access Protocol)等协议来完成。
总的来说,SMTP 是一种用于在计算机网络上发送电子邮件的标准协议,它简单、高效,并且可以与其他邮件相关的协议配合使用,实现完整的电子邮件系统。















 787
787











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









