






介绍
1. HAProxy
HAProxy提供高可用性、负载均衡以及基于TCP和HTTP应用的代理,支持虚拟主机,它是免费、快速并且可靠的一种解决方案。HAProxy特别适用于那些负载特大的web站点,这些站点通常又需要会话保持或七层处理(mode : http or tcp )。HAProxy运行在时下的硬件上,完全可以支持数以万计的并发连接。并且它的运行模式使得它可以很简单安全的整合进当前的架构中, 同时可以保护web服务器不被暴露到网络上。
2. Keepalived
Keepalived 是一个基于VRRP协议来实现的LVS服务高可用方案,可以利用其来避免单点故障。一个LVS服务会有2台服务器运行Keepalived,一台为主服务器(MASTER),一台为备份服务器(BACKUP),但是对外表现为一个虚拟IP,主服务器会发送特定的消息给备份服务器,当备份服务器收不到这个消息的时候,即主服务器宕机的时候,备份服务器就会接管虚拟IP,继续提供服务,从而保证了高可用性。Keepalived是VRRP的完美实现。
3. VRRP协议
在现实的网络环境中,两台需要通信的主机大多数情况下并没有直接的物理连接。对于这样的情况,它们之间路由怎样选择?主机如何选定到达目的主机的下一跳路由,这个问题通常的解决方法有两种:
3.1 在主机上使用动态路由协议(RIP、OSPF等)
3.2 在主机上配置静态路由
很明显,在主机上配置动态路由是非常不切实际的,因为管理、维护成本以及是否支持等诸多问题。配置静态路由就变得十分流行,但路由器(或者说默认网关default gateway)却经常成为单点故障。VRRP的目的就是为了解决静态路由单点故障问题,VRRP通过一竞选(election)协议来动态的将路由任务交给LAN中虚拟路由器中的某台VRRP路由器。
业务场景的瓶颈
keepalived+nginx 搭建
本次需要准备两台虚拟机,和3个ip地址. 两台机器分别担任 master 和backup 的角色
vip | 192.168.182.155 |
master | 192.168.182.150 |
backup | 192.168.182.152 |
说明:Keepalived是服务器一种高性能且轻量级的高可用或热备解决方案,通过VRRP协议(虚拟路由冗余协议)来防止服务器静态路由单点故障的发生,结合Nginx可以实现WEB前端服务的高可用。
1. 基础
A. 用途
故障转移:实现负载均衡中MASTER主机BACKUP主机之间的故障转移和自动切换;
心跳检测:负载均衡定期检查RS服务器的可用性决定是否给其分发请求;
B. VRRP(Vritrual Router Redundancy Protocol)协议:是一种容错协议,为了解决静态路由的单点故障;是通过一种竞选协议机制来将路由任务交给某台VRRP路由器,通过优先级来确定MASTER和BACKUP;保证当主机的下一条路由器出现故障时,由另一台路由器来替代出现故障的路由器进行工作,从而保证网络通信的连续性和可靠性,而且自身使用了加密协议;
C. 故障切换转移原理:在Keepalived正常工作时,MASTER节点会不断的向BACKUP节点发送心跳消息,用来告诉BACKUP节点自己还活着,当MASTER节点发生故障时,BACKUP节点就无法继续检测到MASTER节点的心跳,进而调用自身的接管程序,接管MASTER节点的IP资源和服务,当MASTER节点恢复故障时,BACKUP节点会释放MASTER节点故障时自身接管的IP资源和服务,恢复到原来的自身的备用角色;
D. 工作方式分类
抢占式(默认模式):MASTER以组播方式不断的向虚拟路由器组内发送自己的心跳报文,一旦BACKUP在设定时间内没有收到心跳信息的次数超过了限定次数,则会将MASTER的所有权转移到优先级最高的BACKUP;
非抢占模式:指只有在主节点完全故障时才能将BACKUP变为MASTER
2.Keepalived搭建(150和152都需执行以下操作)
本次是为了,使用配置 ,安装采用的yum 方式简单.生产中可以自行替换成源码包安装.
1.安装keepalived:yum -y install keepalived
修改配置,指定vip和网卡
master 150 :
vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id server1 #需要改,设备的id号,可以随意写,单主备不能一样
}
vrrp_script check_ngx {
# script "killall -0 nginx"
script "/etc/keepalived/nginx_check.sh"
interval 1 #间隔时间1s检测一次
weight -20
}
vrrp_instance VI_2 {
state MASTER #可能要改,是否是主master,从backup
nopreempt #非抢占模式
interface ens33 #需要改, 写对应主机的网卡
virtual_router_id 66 #不需要修改,主备必须保持一直
priority 105 #可能要改
unicast_src_ip 192.168.182.150#需要改,本设备ip地址
unicast_peer {
192.168.182.152 #需要,对端的ip地址
}
advert_int 1
authentication {
auth_type PASS
auth_pass 2222
}
virtual_ipaddress {
192.168.182.155/24 #需要改,所虚拟出来的vrrp ip
}
track_script {
check_ngx
}
}backup 152 :
vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id server2 #需要改,设备的id号,可以随意写,单主备不能一样
}
vrrp_script check_ngx {
# script "killall -0 nginx"
script "/etc/keepalived/nginx_check.sh"
interval 1 #间隔时间1s检测一次
weight -20
}
vrrp_instance VI_2 {
state BACKUP #可能要改,是否是主master,从backup
nopreempt #非抢占模式
interface ens33 #需要改, 写对应主机的网卡
virtual_router_id 66 #不需要修改,主备必须保持一直
priority 100 #可能要改
unicast_src_ip 192.168.182.152#需要改,本设备ip地址
unicast_peer {
192.168.182.150 #需要,对端的ip地址
}
advert_int 1
authentication {
auth_type PASS
auth_pass 2222
}
virtual_ipaddress {
192.168.182.155/24 #需要改,所虚拟出来的vrrp ip
}
track_script {
check_ngx
}
}
3.Nginx 搭建
自行安装吧,最小化即可,起到测试功能.nginx 安装网上很多,源码包安装也很快.
场景:
keepalived脑裂现象
A. 现象:脑裂指由于某些原因(如网络差、防火墙开启等),导致多台keepalived的服务器在指定时间内无法检测到对方存活心跳信息(事实上服务器还是存活状态),从而导致相互抢占对方的资源和服务所有权的现象;
B. keepalived监控nginx:Nginx宕机会导致用户请求失败,但是keepalived不会进行切换,故需要编写检测nginx是否存活的脚本,shell脚本无固定格式,可以按照场景编写.
书写上面定义好的 检测脚本(这个是简化的,可根据公司场景自行编写)
vim /etc/keepalived/nginx_check.sh
#!/bin/sh
# 判断nginx是否关闭
if [ `ps -C nginx --no-header | wc -l` -eq 0 ];then
#systemctl stop keepalived
pkill keepalived
fi给对应的脚本,赋予执行权限
chmod +x /etc/keepalived/nginx_check.sh
4.启动服务,验证
启动 nginx 服务,(请提前编辑可区分的 index.html ,便于区分转发请求).
启动keepalived:systemctl start keepalived;
5.验证
定义的 vip 地址 是 192.168.182.155 ,端口是默认的80 转发.
可以在浏览器上访问,http://192.168.182.155
也可以在linux 里面访问: curl 192.168.182.155/index.html
停掉 150 上的 nginx 检查 ip 是否跳转到了 152 主机上,并进行访问请求,验证访问内容是否跳转.
haproxy+nginx 搭建
介绍:
这里使用 haproxy 替代 keepalived 进行负载的转发.实现高可用.
场景概述:
这里依旧沿用上个实验分配的角色和主机ip地址.把 keepalived 停掉即可.vip 本次不使用
systemctl stop keepalived.service #el7 停keepalived 服务
systemctl status keepalived.service #查实
1.安装 haporxy (150 和 152 都需要执行以下操作)
采用最简化方式安装,旨在介绍调度功能的使用,生产中建议使用源码包安装.安装方式这里不在记录
yum install haproxy -y
2.HAProxy配置/etc/haproxy/haproxy.cfg
vim /etc/haproxy/haproxy.cfg #默认,建议修改即备份
master 150 主机:
global
#全区日志配置 使用rsyslog的local3设备
log 127.0.0.1 local3 info
#工作目录(安全)
chroot /var/lib/haproxy
#pid文件存储目录
pidfile /var/run/haproxy.pid
#后台进程数量
nbproc 1
#每个进程最大并发数
maxconn 40000
user haproxy
group haproxy
#后台程序模式工作
daemon
defaults
#mode 指定是7层还是4层(tcp or http)
mode http
#后端连接重试次数,超出标识不可用
retries 3
#连接服务器最长等待时间
timeout connect 10s
#客户端发送请求最长等待时间
timeout client 30s
#服务器会复客户端最长等待时间
timeout server 30s
#对后端服务器的检测超时时间
timeout check 10s
#当服务器负载很高的时候,自动结束掉当前队列处理比较久的连接
option abortonclose
#定义HAProxy监控页面
listen admin_stats
bind 0.0.0.0:9188
mode http
log 127.0.0.1 local3 err
#HAProxy监控页面统计自动刷新时间。
stats refresh 30s
#设置监控页面URL路径。 http://IP:9188/haproxy-status可查看
stats uri /haproxy-status
#统计页面密码框提示信息
stats realm welcome login\ Haproxy
#登录统计页面用户和密码
stats auth admin:123456
#隐藏HAProxy版本信息
stats hide-version
#设置TURE后可在监控页面手工启动关闭后端真实服务器
stats admin if TRUE
#定义前端虚拟节点,名称可以自定义,只是一个标识作用,www
frontend www
#监听端口,1.1.1.1:80 | 0.0.0.0:80 | *.80
bind *:8080
mode http
#启用日志记录HTTP请求。
option httplog
#启用后后端服务器可以获得客户端IP
option forwardfor
#客户端和服务器完成一次连接请求后,HAProxy主动关闭TCP链接(优化选项)
option httpclose
#使用全局日志配置
log global
#acl 访问控制列表,和 nginx 的 rewrite 功能类似,html 是自定义的,表示这个规则的标签
acl html url_reg -i \.html$
#判断如果满足 定义的 html acl 访问控制,就转发到后端服务器组, htmppol 集群组上
use_backend htmpool if html
#指定后端服务池(backend定义htmpool)
default_backend htmpool
#定义后端真实服务器(定义后端转发的一个标签,上面default 模块指定)
backend htmpool
mode http
#用于cookie保持环境。(如后端服务器故障,客户端cookie不会刷新,用此来把用户请求强制定向到正常服务器)
option redispatch
#负载均衡很高时,自动结束当前队列处理时间长的连接
option abortonclose
#负载均衡算法
balance roundrobin
#允许向cookie插入SERVERID.下面server可以使用cookie定义,也可以加上 insert indirect nocache ,作用是返回给用户的回复信息最中
cookie SERVERID
#启用HTTP服务状态检测功能 (后端服务器一定要存在此文件,不然haproxy认为其故障),就上面定义校验三次使用的方式
option httpchk GET /index.html
#后端服务设置,web1 ,web2 定义服务器再haporyx 的名称;
server web1 192.168.182.150:80 cookie server1 weight 6 check inter 2000 rise 2 fall 3
server web2 192.168.182.152:80 cookie server2 weight 6 check inter 2000 rise 2 fall 3
backup 152 主机:
global
#全区日志配置 使用rsyslog的local3设备
log 127.0.0.1 local3 info
#工作目录(安全)
chroot /var/lib/haproxy
#pid文件存储目录
pidfile /var/run/haproxy.pid
#后台进程数量
nbproc 1
#每个进程最大并发数
maxconn 40000
user haproxy
group haproxy
#后台程序模式工作
daemon
defaults
#mode 指定是7层还是4层(tcp or http)
mode http
#后端连接重试次数,超出标识不可用
retries 3
#连接服务器最长等待时间
timeout connect 10s
#客户端发送请求最长等待时间
timeout client 30s
#服务器会复客户端最长等待时间
timeout server 30s
#对后端服务器的检测超时时间
timeout check 10s
#当服务器负载很高的时候,自动结束掉当前队列处理比较久的连接
option abortonclose
#定义HAProxy监控页面
listen admin_stats
bind 0.0.0.0:9188
mode http
log 127.0.0.1 local3 err
#HAProxy监控页面统计自动刷新时间。
stats refresh 30s
#设置监控页面URL路径。 http://IP:9188/haproxy-status可查看
stats uri /haproxy-status
#统计页面密码框提示信息
stats realm welcome login\ Haproxy
#登录统计页面用户和密码
stats auth admin:123456
#隐藏HAProxy版本信息
stats hide-version
#设置TURE后可在监控页面手工启动关闭后端真实服务器
stats admin if TRUE
#定义前端虚拟节点,名称可以自定义,只是一个标识作用,www
frontend www
#监听端口,1.1.1.1:80 | 0.0.0.0:80 | *.80
bind *:8080
mode http
#启用日志记录HTTP请求。
option httplog
#启用后后端服务器可以获得客户端IP
option forwardfor
#客户端和服务器完成一次连接请求后,HAProxy主动关闭TCP链接(优化选项)
option httpclose
#使用全局日志配置
log global
#acl 访问控制列表,和 nginx 的 rewrite 功能类似,html 是自定义的,表示这个规则的标签
acl html url_reg -i \.html$
#判断如果满足 定义的 html acl 访问控制,就转发到后端服务器组, htmppol 集群组上
use_backend htmpool if html
#指定后端服务池(backend定义htmpool)
default_backend htmpool
#定义后端真实服务器(定义后端转发的一个标签,上面default 模块指定)
backend htmpool
mode http
#用于cookie保持环境。(如后端服务器故障,客户端cookie不会刷新,用此来把用户请求强制定向到正常服务器)
option redispatch
#负载均衡很高时,自动结束当前队列处理时间长的连接
option abortonclose
#负载均衡算法
balance roundrobin
#允许向cookie插入SERVERID.下面server可以使用cookie定义,也可以加上 insert indirect nocache ,作用是返回给用户的回复信息最中
cookie SERVERID
#启用HTTP服务状态检测功能 (后端服务器一定要存在此文件,不然haproxy认为其故障),就上面定义校验三次使用的方式
option httpchk GET /index.html
#后端服务设置,web1 ,web2 定义服务器再haporyx 的名称;
server web1 192.168.182.150:80 cookie server1 weight 6 check inter 2000 rise 2 fall 3
server web2 192.168.182.152:80 cookie server2 weight 6 check inter 2000 rise 2 fall 3
3.服务的启停
systemctl stop haproxy.service #停 el7
systemctl start haproxy.service #启 el7
systemctl status haproxy.service #查 el7
4.开启日志 (可选项)
(日志如果在主机性能较弱的情况下,最好关闭)
vim /etc/rsyslog.d/haproxy.conf
$ModLoad imudp
$UDPServerRun 514
local3.* /var/log/haproxy
systemctl restart rsyslog
如果没有开启,就在 linux系统日志里查看相应的日志, less /var/log/messages
5.开启防火墙策略(可选)
(一般直接内网访问的,直接就把软放给关掉了,如果有特殊场景在外网暴漏,可按需求放开指定ip和端口)
firewall-cmd --permanent --add-port=80/tcp
firewall-cmd --permanent --add-port=9188/tcp
firewall-cmd --reload
setsebool -P haproxy_connect_any=on
#getsebool -a | grep haproxy 查看
6.haproxy 前端管理页面
http://192.168.182.152:9188/haproxy-status #ip 根据自己实际ip 访问.
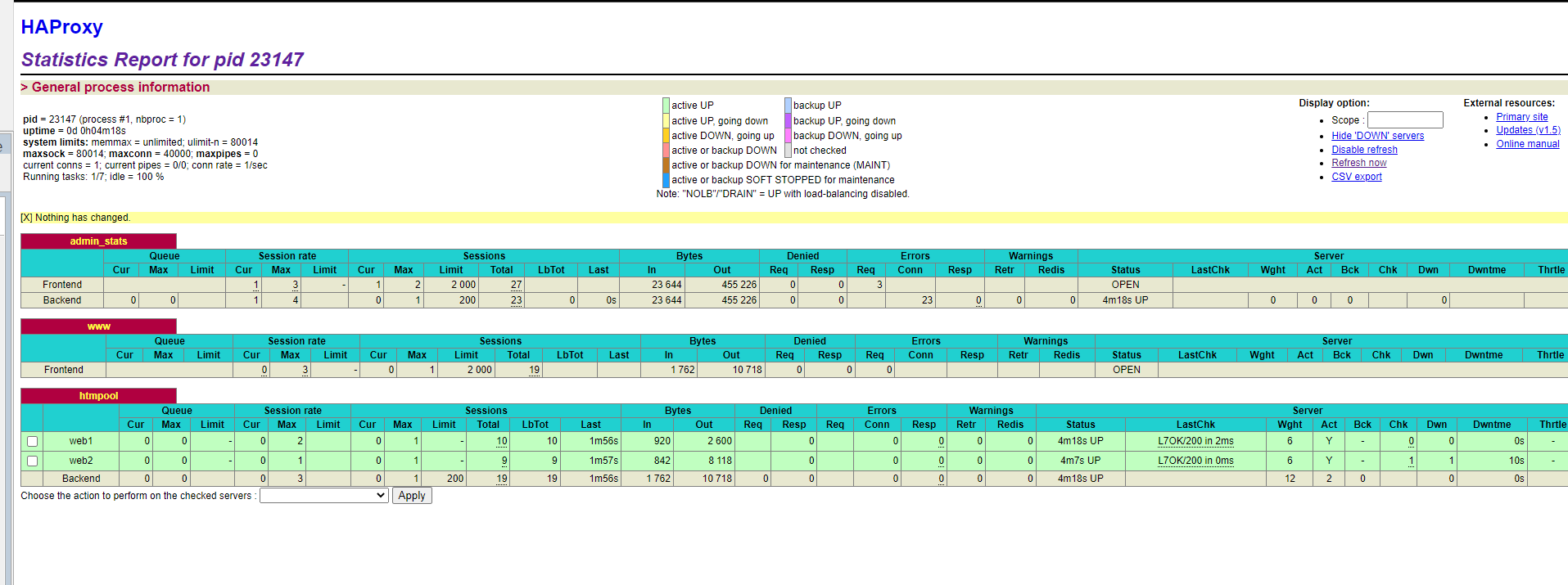
7.验证
watch -n 0.5 'curl 192.168.182.152:8080' #因为这里定义的是监听了 8080 端口
watch -n 0.5 'curl 192.168.182.150:8080'
可以把其中一台的nginx 关掉,看看还能不能访问,跳转是否符合预期.














 690
690











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









