






第一步:在HBase中创建表(表名是wjt:bulkload_1,列族是cf,wjt是命名区间)

第二步:准备测试数据

第三步:上传数据到HDFS

第四步:通过MR计算框架生成HFile文件
命令格式:
HADOOP_CLASSPATH=`$HBASE_HOME/bin/hbase classpath` hadoop jar $HBASE_HOME/lib/hbase-server-version.jar importtsv -Dimporttsv.bulk.output=<输出文件夹路径> -Dimporttsv.separator=<分割符> -Dimporttsv.columns=<key和列映射> <目标表> <数据源路径>
其中 -Dimporttsv.columns=HBASE_ROW_KEY,f:a,f:b的意思是通过'|'分隔符号分割的第一个元素作为rowkey,第二个元素作为f:a列值,第三个元素作为f:b值。
在linux终端输入命令:
HADOOP_CLASSPATH=`/home/bigdata/bigdata/hbase/bin/hbase classpath` hadoop jar /home/bigdata/bigdata/hbase/lib/hbase-server-1.4.10.jar importtsv -Dimporttsv.bulk.output=hdfs://westgis152:8020/wjt/output/bulkload_result_1 -Dimporttsv.separator=',' -Dimporttsv.columns=HBASE_ROW_KEY,cf:letter,cf:number "wjt:bulkload_1" hdfs://westgis152:8020/wjt/input/bulkload_1.txt
注意:hbase-server的jar包版本可以去hbase下的lib目录查看,Dimporttsv.bulk.output中的bulkload_result_1目录不能存在,Dimporttsv.separator是数据的分隔符,Dimporttsv.columns=HBASE_ROW_KEY表示以数据的第一列作为行键(这里行键是rowkey-1、rowkey-2、rowkey-3、rowkey_4),cf:letter表示列族:列,hdfs://westgis152:8020/wjt/input/bulkload_1.txt表示hdfs://主机名:hadoop中的core-site-xml文件中的fs.defaultFS端口号/文件在hdfs上的路径

执行过程中没报错即执行成功,查看输出文件的内容

第五步:加载HFile文件到集群(表)
生成的HFile必须尽快的去load到表中,在第一个步骤中HFile生成的规则是一个region一个文件,如果不尽快加载一旦线上的region发生分裂就会造成加载的性能下降。
命令格式:
HADOOP_CLASSPATH=`$HBASE_HOME/bin/hbase classpath` hadoop jar $HBASE_HOME/lib/hbase-server-version.jar completebulkload <生成的HFile路径> <目标表名称>
在Linux终端输入命令:
HADOOP_CLASSPATH=`$HBASE_HOME/bin/hbase classpath` hadoop jar $HBASE_HOME/lib/hbase-server-1.4.10.jar completebulkload hdfs://westgis152:/wjt/output/bulkload_result_1 "wjt:bulkload_1"
![]()
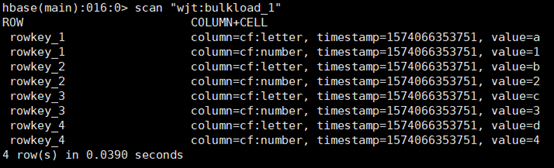
第六步:查看数据是否导入hbase















 3618
3618











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









