






CDN作为一种分布式缓存加速服务,对于访问量级大的区域,单个节点带宽建设一般可达百Gb量级,对外配置虚拟IP提供服务,节点内部需要通过多层负载均衡(LB)将请求分发到内部的若干台服务器进行处理。一般情况下,我们使用LVS作为四层负载均衡(L4LB),使用Nginx作为七层负载均衡(L7LB),节点配置如图。
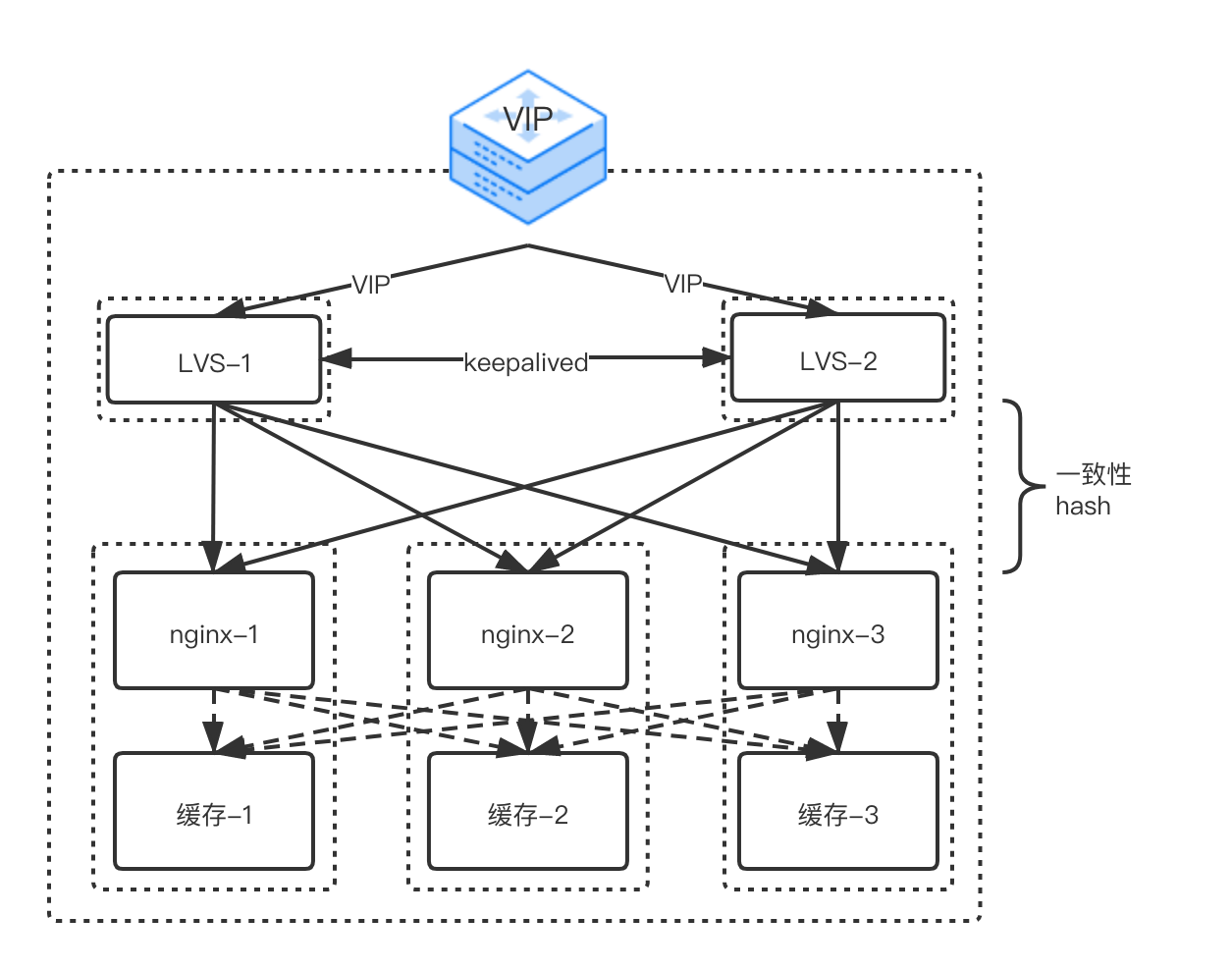
传统的L4LB需要对每个入站数据包进行处理,其性能决定了访问延迟和后端服务器扩展性,主要包括下面组件:
- VIP通告:该组件与L4LB前面的网络元件(通常是交换机)对等互联,向外界通告L4LB负责的虚拟IP地址。然后,交换机使用等价多路径(ECMP)机制,在通告VIP的L4LB之间分配数据包。
- 后端服务器选择:为了将来自客户端的所有数据包发送到同一个后端,L4LB使用一致性哈希,该哈希取决于入站数据包的5元组(源地址、源端口、目的地地址、目的地端口和协议)。使用一致性哈希可确保属于传输连接的所有数据包都被发送到同一个后端,不管接收数据包的L4LB是哪个。这就不需要跨多个L4LB的任何状态同步。一致性哈希还保证后端离开或加入后端池时对现有连接的干扰最小。
- 转发平面:一旦L4LB选择了适当的后端,数据包需要被转发到该主机。为了避免限制(比如L4LB和后端主机要在同一个L2域),使用了简单的IP-in-IP封装。后端经过了配置,确保lo接口上有相应的VIP。这让后端得以将返回路径上的数据包直接发送到客户端(而不是L4LB)。这种优化常常名为直接服务器返回(DSR),让L4LB只受入站数据包数量的限制。
由于L4LB是在内核传输层对数据包进行流量转发操作,属于CPU密集型计算,这就带来了一个矛盾,为了不影响正常的七层服务性能,需要将L4LB和L7LB拆分部署,专门采购若干台辅助机配置L4LB进行流量负载(目前单个节点内配置两台一主一备,费用数十万),同时由于引入了新的传输路径又会造成访问延迟,导致服务质量下降。
为了解决上述问题,谷歌开发并开源了一套Katran转发平面软件库,提供了基于软件的负载均衡解决方案,最终实现了L4LB/L7LB的同机部署。完全重新设计的转发平台充分利用了内核工程方面最近的两个创新:eXpress数据路径(XDP)和eBPF虚拟机。
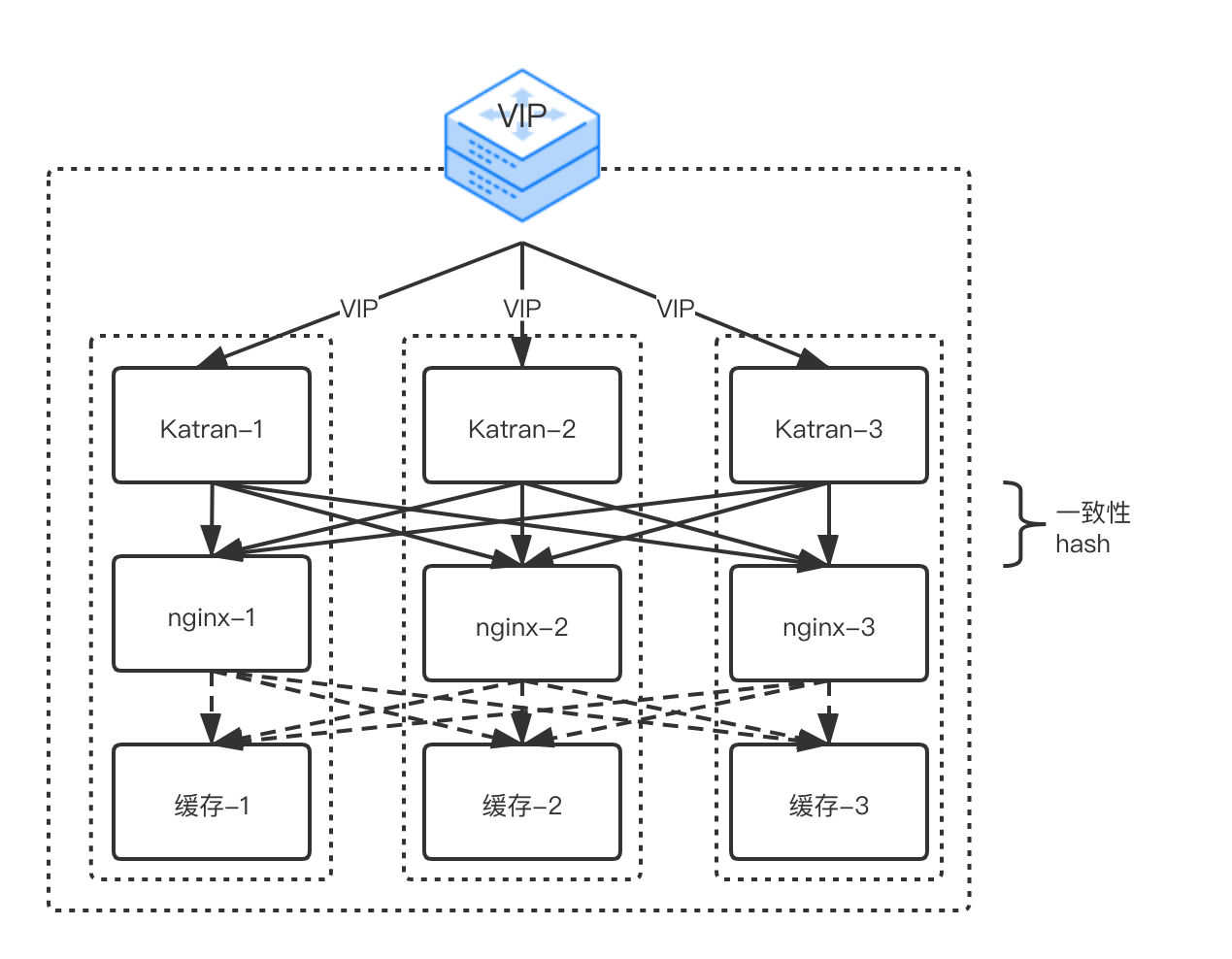
该系统的总体架构与传统L4LB相似:首先,ExaBGP向外界通告某一个Katran实例负责哪个VIP;其次,发往VIP的数据包使用ECMP机制发送到Katran实例;最后,Katran选择一个后端,将数据包转发到正确的后端服务器。主要区别在于最后一步。
- 及早高效的数据包处理:结合使用Linux内核中XDP与BPF程序来转发数据包。
- 成本低廉但更稳定的哈希:使用Maglev哈希的扩展版来选择后端服务器。扩展版哈希的几项功能是,遇到后端服务器故障后可迅速恢复,更均匀地分配负载以及能够为不同的后端服务器设置不等的权重。
- 更有弹性的本地状态:Katran处理数据包和计算哈希方面很高效,将查找表实施成LRU驱逐缓存。LRU缓存大小在启动时可加以配置,充当可调参数,在计算和查找之间求得平衡。
- 对RSS友好的封装:接收端扩展(RSS)是网卡中的一个重要优化,旨在通过将来自每路数据流的数据包转发到单独的CPU,从而在CPU之间均匀地分配负载。
这些功能显著增强了L4LB的性能、灵活性和可扩展性。如果没有入站数据包,Katran的设计还消除了几乎不耗用任何CPU的接收路径上的繁忙循环。为了降低节点建设成本同时提高用户体验,目前CDN基于Katran的节点配置方案正在逐步上线验证中,在此对其中的一些实践经验进行说明。
1. eBPF基础
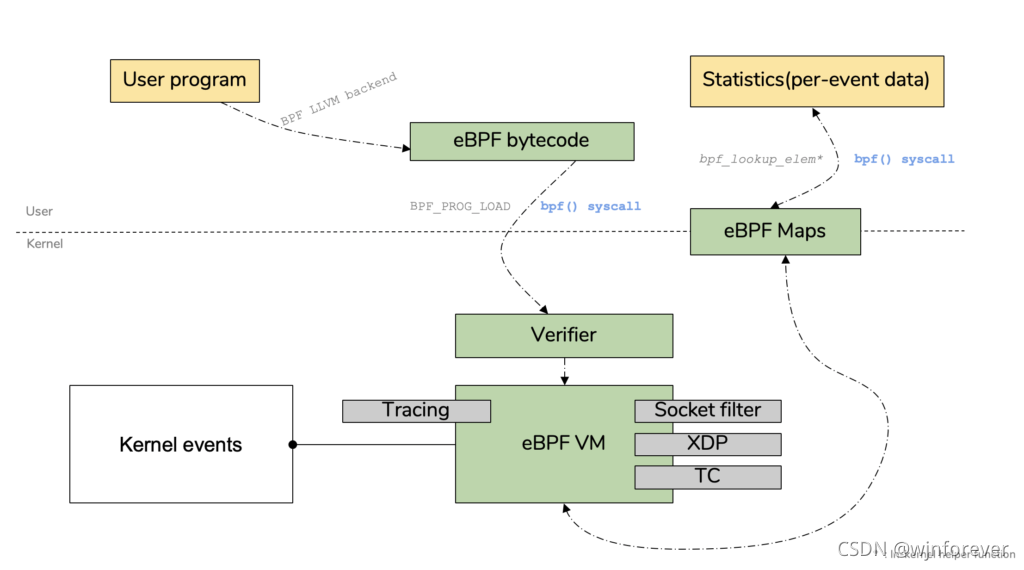
最初的[Berkeley Packet Filter (BPF)]是为捕捉和过滤符合特定规则的网络包而设计的,过滤器为运行在基于寄存器的虚拟机上的程序。eBPF是kernel 3.15中引入的全新设计,将原先的BPF发展成一个指令集更复杂、应用范围更广的“内核虚拟机”。一个eBPF程序会附加到指定的内核代码路径中,当执行该代码路径时,会执行对应的eBPF程序。鉴于它的起源,eBPF特别适合编写网络程序,将该网络程序附加到网络socket,进行流量过滤,流量分类以及执行网络分类器的动作。
1.1 XDP
XDP这个项目是专门使用eBPF来执行高性能数据包处理,方法是在收到数据包之后,立即在网络栈的最低层执行eBPF程式。几种内核旁路技术(DPDK是最主要的一种)旨在通过将数据包处理移至用户空间来加速网络操作。这意味着放弃内核用户空间边界之间的上下文切换,系统调用转换或IRQ请求所引起的开销。操作系统将对网络堆栈的控制权移交给用户空间进程,这些进程通过它们自己的驱动程序直接与NIC交互。
XDP快速处理路径的关键点是,在数据包到达网络适配器接收(RX)队列之后,字节码就附加在了网络堆栈的最早位置。在网络堆栈的这一阶段,还没有建立内核数据包特征,这有助于在数据包处理路径中获得巨大的速度。
引入XDP之后网络Data Path
在没有引入XDP之前,原来是的网络数据包传输路径是这样的:

启用XDP后,网络包传输路径是这样的:
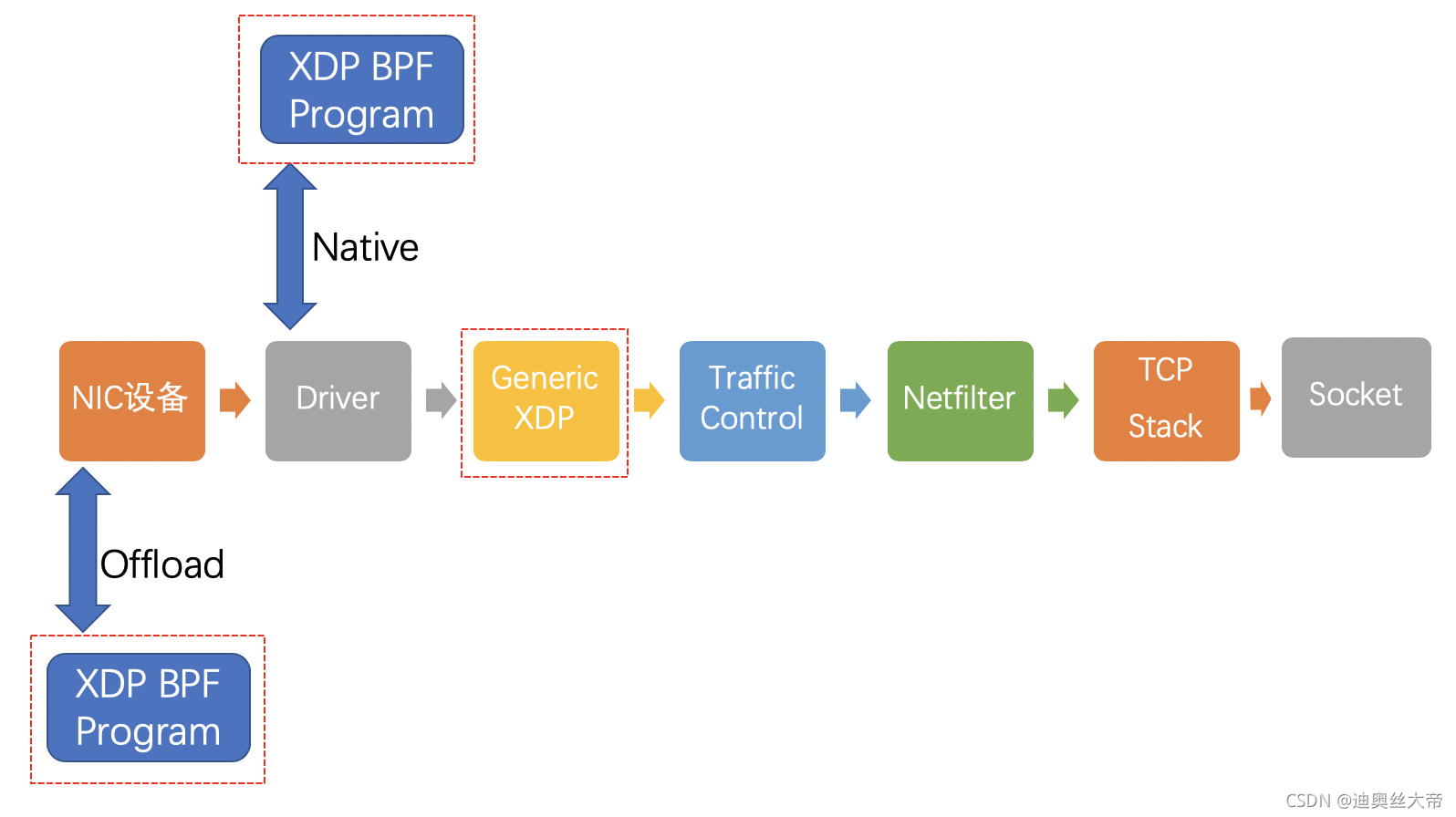
XDP支持三种工作模式
Offload模式
XDP程序直接hook到可编程网卡硬件设备上,与其他两种模式相比,它的处理性能最强;由于处于数据链路的最前端,过滤效率也是最高的。如果需要使用这种模式,需要在加载程序时明确声明。目前支持这种模式的网卡设备不多,有一家叫netronome。
Native模式
XDP程序hook到网络设备的驱动上,它是XDP最原始的模式,在数据被网卡硬件DMA到内存,分配skb之前,对数据包进行处理。由于完全不存在锁操作,且bypass了协议栈,非常适合用修改数据包并转发,数据探针,执行丢包。目前已知的有i40e, nfp, mlx系列和ixgbe系列支持Native模式。为实现这一机制而更新的驱动程序并没有创建一个完整的skb,把最少的信息量放到一个假的、静态分配的skb中。这样就避免了开销,但代价是创建了一个不是真正skb的skb。
Generic模式
这是操作系统内核提供的通用XDP兼容模式,它可以在没有硬件或驱动程序支持的主机上执行XDP程序。在这种模式下,XDP的执行是由操作系统本身来完成的,以模拟Native模式执行。好处是,只要内核够高,人人都能玩XDP;缺点是由于是仿真执行,需要分配额外的套接字缓冲区skb,导致处理性能下降,跟Native模式在10倍左右的差距。
当前主流内核版本的Linux系统在加载XDP BPF程序时,会自动在Native和Generic这两种模式选择,完成加载后,可以使用ip命令行工具来查看选择的模式。我们主要关注的也是这两种模式。
以Linux 4.19/i40e系列为例,说明用户程序(Katran)配置XDP到网卡的流程和代码运行机制:
- 程序加载
用户程序(Katran)通过netlink机制将XDP程序加载到指定的网络设备上
NetlinkMessage NetlinkMessage::XDP(unsigned seq, int prog_fd, unsigned ifindex, uint32_t flags) {
...
// Construct netlink message header
nlh = mnl_nlmsg_put_header(buf);
nlh->nlmsg_type = RTM_SETLINK;
nlh->nlmsg_flags = NLM_F_REQUEST | NLM_F_ACK;
nlh->nlmsg_seq = seq;
// Construct ifinfo message header
ifinfo = reinterpret_cast<struct ifinfomsg*>(
mnl_nlmsg_put_extra_header(nlh, sizeof(struct ifinfomsg)));
ifinfo->ifi_family = AF_UNSPEC;
// 指定XDP挂载的网卡
ifinfo->ifi_index = ifindex;
// Additional nested attribues
{
struct nlattr* xdp_atr = mnl_attr_nest_start(nlh, IFLA_XDP);
// 消息中设置XDP程序的fd
mnl_attr_put_u32(nlh, IFLA_XDP_FD, prog_fd);
if (flags > 0) {
mnl_attr_put_u32(nlh, IFLA_XDP_FLAGS, flags);
}
mnl_attr_nest_end(nlh, xdp_atr);
}
...
}内核收到消息后,在net/core/rtnetlink.c文件中的rtnl_setlink调用do_setlink
static int do_setlink(const struct sk_buff *skb,
struct net_device *dev, struct ifinfomsg *ifm,
struct netlink_ext_ack *extack,
struct nlattr **tb, char *ifname, int status) {
...
if (tb[IFLA_XDP]) {
struct nlattr *xdp[IFLA_XDP_MAX + 1];
u32 xdp_flags = 0;
err = nla_parse_nested(xdp, IFLA_XDP_MAX, tb[IFLA_XDP],
ifla_xdp_policy, NULL);
if (err < 0)
goto errout;
if (xdp[IFLA_XDP_ATTACHED] || xdp[IFLA_XDP_PROG_ID]) {
err = -EINVAL;
goto errout;
}
if (xdp[IFLA_XDP_FLAGS]) {
xdp_flags = nla_get_u32(xdp[IFLA_XDP_FLAGS]);
if (xdp_flags & ~XDP_FLAGS_MASK) {
err = -EINVAL;
goto errout;
}
if (hweight32(xdp_flags & XDP_FLAGS_MODES) > 1) {
err = -EINVAL;
goto errout;
}
}
if (xdp[IFLA_XDP_FD]) {
err = dev_change_xdp_fd(dev, extack,
nla_get_s32(xdp[IFLA_XDP_FD]),
xdp_flags);
if (err)
goto errout;
status |= DO_SETLINK_NOTIFY;
}
}
...
}do_setlink最后调用dev_change_xdp_fd,检查后调用dev_xdp_install
int dev_change_xdp_fd(struct net_device *dev, struct netlink_ext_ack *extack,
int fd, u32 flags)
{
const struct net_device_ops *ops = dev->netdev_ops;
enum bpf_netdev_command query;
struct bpf_prog *prog = NULL;
bpf_op_t bpf_op, bpf_chk;
int err;
ASSERT_RTNL();
query = flags & XDP_FLAGS_HW_MODE ? XDP_QUERY_PROG_HW : XDP_QUERY_PROG;
// 用户态可通过flags设置XDP运行模式
// 读取驱动配置的ndo_bpf接口
bpf_op = bpf_chk = ops->ndo_bpf;
if (!bpf_op && (flags & (XDP_FLAGS_DRV_MODE | XDP_FLAGS_HW_MODE)))
return -EOPNOTSUPP;
if (!bpf_op || (flags & XDP_FLAGS_SKB_MODE))
bpf_op = generic_xdp_install;
if (bpf_op == bpf_chk)
bpf_chk = generic_xdp_install;
if (fd >= 0) {
if (__dev_xdp_query(dev, bpf_chk, XDP_QUERY_PROG) ||
__dev_xdp_query(dev, bpf_chk, XDP_QUERY_PROG_HW))
return -EEXIST;
if ((flags & XDP_FLAGS_UPDATE_IF_NOEXIST) &&
__dev_xdp_query(dev, bpf_op, query))
return -EBUSY;
prog = bpf_prog_get_type_dev(fd, BPF_PROG_TYPE_XDP,
bpf_op == ops->ndo_bpf);
if (IS_ERR(prog))
return PTR_ERR(prog);
if (!(flags & XDP_FLAGS_HW_MODE) &&
bpf_prog_is_dev_bound(prog->aux)) {
NL_SET_ERR_MSG(extack, "using device-bound program without HW_MODE flag is not supported");
bpf_prog_put(prog);
return -EINVAL;
}
}
// 1. Native模式: bpf_op = ops->ndo_bpf
// 2. Generic模式: bpf_op = generic_xdp_install
err = dev_xdp_install(dev, bpf_op, extack, flags, prog);
if (err < 0 && prog)
bpf_prog_put(prog);
return err;
}static int dev_xdp_install(struct net_device *dev, bpf_op_t bpf_op,
struct netlink_ext_ack *extack, u32 flags,
struct bpf_prog *prog)
{
struct netdev_bpf xdp;
memset(&xdp, 0, sizeof(xdp));
if (flags & XDP_FLAGS_HW_MODE)
xdp.command = XDP_SETUP_PROG_HW;
else
xdp.command = XDP_SETUP_PROG;
xdp.extack = extack;
xdp.flags = flags;
xdp.prog = prog;
// 1. Native模式: bpf_op = ops->ndo_bpf
// 2. Generic模式: bpf_op = generic_xdp_install
return bpf_op(dev, &xdp);
}当设置为Native模式时,通过i40e_xdp(驱动提供的ndo_bpf接口)加载XDP到驱动内运行
static int i40e_xdp(struct net_device *dev,
struct netdev_bpf *xdp)
{
struct i40e_netdev_priv *np = netdev_priv(dev);
struct i40e_vsi *vsi = np->vsi;
if (vsi->type != I40E_VSI_MAIN)
return -EINVAL;
switch (xdp->command) {
case XDP_SETUP_PROG:
return i40e_xdp_setup(vsi, xdp->prog);
case XDP_QUERY_PROG:
xdp->prog_id = vsi->xdp_prog ? vsi->xdp_prog->aux->id : 0;
return 0;
default:
return -EINVAL;
}
}static int i40e_xdp_setup(struct i40e_vsi *vsi,
struct bpf_prog *prog)
{
int frame_size = vsi->netdev->mtu + ETH_HLEN + ETH_FCS_LEN + VLAN_HLEN;
struct i40e_pf *pf = vsi->back;
struct bpf_prog *old_prog;
bool need_reset;
int i;
/* Don't allow frames that span over multiple buffers */
if (frame_size > vsi->rx_buf_len)
return -EINVAL;
if (!i40e_enabled_xdp_vsi(vsi) && !prog)
return 0;
/* When turning XDP on->off/off->on we reset and rebuild the rings. */
need_reset = (i40e_enabled_xdp_vsi(vsi) != !!prog);
if (need_reset)
i40e_prep_for_reset(pf, true);
// 将vsi->xdp_prog设置为XDP程序
old_prog = xchg(&vsi->xdp_prog, prog);
if (need_reset)
i40e_reset_and_rebuild(pf, true, true);
// 将vsi->rx_rings[i]->xdp_prog设置为XDP程序
for (i = 0; i < vsi->num_queue_pairs; i++)
WRITE_ONCE(vsi->rx_rings[i]->xdp_prog, vsi->xdp_prog);
if (old_prog)
bpf_prog_put(old_prog);
return 0;
}当设置为Generic模式时,通过generic_xdp_install加载XDP到skb创建之后运行
static int generic_xdp_install(struct net_device *dev, struct netdev_bpf *xdp)
{
struct bpf_prog *old = rtnl_dereference(dev->xdp_prog);
struct bpf_prog *new = xdp->prog;
int ret = 0;
switch (xdp->command) {
case XDP_SETUP_PROG:
// 将dev->xdp_prog设置为XDP程序
rcu_assign_pointer(dev->xdp_prog, new);
if (old)
bpf_prog_put(old);
if (old && !new) {
static_branch_dec(&generic_xdp_needed_key);
} else if (new && !old) {
static_branch_inc(&generic_xdp_needed_key);
dev_disable_lro(dev);
dev_disable_gro_hw(dev);
}
break;
case XDP_QUERY_PROG:
xdp->prog_id = old ? old->aux->id : 0;
break;
default:
ret = -EINVAL;
break;
}
return ret;
}- XDP运行
ksoftirqd软中断线程开始处理NET_RX_SOFTIRQ,首先获取到当前CPU变量softnet_data,对其poll_list进行遍历,然后执行网卡驱动注册的poll函数。
对于i40e来说,就是驱动里的i40e_napi_poll,把数据帧从RingBuffer中取出准备发往协议栈。
int i40e_napi_poll(struct napi_struct *napi, int budget)
i40e_for_each_ring(ring, q_vector->rx) {
int cleaned = i40e_clean_rx_irq(ring, budget_per_ring);
...
}static int i40e_clean_rx_irq(struct i40e_ring *rx_ring, int budget) {
...
while (likely(total_rx_packets < (unsigned int)budget)) {
...
if (!skb) {
xdp.data = page_address(rx_buffer->page) +
rx_buffer->page_offset;
xdp.data_meta = xdp.data;
xdp.data_hard_start = xdp.data -
i40e_rx_offset(rx_ring);
xdp.data_end = xdp.data + size;
// 网卡支持且XDP配置为Native模式,则在网卡刚把数据DMA到内存时执行XDP
skb = i40e_run_xdp(rx_ring, &xdp);
}
...
// Generic模式在分配skb之后执行
i40e_receive_skb(rx_ring, skb, vlan_tag);
...
}
}Native模式
static struct sk_buff *i40e_run_xdp(struct i40e_ring *rx_ring,
struct xdp_buff *xdp)
{
int err, result = I40E_XDP_PASS;
struct i40e_ring *xdp_ring;
struct bpf_prog *xdp_prog;
u32 act;
rcu_read_lock();
xdp_prog = READ_ONCE(rx_ring->xdp_prog);
// 如果没有注册xdp程序,则直接跳出处理流程
if (!xdp_prog)
goto xdp_out;
prefetchw(xdp->data_hard_start); /* xdp_frame write */
// 执行注册的xdp虚拟机
act = bpf_prog_run_xdp(xdp_prog, xdp);
switch (act) {
// 将数据上送协议栈
case XDP_PASS:
break;
// 将数据从同一个网口发送出去
case XDP_TX:
xdp_ring = rx_ring->vsi->xdp_rings[rx_ring->queue_index];
result = i40e_xmit_xdp_tx_ring(xdp, xdp_ring);
break;
// 将数据从另一个网口发送出去
case XDP_REDIRECT:
err = xdp_do_redirect(rx_ring->netdev, xdp, xdp_prog);
result = !err ? I40E_XDP_REDIR : I40E_XDP_CONSUMED;
break;
default:
bpf_warn_invalid_xdp_action(act);
/* fall through */
// 程序异常丢弃数据包
case XDP_ABORTED:
trace_xdp_exception(rx_ring->netdev, xdp_prog, act);
/* fall through -- handle aborts by dropping packet */
// 丢弃数据包
case XDP_DROP:
result = I40E_XDP_CONSUMED;
break;
}
xdp_out:
rcu_read_unlock();
return ERR_PTR(-result);
}外网网卡请求从内网网卡进行转发,因此用户态注入函数返回XDP_REDIRECT
int xdp_do_redirect(struct net_device *dev, struct xdp_buff *xdp,
struct bpf_prog *xdp_prog)
{
struct bpf_redirect_info *ri = this_cpu_ptr(&bpf_redirect_info);
struct bpf_map *map = READ_ONCE(ri->map);
struct net_device *fwd;
u32 index = ri->ifindex;
int err;
if (map)
return xdp_do_redirect_map(dev, xdp, xdp_prog, map);
fwd = dev_get_by_index_rcu(dev_net(dev), index);
ri->ifindex = 0;
if (unlikely(!fwd)) {
err = -EINVAL;
goto err;
}
err = __bpf_tx_xdp(fwd, NULL, xdp, 0);
if (unlikely(err))
goto err;
_trace_xdp_redirect(dev, xdp_prog, index);
return 0;
err:
_trace_xdp_redirect_err(dev, xdp_prog, index, err);
return err;
}static int __bpf_tx_xdp(struct net_device *dev,
struct bpf_map *map,
struct xdp_buff *xdp,
u32 index)
{
struct xdp_frame *xdpf;
int err, sent;
if (!dev->netdev_ops->ndo_xdp_xmit) {
return -EOPNOTSUPP;
}
err = xdp_ok_fwd_dev(dev, xdp->data_end - xdp->data);
if (unlikely(err))
return err;
xdpf = convert_to_xdp_frame(xdp);
if (unlikely(!xdpf))
return -EOVERFLOW;
sent = dev->netdev_ops->ndo_xdp_xmit(dev, 1, &xdpf, XDP_XMIT_FLUSH);
if (sent <= 0)
return sent;
return 0;
}调用目标网卡的ndo_xdp_xmit发包,对于i40e即是i40e_xdp_xmit
int i40e_xdp_xmit(struct net_device *dev, int n, struct xdp_frame **frames,
u32 flags)
{
struct i40e_netdev_priv *np = netdev_priv(dev);
unsigned int queue_index = smp_processor_id();
struct i40e_vsi *vsi = np->vsi;
struct i40e_ring *xdp_ring;
int drops = 0;
int i;
if (test_bit(__I40E_VSI_DOWN, vsi->state))
return -ENETDOWN;
if (!i40e_enabled_xdp_vsi(vsi) || queue_index >= vsi->num_queue_pairs)
return -ENXIO;
if (unlikely(flags & ~XDP_XMIT_FLAGS_MASK))
return -EINVAL;
xdp_ring = vsi->xdp_rings[queue_index];
for (i = 0; i < n; i++) {
struct xdp_frame *xdpf = frames[i];
int err;
// 传送XDP buffer到XDP ring通过DMA进行发送
err = i40e_xmit_xdp_ring(xdpf, xdp_ring);
if (err != I40E_XDP_TX) {
xdp_return_frame_rx_napi(xdpf);
drops++;
}
}
if (unlikely(flags & XDP_XMIT_FLUSH))
i40e_xdp_ring_update_tail(xdp_ring);
return n - drops;
}Generic模式
经过 i40e_receive_skb -> napi_gro_receive -> napi_skb_finish -> netif_receive_skb_internal
static int netif_receive_skb_internal(struct sk_buff *skb)
{
int ret;
net_timestamp_check(netdev_tstamp_prequeue, skb);
if (skb_defer_rx_timestamp(skb))
return NET_RX_SUCCESS;
if (static_branch_unlikely(&generic_xdp_needed_key)) {
int ret;
preempt_disable();
rcu_read_lock();
// Generic模式运行XDP,使用的是dev->xdp_prog
ret = do_xdp_generic(rcu_dereference(skb->dev->xdp_prog), skb);
rcu_read_unlock();
preempt_enable();
if (ret != XDP_PASS)
return NET_RX_DROP;
}
rcu_read_lock();
#ifdef CONFIG_RPS
if (static_key_false(&rps_needed)) {
struct rps_dev_flow voidflow, *rflow = &voidflow;
int cpu = get_rps_cpu(skb->dev, skb, &rflow);
if (cpu >= 0) {
ret = enqueue_to_backlog(skb, cpu, &rflow->last_qtail);
rcu_read_unlock();
return ret;
}
}
#endif
// 注意tcpdump注册的socket在之后才进入运行
ret = __netif_receive_skb(skb);
rcu_read_unlock();
return ret;
}int do_xdp_generic(struct bpf_prog *xdp_prog, struct sk_buff *skb)
{
if (xdp_prog) {
struct xdp_buff xdp;
u32 act;
int err;
act = netif_receive_generic_xdp(skb, &xdp, xdp_prog);
if (act != XDP_PASS) {
switch (act) {
case XDP_REDIRECT:
err = xdp_do_generic_redirect(skb->dev, skb,
&xdp, xdp_prog);
if (err)
goto out_redir;
break;
case XDP_TX:
generic_xdp_tx(skb, xdp_prog);
break;
}
return XDP_DROP;
}
}
return XDP_PASS;
out_redir:
kfree_skb(skb);
return XDP_DROP;
}int xdp_do_generic_redirect(struct net_device *dev, struct sk_buff *skb,
struct xdp_buff *xdp, struct bpf_prog *xdp_prog)
{
struct bpf_redirect_info *ri = this_cpu_ptr(&bpf_redirect_info);
struct bpf_map *map = READ_ONCE(ri->map);
u32 index = ri->ifindex;
struct net_device *fwd;
int err = 0;
if (map)
return xdp_do_generic_redirect_map(dev, skb, xdp, xdp_prog,
map);
ri->ifindex = 0;
fwd = dev_get_by_index_rcu(dev_net(dev), index);
if (unlikely(!fwd)) {
err = -EINVAL;
goto err;
}
err = xdp_ok_fwd_dev(fwd, skb->len);
if (unlikely(err))
goto err;
skb->dev = fwd;
_trace_xdp_redirect(dev, xdp_prog, index);
generic_xdp_tx(skb, xdp_prog);
return 0;
err:
_trace_xdp_redirect_err(dev, xdp_prog, index, err);
return err;
}跳过qdisc layer发送到目标网卡的tx ring
void generic_xdp_tx(struct sk_buff *skb, struct bpf_prog *xdp_prog)
{
struct net_device *dev = skb->dev;
struct netdev_queue *txq;
bool free_skb = true;
int cpu, rc;
txq = netdev_pick_tx(dev, skb, NULL);
cpu = smp_processor_id();
HARD_TX_LOCK(dev, txq, cpu);
if (!netif_xmit_stopped(txq)) {
rc = netdev_start_xmit(skb, dev, txq, 0);
if (dev_xmit_complete(rc))
free_skb = false;
}
HARD_TX_UNLOCK(dev, txq);
if (free_skb) {
trace_xdp_exception(dev, xdp_prog, XDP_TX);
kfree_skb(skb);
}
}XDP输入参数
XDP暴露的钩子具有特定的输入上下文,它是单一输入参数。它的类型为 struct xdp_md,在内核头文件bpf.h 中定义,具体字段如下所示:
/* user accessible metadata for XDP packet hook
* new fields must be added to the end of this structure
*/
struct xdp_md {
__u32 data;
__u32 data_end;
__u32 data_meta;
/* Below access go through struct xdp_rxq_info */
__u32 ingress_ifindex; /* rxq->dev->ifindex */
__u32 rx_queue_index; /* rxq->queue_index */
};程序执行时,data和data_end字段分别是数据包开始和结束的指针,它们是用来获取和解析传来的数据,第三个值是data_meta指针,初始阶段它是一个空闲的内存地址,供XDP程序与其他层交换数据包元数据时使用。最后两个字段分别是接收数据包的接口和对应的RX队列的索引。当访问这两个值时,BPF代码会在内核内部重写,以访问实际持有这些值的内核结构struct xdp_rxq_info。
XDP输出参数
在处理完一个数据包后,XDP程序会返回一个动作(Action)作为输出,它代表了程序退出后对数据包应该做什么样的最终裁决,也是在内核头文件bpf.h 定义了以下5种动作类型:
enum xdp_action {
XDP_ABORTED = 0, // Drop packet while raising an exception
XDP_DROP, // Drop packet silently
XDP_PASS, // Allow further processing by the kernel stack
XDP_TX, // Transmit from the interface it came from
XDP_REDIRECT, // Transmit packet from another interface
};可以看出这个动作的本质是一个int值。前面4个动作是不需要参数的,最后一个动作需要额外指定一个NIC网络设备名称,作为转发这个数据包的目的地。
1.2 TC(Traffic Control)
TC全称「Traffic Control」,直译过来是「流量控制」,专注于packet scheduler,所谓的网络包调度器,调度网络包的延迟、丢失、传输顺序和速度控制。
从内核4.1版本起,引入了一个特殊的qdisc,叫做clsact,它为TC提供了一个可以加载BPF程序的入口,使TC和XDP一样,成为一个可以加载BPF程序的网络钩子。
Katran利用TC bpf机制提供了健康检查的能力,但实际使用需要自定义业务逻辑进行增删改RealServer操作,在此仅做简单流程描述。
- XDP加载
用户程序(Katran)通过netlink机制创建clsact qdisc到指定网络设备
addClsActQD(ifindex);
之后再通过netlink机制加载TC bpf程序到clsact qdisc
// direction: TC_EGRESS
NetlinkMessage NetlinkMessage::TC(
unsigned seq,
int cmd,
unsigned flags,
uint32_t priority,
int prog_fd,
unsigned ifindex,
const std::string& bpf_name,
int direction)- XDP运行
对于Egress方向的TC bpf逻辑,运行于网络设备子系统中dev_queue_xmit -> __dev_queue_xmit -> sch_handle_egress -> tcf_classify,最终调用cls_bpf_classify
static int cls_bpf_classify(struct sk_buff *skb, const struct tcf_proto *tp,
struct tcf_result *res)
{
struct cls_bpf_head *head = rcu_dereference_bh(tp->root);
bool at_ingress = skb_at_tc_ingress(skb);
struct cls_bpf_prog *prog;
int ret = -1;
/* Needed here for accessing maps. */
rcu_read_lock();
list_for_each_entry_rcu(prog, &head->plist, link) {
int filter_res;
qdisc_skb_cb(skb)->tc_classid = prog->res.classid;
if (tc_skip_sw(prog->gen_flags)) {
filter_res = prog->exts_integrated ? TC_ACT_UNSPEC : 0;
} else if (at_ingress) {
/* It is safe to push/pull even if skb_shared() */
__skb_push(skb, skb->mac_len);
bpf_compute_data_pointers(skb);
filter_res = BPF_PROG_RUN(prog->filter, skb);
__skb_pull(skb, skb->mac_len);
} else {
bpf_compute_data_pointers(skb);
// 执行eBPF(classifier/filter)
filter_res = BPF_PROG_RUN(prog->filter, skb);
}
// prog->exts_integrated为 true 时表示 direct-action 模式
if (prog->exts_integrated) {
res->class = 0;
res->classid = TC_H_MAJ(prog->res.classid) |
qdisc_skb_cb(skb)->tc_classid;
ret = cls_bpf_exec_opcode(filter_res);
if (ret == TC_ACT_UNSPEC)
continue;
break;
}
if (filter_res == 0)
continue;
if (filter_res != -1) {
res->class = 0;
res->classid = filter_res;
} else {
*res = prog->res;
}
ret = tcf_exts_exec(skb, &prog->exts, res);
if (ret < 0)
continue;
break;
}
rcu_read_unlock();
return ret;
}TC 输入参数
TC接受单个输入参数,类型为struct __sk_buff。这个结构是一种UAPI(user space API of the kernel),允许访问内核中socket buffer内部数据结构中的某些字段。它具有与 struct xdp_md 相同意义两个指针,data和data_end,同时还有更多信息可以获取,这是因为在TC层面上,内核已经解析了数据包以提取与协议相关的元数据,因此传递给BPF程序的上下文信息更加丰富。结构 __sk_buff 的整个声明如下所说,可以在 include/uapi/linux/bpf.h 文件中看到,下面是结构体的定义,比XDP的要多出很多信息,这就是为什么说TC层的吞吐量要比XDP小了,因为实例化一堆信息需要很大的cost。
/* user accessible mirror of in-kernel sk_buff.
* new fields can only be added to the end of this structure
*/
struct __sk_buff {
__u32 len;
__u32 pkt_type;
__u32 mark;
__u32 queue_mapping;
__u32 protocol;
__u32 vlan_present;
__u32 vlan_tci;
__u32 vlan_proto;
__u32 priority;
__u32 ingress_ifindex;
__u32 ifindex;
__u32 tc_index;
__u32 cb[5];
__u32 hash;
__u32 tc_classid;
__u32 data;
__u32 data_end;
__u32 napi_id;
/* Accessed by BPF_PROG_TYPE_sk_skb types from here to ... */
__u32 family;
__u32 remote_ip4; /* Stored in network byte order */
__u32 local_ip4; /* Stored in network byte order */
__u32 remote_ip6[4]; /* Stored in network byte order */
__u32 local_ip6[4]; /* Stored in network byte order */
__u32 remote_port; /* Stored in network byte order */
__u32 local_port; /* stored in host byte order */
/* ... here. */
__u32 data_meta;
__bpf_md_ptr(struct bpf_flow_keys *, flow_keys);
__u64 tstamp;
__u32 wire_len;
__u32 gso_segs;
__bpf_md_ptr(struct bpf_sock *, sk);
};TC输出参数
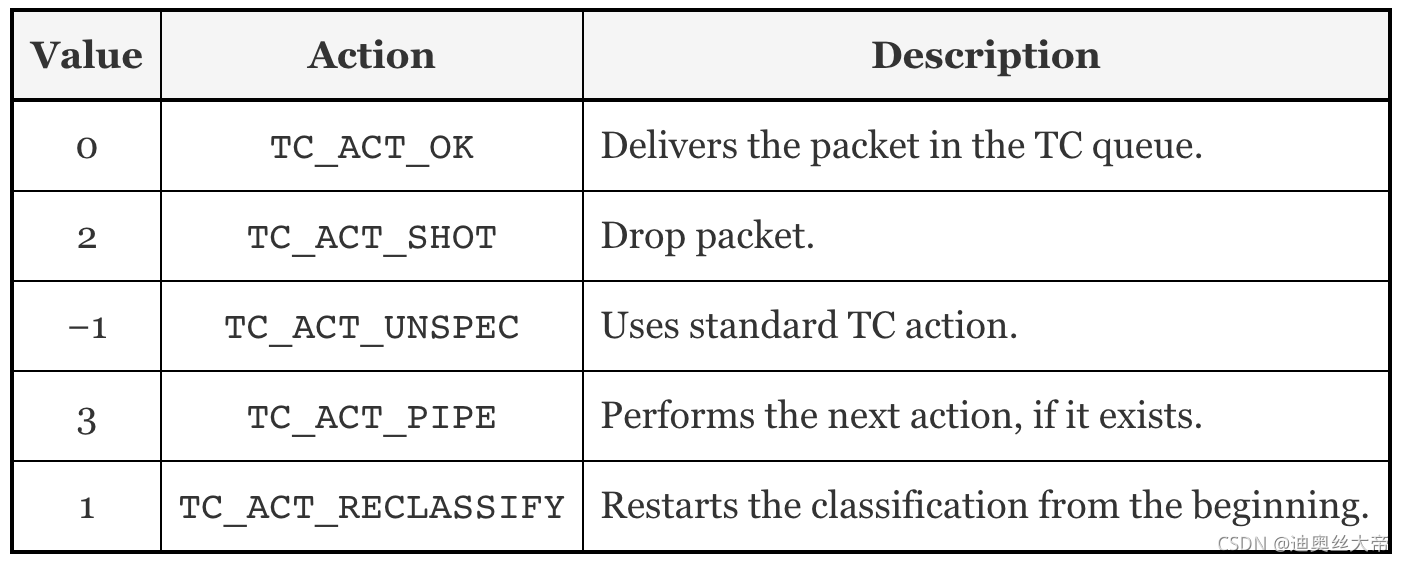
和XDP一样,TC的输出代表了数据包如何被处置的一种动作。它的定义在include/uapi/linux/pkt_cls.h找到。最新的内核版本里定义了9种动作,其本质是int类型的值,以下是5种常用动作:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









