






[例3.13] 为学生-课程数据库中的Student. Course和SC三个表建立索引。其中Student表按学号升序建唯一索引,Course表按课程号升序建唯-索引,SC表按学号升序和课程号降序建唯一索引。

在SQL语言中,建立索引使用CREATE INDEX语句,其一般格式为
:
CREATE [UNIQUE] [CLUSTER] INDEX<索引名>
ON<表名>(<列名>[<次序>][ <列名〉[<次序>]]…);
其中,<表名>是要建索引的基本表的名字。索引可以建立在该表的一列或多列上,各列名
之间用逗号分隔。每个<列名>后面还可以用<次序>指定索引值的排列次序,可选ASC (升
序)或DESC (降序),默认值为ASC。
UNIQUE表明此索引的每一个索引值只对应唯一的数据记录。
CLUSTER表示要建立的索引是聚簇索引。

[例3.14] 将SC表的Scno索引名改为Scsno。
对于已经建立的索引,如果需要对其重新命名,可以使用ALTER INDEX语句。其一般格式为
ALTER INDEX <旧索引名> RENAME TO <新索引名>;
发现修改时不可用:
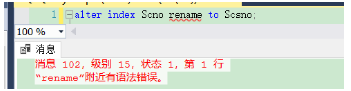
正确运行结果如下:
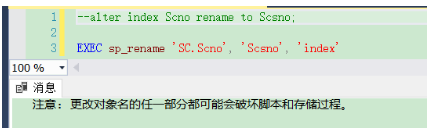
提示内容:更改对象名的任意部分都可能会破坏脚本和存储过程。
成功:

[例3.15 ] 删除Student表的Stusname索引。
删除索引时,系统会同时从数据字典中删去有关该索引的描述。索引一经建立就由系统使用和维护,不需用户干预。建立索引是为了减少査询操作的时间,但如果数据增、删、改频繁,系统会花费许多时间来维护索引,从而降低了査询效率。这时可以删除一些不必要的索引。
在SQL中,删除索引使用DROP INDEX语句,其一般格式为
DROP INDEX <索引名>;

结果为
[例3.69] 将一个新学生元组(学号:201215128,姓名:陈冬,性别:男,所在系:IS,年龄:18岁)插入到Student表中。
在INTO子句中指出了表名Student,并指岀了新增加的元组在哪些属性上要赋值,属性的顺序可以与CREATE TABLE中的顺序不一样。VALUES子句对新元组的各属性赋值,字符串常数要用单引号(英文符号)括起来。
代码如下:

[例3.70] 将学生张成民的信息插入到Student表中。

在INTO子句中只指出了表名,没有指出属性名。这表示新元组要在表的所有属性列上都指定值,属性列的次序与CREATE TABLE中的次序相同。VALUES子句对新元组的各属性列赋值,一定要注意值与属性列要一 一对应,如果像例3.69那样,会因为数据类型不匹配出错。

首先我们来看表的结构

发现关系数据库管理系统将在新插入记录的Grade列上自动地赋空值:
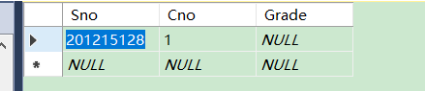
指定对应 表的属性名 代码如下

如果不指定对应属性名,代码如下:

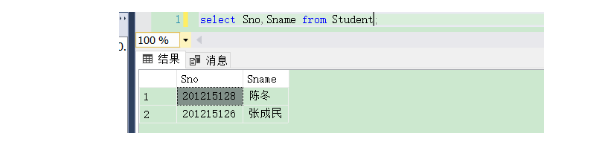
[例3.16]査询全体学生的学号与姓名。

该语句的执行过程可以是这样的:从Student表中取出一个元组,取出该元组在属性
Sno和Sname上的值,形成一个新的元组作为输出。对Student表中的所有元组做相同的处理,最后形成一个结果关系作为输出。
运行结果如下:
[例3.17] 査询全体学生的姓名、学号、所在系。
查询部分列(可以任意顺序查询):

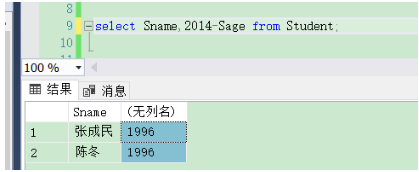
[例3.19] 査询全体学生的姓名及其出生年份。
査询结果中第2列不是列名而是一个计算表达式,是用当时的年份(假设为2014年)减去学生的年龄。这样所得的即是学生的出生年份。输出的结果为:
[例3.27] 査询计算机科学系(CS)、数学系(MA)和信息系(IS)学生的姓名和性别。
结果如下:
代码如下:

[例3.28] 査询既不是计算机科学系、数学系,也不是信息系的学生的姓名和性别。
结果如下:
代码如下
















 404
404











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









